

Früher war alles besser? Für Analytics-Projekte gilt das sicherlich nicht. Mit modernen Auswertungstools, Künstlicher Intelligenz und vielen neuen Möglichkeiten der Datenspeicherung und Verarbeitung in der Cloud, sprich Modern Cloud Analytics, stehen uns heute mehr Möglichkeiten offen als je zuvor. Doch eines kann man wahrscheinlich schon sagen: Früher war vieles einfacher. Denn um diese neuen Möglichkeiten voll ausschöpfen zu können, greifen viele Rädchen ineinander. Daten aus verschiedensten Quellen und in unterschiedlicher Form werden gesammelt, aufbereitet, mit Hilfe von Machine Learning angereichert und analysiert – und für jeden dieser Schritte gibt es die unterschiedlichsten Lösungsansätze und die jeweiligen Expert:innen. Oft wird die Komplexität, die hierdurch entsteht, unterschätzt. Im schlimmsten Fall wird jeder Schritt von einem anderen Bereich übernommen – und alle kochen ihr eigenes Süppchen. Das führt dann dazu, dass Daten redundant vorliegen, Machine-Learning-Algorithmen ihr Potenzial nicht ausschöpfen können, die Ergebnisse den Weg ins Reporting nicht finden und vieles mehr …
Unsere Firmen-Communitys „Data Integration“ und „Next Level Analytics“ wollten einen Weg finden, diese komplexen Prozesse unter einen Hut zu bringen. Dafür haben wir uns neben unserer täglichen Arbeit ein aktuelles Thema vorgenommen: die Landtagswahlen in NRW. An den Namen der Communitys erkennt man wahrscheinlich bereits die erste Herausforderung: Hier hatten sich Expert:innen aus unterschiedlichen Bereichen versammelt. Die erste Maßnahme war also, die richtigen Personen an einen Tisch zu bekommen und einen Schlachtplan zu entwickeln.
*Teil 1 aus dem Tagebuch unseres Community Projekts zur NRW-Wahl 2022
Was wir herausfinden wollten
Die Grundidee „wir machen was rund um die Wahl“ stand schnell fest. Doch was wollten wir eigentlich herausfinden? Nach einem gemeinsamen Brainstorming entschieden wir uns für Predictive Analytics, d. h., wir wollten versuchen, die Wahlergebnisse vorherzusehen. Eine solche Prognose wäre ja nicht nur für uns als Außenstehende spannend, sondern gerade für die Parteien sehr wertvoll. Und vielleicht wäre es ja sogar möglich, die Ergebnisse auch auf weitere Wahlen zu übertragen.
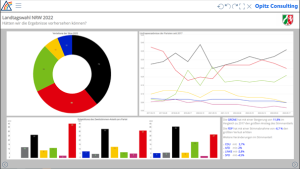
Die von uns genutzten Daten
Um unseren Plan umzusetzen, fehlte uns allerdings noch etwas sehr Wichtiges: Die Daten.
Also bestand unsere erste Aufgabe darin, Datenquellen zu suchen, die uns weiterbringen. Wir überlegten, welche Quellen uns frei zur Verfügung stehen. Natürlich gibt es Umfrageergebnisse, die konnten wir zu Analysezwecken per Excel-Dateien nutzen. Auch hatten wir die Ergebnisse der letzten Wahlen und letztendlich auch die der aktuellen NRW-Wahl – denn das Projekt lief über das Ende der Wahlperiode hinaus. Es fehlten aber noch Daten, die unsere Grundlage für den Forecast bilden sollte. Am besten geeignet wären hierfür natürlich die Meinungen der Wähler. Wenn wir diese herausfinden könnten, ließe sich doch sicher eine Vorhersage über den Ausgang der Wahl treffen.
Die meisten sozialen Netzwerke, standen uns leider nicht zur Verfügung. Twitter hingegen lässt sich relativ leichtgewichtig abgreifen und mit dessen API konnten wir bereits in anderen Projekten Erfahrungen sammeln. Die Entscheidung war gefallen: Wir würden die Tweets zur Landtagswahl sammeln und nutzen.
In Twitterbeiträgen verstecken sich viele spannende Informationen. Neben Texten und Hashtags sind auch die Metadaten von Tweet und User sehr aufschlussreich. Durch die Anzahl der Likes, Retweets, Replies und Follower erfährt man einiges über die Reichweite der Inhalte. Auch die User-Namen sind in diesem Beispiel aussagekräftig, da man über sie die Spitzenkandidaten der Parteien identifizieren kann. Die Orte der User werden auch noch eine Rolle spielen, aber hierzu später mehr.
Wie es unter der Motorhaube aussah …
Die Quellen waren also festgelegt. Nun ging es an die Architektur. Die Daten sollten schließlich verarbeitet und abgelegt werden. Die technischen Details reiße ich in diesem in diesem Beitrag nur ganz kurz an. Denn dazu gibt es in den nächsten Teilen dieser Blogreihe mehr zu lesen. Aber so viel sei verraten: Wir entschieden uns dafür, vollständig in der Azure Cloud zu arbeiten. Hier lassen sich schnell die benötigten Systeme, Datenbanken und Ressourcen zur Verfügung stellen und verbinden. Für die Datenspeicherung haben wir eine Snowflake-Datenbank ausgewählt.
Grob gesehen waren dies die nächsten Schritte:
- Mit Hilfe von Apache Nifi griffen wir die Tweets ab und schrieben sie in den Data Lake Storage unseres Staging Layers. Nifi ermöglicht uns hierbei einen Echtzeit-Transfer der Daten, d.h. sobald ein Tweet neu erstellt wird, schreiben wir ihn in unser System.
- Von dort aus wurden die Daten mit Airbyte aus dem Data Lake Storage in unsere Snowflake Datenbank geschrieben, durch dbt Transformationen aufbereitet und in einem Core-Layer * persistiert. Die beiden Open Source Tools Airbyte und dbt stellen gerade in Kombination eine gute Alternative zu kommerziellen Tools dar.
- Die Daten wurden dann mit Azure Machine Learning weiter analysiert und angereichert.
- Den Data Mart** befüllten wir mit Hilfe von ETL-Strecken in Pyramid – auch hier hätten wir dbt verwenden können, wir wollten aber im Zuge des Projekts evaluieren, was uns die breit aufgestellte Decision Intelligence Plattform von Pyramid Analytics alles zu bieten hat. Auch die Visualisierungen wurden dort erstellt.
Allen, die es selbst noch nicht erlebt haben, wird spätestens, wenn sie unsere Architekturgrafik sehen, klar werden, wie komplex und vielschichtig Analytics-Themen sind – und ich hatte es ja schon angedeutet: Es werden viele unterschiedliche Skills benötigt.
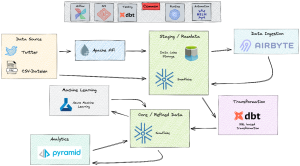
*Der Core-Layer stellt die zentrale Datenhaltungsschicht eines Data Warehouse dar. Hier werden die Daten strukturiert und persistent abgelegt.
** Der Data Mart Layer beinhaltet Informationen, die für fachliche Fragestellung optimiert wurden und in Auswertungen verwendet werden können.
Wie unser Team zusammengesetzt war
In den seltensten Fällen werden derart vielfältige Skills von einer einzelnen Person abgebildet. Auch in unserem Fall gab es Spezialist:innen für die unterschiedlichen Themen. Damit die Abstimmung untereinander leichter wurde, haben wir das ganze Team in mehrere Subteams unterteilt.

- Das Datenaufbereitungs-Team kümmerte sich um die Datensammlung und Aufbereitung bis in den Core Layer. Es zapfte die API von Twitter an und persistierte die Daten in der Snowflake Datenbank. So kamen mit der Zeit Tausende von Tweets zusammen, die weiterverarbeitet werden konnten.
- Auf dieser Basis baute dann das Textanalyse-Team auf. Es brachte die Texte mit Hilfe von Preprocessing in eine analysierbare Form und generierte auf dieser Basis alle möglichen Insights.
- Das Forecast-Team wiederum verwendete die Ergebnisse der beiden zuvor genannten Teams für die Wahlprognosen.
- Dem Visualiserungsteam kam dann die Aufgabe zu, alle Ergebnisse mit den weiteren Quellen zu verknüpfen und in einem Data Mart abzulegen. Auf den so aufbereiteten Daten konnte es dann interaktive Dashboards erstellen.
In diesem Projekt haben wir wieder einmal erfahren, wie wichtig es ist, dass alle Beteiligten Hand in Hand arbeiten. Häufig wird nur das Endergebnis gesehen und die Arbeit, die auf dem Weg dorthin anfällt, geht unter. Auf diesem Weg muss jedes Team darauf bauen, dass das vorherige Team die Daten so vorbereitet, dass sie im weiteren Verlauf verwendet werden können. Jeder einzelne Baustein in diesem Prozess ist also wichtig, und es besteht eine große Abhängigkeit untereinander. Eine gute Abstimmung ist deshalb Gold wert und kann viel Zeit und Ärger ersparen.
Was wir aus den Daten herausholen konnten
Um aus den Tweets verwertbare Informationen zu generieren, benötigten wir ein wenig Magie … – (natürlich!) in Form von Machine-Learning-Algorithmen:
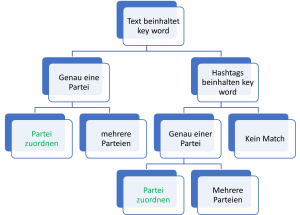
- Texte: Zuerst wurden die Texte auseinandergenommen. Anhand der Usernamen ordneten wir die Parteien zu – denn für uns war es interessant zu wissen, ob der Verfasser des Tweets selbst Kandidat einer Partei war. Leider war das eine relativ manuelle und zeitintensive Aufgabe, denn die Kandidatenlisten inklusive der Benutzernamen bei Twitter mussten erst durch uns erstellt werden.
- Keywords: Mit Hilfe von Keyword Matching untersuchten wir die Texte und Hashtags auf Partei- oder Kandidatennamen, um herauszufinden, um welche Partei es in den Tweets geht. Hier konnte leider häufig keine Partei abgeleitet werden oder es wurden gleich mehrere zugeordnet.
- Ordnung mit Wordclouds: Um einen ersten Überblick über die Grundstimmung zu den jeweiligen Parteien zu erhalten, generierten wir Wordclouds. Dazu wurden die am häufigsten vorkommenden Wörter zu jeder Partei visuell dargestellt. So bekamen wir auf einen Blick ein erstes Gefühl zur Stimmungslage und konnten wichtige Themen identifizieren.

- Ordnung mit Sentiment-Analyse: Ein für das spätere Forecasting wichtiger Schritt war die Sentiment Analyse. Die Tweet-Texte wurden nach positiven, negativen und neutralen Elementen gewichtet. Je nachdem welcher Stimmungsanteil in ihm überwiegt, entscheidet darüber, in welche der drei Kategorien ein Tweet fällt. So kann man die Stimmung des Tweets nicht nur subjektiv wahrnehmen, sondern auch automatisiert verarbeiten und für weitere Auswertungen verwenden.
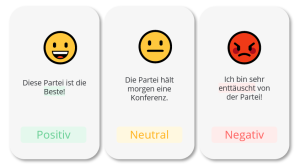
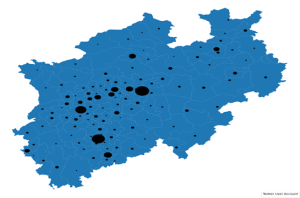
- Vorhersage A: Die so klassifizierten Tweets konnten nun für ein Forecasting genutzt werden. Im ersten Schritt wurde die Wahl-Wahrscheinlichkeit für verschiedene Wahlkreise vorhergesagt. Werden in einem Wahlkreis viele positive Tweets zu einer Partei abgesetzt, dann gehen wir davon aus, dass die Partei dort gute Gewinnchancen hat. Hier kommen nun die Nutzer-Informationen ins Spiel, die wir über diejenigen bekommen, die den Tweet geschrieben haben. Die machten es auch möglich, Tweets zu Wahlkreisen zuzuordnen.
- Vorhersage B: Mit Hilfe der Tweet-Entwicklung über die Zeit wurde dann vorhergesagt, wie sich das Tweet-Verhalten der Nutzer zu einer bestimmten Partei entwickeln könnte. Es wurde eine Stimmungskurve auf Grundlage der vorliegenden Tweets erstellt. Diese konnte dann in die Zukunft fortgeschrieben werden, um Prognosen zum Wahlausgang zu erstellen. Kleiner Spoiler: Das hat nicht so gut funktioniert, wie wir es uns erhofft hatten. Aber hierzu später mehr …
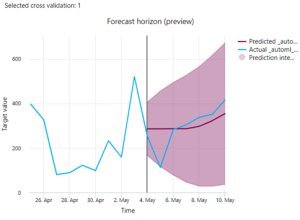
- Visuelle Darstellung: Sämtliche Ergebnisse wurden dann in einem Data Mart zusammengeführt. Mit allen Anreicherungen, die wir gewonnen hatten, entstand daraus ein spannendes, interaktives Dashboard mit vielen Insights rund um die NRW-Landtagswahl.
Unsere Herausforderungen
1. Zeitdruck
Eine unserer größten Herausforderungen war die Zeit – denn alle, die an diesem Projekt mitgewirkt haben, taten dies neben ihrer eigentlichen Arbeit. Da die Ergebnisse der einzelnen Teams voneinander abhängig waren und das nächste Team erst loslegen konnte, wenn das erste Team die Voraussetzungen dafür geschaffen hatte, kam es hier häufig zu Engpässen. Gerade die Forecasting-und Analytics-Themen konnten erst angegangen werden, als die Daten vorlagen und die ersten Ergebnisse der Textanalyse bereitstanden. Die Deadline, die wir uns selbst gesetzt hatten, ließ uns nur wenige Wochen Zeit – denn wir wollten unsere Ergebnisse beim Digital Xchange Bergisches Rheinland vorstellen. Dadurch wurde es dann hinten heraus ordentlich knapp.
Aus der Zeitfalle half uns etwas unser agiles Vorgehen. Das schaffte trotz der kurzen Zeit Raum zum Austausch und ermöglichte schnelle Reaktionen, wenn es beispielsweise unverhoffte Änderungen im Projektablauf gab – und die gab es tatsächlich. Zum Beispiel wurde mitten im Projekt die Twitter-API umgestellt. Die zuvor existierenden Entitäten änderten sich damit komplett, sodass wir die Informationen nun in anderer Form abgreifen mussten. Unsere ETL-Strecken brauchten also ein Upgrade – und wir durften keine Zeit verlieren, um nicht zu viele wertvolle Tweets zu verpassen.
2. Viele Daten, die zu wenig aussagen
Eine weitere Herausforderung brachten die Daten mit sich, die nicht immer hielten, was wir uns von ihnen versprochen hatten. Weiter oben hatte ich bereits beschrieben, wie wir beispielsweise die Tweets bestimmten Parteien zuordnen wollten. Leider gelang uns dies bei vielen Tweets nicht. So hatten wir spannende Tweets mit wertvollen Informationen, die wir für unsere Analysen überhaupt nicht nutzen konnten.
Auch waren unsere Forecasts wenig aussagekräftig, weil Twitter als alleinige Quelle aus unterschiedlichen Gründen nicht ausreichte. So liefert Twitter nur die Stimmungsbilder eines sehr kleinen Teils der Bevölkerung. Unterrepräsentiert waren:
- Die ältere Generation: Unsere Gesellschaft hat ein relativ hohes Durchschnittsalter, doch gerade die ältere Bevölkerungsgruppe nutzt Medien wie Twitter eher selten, um ihre Meinung zu bestimmten Themen kundzutun.
- Bestimmte soziale Schichten: Sogenannte bildungsfernere soziale Schichten, sind auf Twitter zum Beispiel weniger aktiv.
Bei einem „echten“ Projekt sollte also unbedingt Wert auf die Vollständigkeit der Datenquellen gelegt werden. Denn egal wie ausgefeilt die Machine-Learning-Algorithmen auch sein mögen – sie sind immer nur so gut wie die Daten, die ihnen vorliegen.
3. Unzureichende fachliche Analyse
Die letzte Herausforderung, die ich hier erwähnen möchte, war die Zusammenstellung des Dashboards. Wir hatten uns zum Start des Projekts ein grobes Thema überlegt und uns dann schnell auf eine Datenquelle festgelegt. Vom Dashboard selbst hatten wir keine konkrete Vorstellung, deshalb haben wir uns einfach danach gerichtet, welche Daten wir hatten. Für diese Daten suchten wir dann nach einer guten Darstellungsform. Das Dashboard war damit nur auf diese bestimmten Daten zugeschnitten. Man könnte auch sagen, wir haben das Pferd von hinten aufgezäumt.
Ratsamer wäre es gewesen, die fachliche Fragestellung zuvor zu analysieren und sich im Anschluss daran, die Daten zu beschaffen, die dafür nötig sind. Natürlich kriegt man die Lücke nie komplett dicht. Im Verlauf, und wenn die Daten schon vorliegen, werden immer neue Fragestellungen aufkommen – doch der Fokus sollte von Anfang an auf dem fachlichen Problem liegen, als Ausgangspunkt aller Analysen. Ein so konzeptioniertes Dashboard erleichtert den weiteren Prozess ungemein.
Unser Fazit
Trotz oder auch wegen der vielen Herausforderungen haben wir in diesem Community-Projekt viele wertvolle Erkenntnisse gewonnen.
- Komplexe Analytics-Projekte sollten nicht mal eben vom Zaun gebrochen werden. Sie bedürfen einiger Planung und Vorbereitung – und können dennoch Überraschungen bergen.
- Mit einer guten Durchdringung der Fachlichkeit, der Auswahl der richtigen Quelldaten, einem Team, das Hand in Hand arbeitet und ausreichend Flexibilität sind solche Projekte gut handhabbar.
- Eine vorherige Planung der Aufgaben, benötigten Ressourcen und Abhängigkeiten kann dabei helfen, mögliche Probleme vorab zu identifizieren und frühzeitig Lösungen zu finden.
Eine Vorhersage der Wahlergebnisse konnten wir leider nicht treffen – dennoch war das Projekt der OC Communitys für uns ein voller Erfolg. Weil wir nicht nur unser Vorgehen, sondern auch Technologien an einem echten Use Case ausprobieren und dabei unheimlich viel lernen durften.
In unseren nächsten Blogbeiträgen werden wir tiefer in die Technik eintauchen und detailliert auf die Datenintegration, unsere Machine-Learning-Algorithmen und die Arbeit mit Pyramid Analytics eingehen. Außerden werden wir euch natürlich einen Einblick in die von uns gewonnenen Erkenntnisse aus Tweets geben. Es bleibt also spannend!
Alle Blogbeiträge dieser Serie ansehen


