

Kataloge waren bereits in der Antike populär. In seinem Epos Ilias widmet der griechische Dichter Homer mehr als 200 Verse der Beschreibung der gemeinsamen Flotte, die sich anschickte, Troja zu unterwerfen. Er ordnet die Geschwader nach der Herkunftsregion, benennt deren Anführer und die Anzahl der Schiffe.
Damit wird bereits der Kern eines Kataloges deutlich. „Objekte“ werden dort aufgezählt, geordnet und kategorisiert und durch weitere Informationen ergänzt. Womit wir schon beim Thema Metadaten wären, aber dazu später mehr.
Daten, Daten, Daten
Wir verlassen das Mittelmeer aber bleiben bei Wasser im weitesten Sinne. Heute setzen viele Unternehmen einen Data Lake ein, und sammeln dort allerlei Daten. Dies umfasst zum einen strukturierte Daten aus ERP- und CRM-Systemen, aber auch semi- und unstrukturierte Daten, wie z. B. Webseiteninteraktionen, Social-Media-Beiträge oder Bilder und Videos. In diesem Sammelbecken fließen Informationen aus unterschiedlichen Unternehmensbereichen zusammen und es wird zunehmend schwieriger, einen Überblick über die Daten zu behalten. Wichtig sind in diesem Zusammenhang unter anderem die Herkunft und die Verwendung der Daten, die Qualität und Aktualität, sowie die Kategorie.
Daten zählen zu den wertvollsten Assets des Unternehmens überhaupt und können in ihrer Funktion als wirtschaftliches Gut gewinnbringend eingesetzt werden. Im Rahmen der Kundenbindung und der entsprechenden Customer Experience können Daten eingesetzt werden, um den Kunden passgenaue Vorschläge zu liefern. Dienstleister wie Netflix oder der Versandhändler Amazon sind in der Lage, anhand des Kundenverhaltenes, welches sie gespeichert haben, solche Empfehlungen zu generieren. Ein weiterer Use Case ist die effizientere Nutzung von Unternehmensressourcen, z. B. durch den Aufbau von Predictive Maintainance um Wartungs- und Reparaturkosten zu senken bzw. Ausfallzeiten in der Produktion zu minimieren. (Mehr dazu siehe in folgendem Beitrag) .
Der Einsatz von Datenanalyse und die Bereitstellung von Daten können auch im Rahmen der Umsetzung von Sustainability-Zielen eingesetzt werden, um beispielsweise Food Waste zu reduzieren, indem die Logistik und Lagerung von Lebensmitteln optimiert und besser an die Bedarfe angepasst wird.
Die Vorteile und Anwendungsfälle für die Verwendung von Daten für die Analyse, zur Vorhersage oder zur Unterstützung der Entscheidungsfindung liegen auf der Hand, aber laut einer Studie von Forrester werden zwischen 60% – 73% nicht für analytische Zwecke genutzt (Link). Hier kann ein Data Catalog einen wesentlichen Beitrag leisten, damit Unternehmen eine bessere Transparenz über die zur Verfügung stehenden Daten erhalten und die Nutzung erhöhen können.
Ich suche nicht — ich finde
Eine Umfrage unter amerikanischen Unternehmen mit mehr als 1.000 Mitarbeitern ergab, dass im Durchschnitt 400 Datenquellen in Unternehmen für Analysen und Reports genutzt werden. 20 % der befragten Unternehmen nutzen sogar mehr als 1.000 Datenquellen (Link).
Dies ist eine unglaubliche Menge, die sich durch die Tatsache, dass aus einer Quelle mehrere Datensets mit einer beliebigen Anzahl von Attributen stammen können, noch potenziert. Gleichzeitig zur wachsenden Menge an Datenquellen und Daten steigt bei Organisationen der Bedarf nach Self-Service-Analysen und Reports. In Zeiten, in denen man auf äußere Einflüsse immer schneller reagieren muss, ist die Notwendigkeit der schnellen Informationsbeschaffung und deren Aufbereitung entscheidend für den unternehmerischen Erfolg. Gerade Fachbereiche stehen daher oft vor dem Problem, dass die Herkunft und Qualität der Daten unbekannt sind, und auch der Ansprechpartner bzw. Owner der Daten ist nicht ersichtlich.
In diesem Umfeld kann ein Datenkatalog einen wesentlichen Beitrag leisten, indem er zwei wesentliche Dinge tut:
- Automatisierte Inventarisierung und Kategorisierung
Durch eine einfache Anbindung an die bestehende Infrastruktur unter Verwendung von Standard-Connectoren können Data-Catalog-Lösungen eine automatisierte Inventarisierung von On-Prem- und Cloud-Datenquellen vornehmen. Die Inventarisierung erfolgt zunächst initial und dann im Betrieb regelmäßig, um die Aktualität der Informationen zu gewährleisten. Ein Data Profiling erfolgt automatisiert, so werden z. B. Anzahl der Datensätze und Datentypen erkannt. Darüber hinaus können regelgestützt bestimmte Kategorien bzw. Klassifizierungen zugeordnet werden, z. B. die Kennzeichnung von Kreditkartennummern als personenbezogene Daten. Besonders fortschrittliche Lösungen nutzen KI-gestützte Verfahren und Algorithmen, um die Klassifizierung vorzunehmen und damit die Notwendigkeit für manuelle Eingriffe zu minimieren. Das Ergebnis sind „Metadaten“, also Daten über Daten. Diese erweitern die gespeicherten Informationen um weitere Attribute. Sehr nützlich ist diese Funktion beispielsweise, um automatisiert personenbezogene Daten zu kennzeichnen. - Zugängliche und zugleich mächtige Suchfunktion
Für die Konsumenten von Daten spielt die Suche eine zentrale Rolle. Die Suchfunktion muss möglichst einfach sein und sollte neben den reinen Daten auch andere Inhalte, wie z. B. ein Glossar umfassen. Die Ergebnisse der Suche werden übersichtlich dargestellt und die Reihenfolge, in der die Ergebnisse präsentiert werden, berücksichtigt allerlei Faktoren, um ein entsprechendes Ranking zu errechnen. In diese Faktoren kann auch „Wisdom of the Crowd“ mit einfließen, also Kommentare, Bemerkungen und Bewertungen anderer Benutzer. Mittels der Attribute aus Metadaten und Klassifizierungen lassen sich Suchergebnisse weiter filtern und verfeinern.
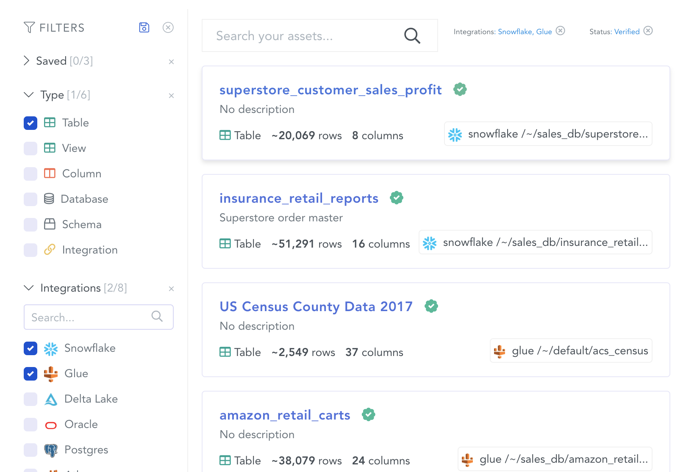
Die wichtigsten Funktionen / Features
- Konnektoren / Anbindung der Datenquellen
Die Inventarisierung aller Datenquellen ist einer der wichtigsten Anforderungen an einen Data Catalog. Natürlich sollten hier On-Prem- und Cloud-Datenquellen berücksichtigt werden. Der Datenkatalog kann neben den klassischen Quellsystemen auch BI-Lösungen umfassen, z. B. Power-BI-Datasets. Ziel ist der Aufbau einer „Single Source of Trust“ mit möglichst hoher Automatisierung. Je nach Lizenzmodell der Lösung können für das Scannen der Quellen Kosten entstehen, dies sollte in den Überlegungen berücksichtigt werden. - Eine Suchfunktion, welche „multi-faceted“ ist, berücksichtigt neben einer reinen Stichwortsuche auch weiterführende Filter- und Suchmöglichkeiten.
- Data Lineage ist die meist grafische Repräsentation zur Visualisierung der Datenherkunft und der Datenverwendung. Dies ist durchaus noch eine wichtige Anforderung im Rahmen eines Data Catalogs. Durch den Shift der Paradigmen von ETL und ELT und der Ü„nderung der Architektur in Richtung Data Lake / Lakehouse-Architektur muss dieser Aspekt nicht unbedingt im Fokus der Überlegungen stehen. Hilfreich ist diese Funktion, um z. B. die Herkunft von Daten, die in einem Report angezeigt werden, zu ihrem Quellsystem zurückzuverfolgen und beispielweise bei Qualität- oder Aktualitätsproblemen reagieren zu können. Außerdem spielt das Thema Datenschutz ggf. eine Rolle.
- Kategorisierung
Hier setzen viele Hersteller auf Regelwerke und AI. Hier hat beispielsweise der Software-Hersteller Microsoft ein umfangreiches Werk und Definitionen geschaffen, um alle möglichen Informationstypen, besonders wenn es um Informationen sensibler Natur geht, zu identifizieren. Mehr Informationen sind unter folgendem Link zu finden. Für die Erkennung einer Kreditkartennummer wird ein entsprechendes Muster geprüft, Feldnamen (in mehreren Sprachen) gematcht und eine Prüfsumme gecheckt.
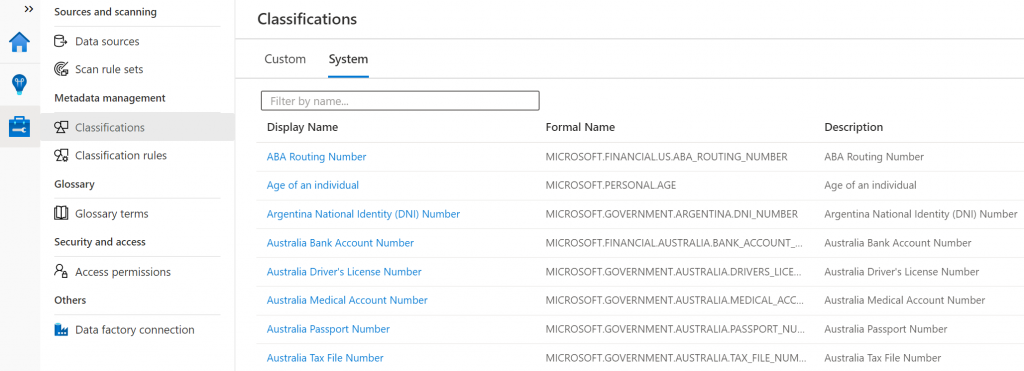
- Data Quality
Die Datenqualität ist in jedem Data-Projekt der maßgebliche Faktor. Stimmen die Daten nicht, dann können die errechneten Kennzahlen zu fehlerhaften Entscheidungen führen. Aufgabe eines Data Catalogs ist jedoch nicht die Sicherstellung der Datenqualität. Die Daten sollten dort qualitätsgesichert werden, wo es sinnvoll ist. Dies ist meist am Anfang des Prozesses der Fall, da dort auch der Aufwand für die Korrektur am geringsten ist.
- Weitere Features eines Data Catalogs:
- Unterstützung von Collaboration, um Notizen, Bewertungen, Kommentare und manuelle Klassifizierungen vernehmen zu können
- Modelle auf Business-Ebene, um Geschäftsprozesse und die zugehörigen Daten darstellen zu können
- Glossar zur Klärung von Begrifflichkeiten und Regeln
Data Catalog als Bestandteil einer ganzheitlichen Data Governance
„Data Governance ist eine Ansammlung von Prozessen, Rollen, Richtlinien, Standards und Kennzahlen, die eine effektive Nutzung von Informationen ermöglichen und Organisationen bei der Umsetzung ihrer Ziele unterstützen.“ (Definition von Talend)
Der Data Catalog ist ein Bestandteil der Data Governance und operationalisiert bestimmte Aspekte. Wie bereits angesprochen, ist die Aufgabe eines Data Catalogs nicht, die Datenqualität sicherzustellen. Im Katalog sollte lediglich die Güte der Qualität angezeigt werden. Für den Anwender sollte ersichtlich und nachvollziehbar sein, was die Einordnung in eine Qualitätsstufe bedeutet.
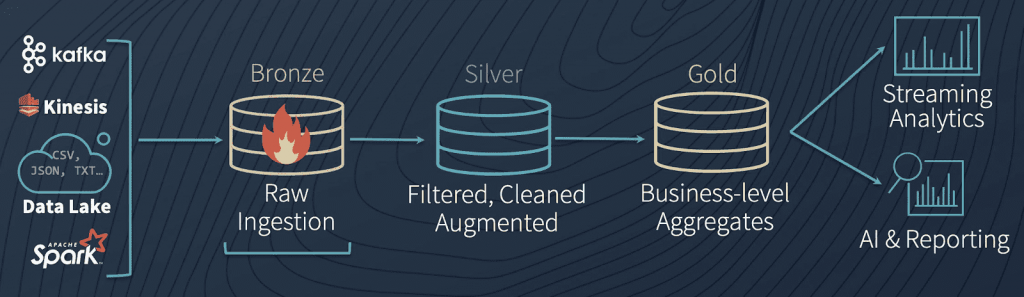
Gleiches gilt für Data Compliance. Die Einhaltung der Vorgaben aus Gesetzen und regulatorischen Anforderungen ist ein komplexes Thema und kann regional unterschiedlich sein. Schützenswerte personenbezogene oder personenidentifizierbare Daten können in einem Data Catalog entsprechend gekennzeichnet werden, um die Verwender der Daten dafür zu sensibilisieren.
Open Data als prominentes Beispiel für Data Catalogs
Hinter Open Data verbirgt sich die Idee, Daten frei zugänglich zu machen und eine Nutzung ohne Einschränkungen zu erlauben. Zu den Produzenten dieser Daten zählen vor allem staatliche Stellen und Organisationen. Um auch in diesem Zusammenhang die Organisation und Auffindbarkeit der Daten zu gewährleisten, werden die Daten über einen Data Catalog bereitgestellt. Eine weit verbreitete Lösung aus der Open Source Community ist CKAN. Zu den Verwendern zählen z. B. die Verwaltungen der USA (data.gov) und Großbritanniens (data.gov.uk). Auch der deutschsprachige Katalog govdata.de wird über CKAN betrieben.

data management system
Diese Software ist frei verfügbar und kann als Einstieg und Spielwiese in das Thema Data Catalog heruntergeladen und installiert werden. Natürlich gibt es auch eine Reihe von kommerziellen Anbietern, die Demo- oder Trial-Versionen anbieten.
Ein weiterer Contributor aus der Open Source Community ist die Apache Software Foundation. Mit Apache Atlas wird ein Meta Data Management bereitgestellt, welches zu einem Data Catalog ausgebaut werden kann und besonders gut mit weiteren Apache Produkten aus dem Data Umfeld interagiert, unter anderem HIVE bzw. Hadoop und Storm/Kafka.
Fazit
Die Menge an Daten, die jeden Tag auf der Welt generiert werden, steigt rasant an. Dazu kommen neue Architekturen und Technologien, um Daten zu speichern und zu verarbeiten, wie z. B. Data Lakes und Streaming Data.
Ein Data Catalog kann ein Hilfsmittel sein, um Organisationen bei der Verwendung und Nutzung der Daten zu unterstützen. Data Scientists verwenden nur einen geringen Teil ihrer täglichen Arbeitszeit darauf, Daten auszuwerten und Modelle zu entwickeln (Link). Stattdessen verbringen sie viel Zeit mit dem Suchen und Organisieren von Daten. Ein Data Catalog kann dazu beitragen, dass diese Zeiten sinnvoller genutzt werden. Aus Daten können neue Business Cases entstehen und bestehende Prozesse deutlich verbessert werden.
Mittels Automatisierung und KI können Data Catalogs mit wenig manuellem Aufwand befüllt und aktuell gehalten werden, menschlicher Input erhöht die Qualität des Data Catalogs. Im Zentrum der Nutzung und des Mehrwerts steht die Suchfunktion.
Als Bestandteil und als Instrument einer Data-Governance-Strategie kann ein Data Catalog dazu beitragen, die Strategie im Unternehmen umzusetzen.
Open Source Software ist eine Möglichkeit, sich dem Thema von technischer Seite her zu nähern. Kommerzielle Anbieter bieten oft die Möglichkeit, ihre Produkte in Trial- und Demo-Versionen besser kennenzulernen.


