

Databricks ist eine cloudbasierte Datenanalyse- und KI-Plattform, die auf Apache Spark basiert und die Zusammenarbeit zwischen Data-Scientists, Data-Engineers und Analysten erleichtert. Die Plattform vereint Big-Data-Verarbeitung, Machine Learning, Data Warehousing und Business Intelligence in einer zentralen Umgebung. Sie wird als sogenannte Lakehouse-Plattform bezeichnet, da sie die Vorteile von Data Lakes (Flexibilität, niedrige Speicherkosten) und Data Warehouses (hohe Performance, strukturierte Abfragen) kombiniert.
Was bietet dir Databricks konkret?
Die Plattform dient als zentraler Ort für unterschiedliche Data-Workloads, darunter Datenimport, -verarbeitung und -analyse. Sie integriert sich mit den gängigen Cloud-Anbietern AWS, Azure und Google Cloud und unterstützt verschiedene Programmiersprachen wie Python, SQL, Scala und R. Collaborative Notebooks ermöglichen eine cloudbasierte Zusammenarbeit ähnlich wie Jupyter Notebooks, inklusive Versionierung und Kommentaren. Im Bereich Machine Learning bietet Databricks einen vollständigen End-to-End-Prozess für Datenaufbereitung, Modellierung und Deployment und integriert dabei das Open-Source-Framework MLflow.
Ein weiteres zentrales Element ist Delta Lake, das ACID-Transaktionen im Data Lake ermöglicht und Funktionen wie inkrementelle Verarbeitung, Time-Travel und konsistente Abfragen unterstützt. Databricks stellt außerdem Funktionen zur Orchestrierung von Data-Engineering-Pipelines bereit, inklusive Jobs und Workflows, die sowohl Batch- als auch Streaming-Szenarien abdecken. Für Analysten gibt es ein benutzerfreundliches SQL-Interface, das sich auch mit BI-Tools wie Pyramid-Analytics, Power BI und Tableau verbinden lässt. Dank Spark bietet Databricks eine hohe Skalierbarkeit bis hin zu Petabyte-Datenmengen sowie automatische Skalierungsfunktionen.
Für wen ist Databricks besonders geeignet?
Databricks eignet sich für Data-Scientists, die Modelle entwickeln, für Data-Engineers, die komplexe Pipelines aufbauen, sowie für Analysts, die Daten abfragen und visualisieren. Unternehmen profitieren dabei von einer modernen, skalierbaren Datenplattform, die unterschiedlichste analytische Anforderungen in einer Umgebung vereint.
Was ist Delta Live Tables (DLT)?
Delta Live Tables ist eine deklarative Schicht über Apache Spark und Delta Lake, mit der Datenpipelines deutlich einfacher erstellt und verwaltet werden können. Datenregeln, Fehlerbehandlung, Optimierung und Abhängigkeiten werden dabei automatisch verarbeitet. Ziel ist eine robuste, wartbare und gleichzeitig leicht implementierbare Pipeline-Entwicklung.
DLT bietet deklarative Pipeline-Definitionen in SQL oder Python, automatisches Abhängigkeitsmanagement, integrierte Datenqualitätsregeln sowie inkrementelle Verarbeitung. Durch Monitoring- und Auto-Healing-Mechanismen werden Pipelines zuverlässig überwacht und visualisiert. Batch- und Streaming-Verarbeitung werden innerhalb eines einheitlichen Modells unterstützt. Typische Anwendungsfälle sind der Aufbau von Data-Warehouse-Strukturen, Datenbereinigung, Bronze-/Silver-/Gold-Layer-Transformationen sowie zeitgesteuerte oder kontinuierliche Verarbeitung.
Einrichtung Databricks
Die Einrichtung hängt davon ab, ob Databricks über die Community Edition, Azure oder andere Cloud-Anbieter genutzt wird.
- Databricks Community Edition
Die Community Edition eignet sich gut zum Lernen. Nach der Registrierung auf der Databricks-Website kann man direkt ein Notebook erstellen und mit Spark arbeiten. - Databricks auf Azure
Hierzu sind ein Azure-Konto sowie entsprechende Berechtigungen notwendig. Im Azure-Portal wird eine Databricks-Ressource erstellt und anschließend ein Workspace gestartet. Danach können Cluster erstellt und Notebooks verbunden werden. Anschließend lassen sich Daten laden, transformieren, Machine-Learning-Modelle trainieren oder Dashboards erstellen.
Unser Projekt und die Umsetzung
Allgemeiner Überblick
Im Projekt wurde eine automatisierte Datenpipeline aufgebaut, die Rohdaten im Bronze-Layer importiert, im Silver-Layer weiterverarbeitet und im Gold-Layer final modelliert. Insgesamt wurden fünf CSV-Dateien geladen und in den bekannten Layern Bronze, Silver und Gold verarbeitet. Anschließend wurde zusätzlich die Einbindung in Databricks Workflows untersucht. Der gesamte DLT-Code basiert auf PySpark (Raw-Layer) sowie SQL (Silver- und Gold-Layer). Ziel war ein möglichst generischer 1:1-Import der Dateien im Bronze-Layer.
Bronze-Layer
Für das Laden der Daten kommt der Auto-Loader zum Einsatz, der kontinuierlich im Storage nach neuen Dateien sucht und Streaming-Tabellen befüllt. Die Dateien werden in einem Volume abgelegt, aus dem der Auto-Loader die Daten liest.
 Abbildung 1: Auto-Loader-Konfig
Abbildung 1: Auto-Loader-Konfig
Mithilfe von DLT werden anschließend generische RAW-Streaming-Tabellen erzeugt, wobei Tabellen- und Spaltennamen direkt aus den CSV-Dateien übernommen werden.
 Abbildung 2: DLT
Abbildung 2: DLT
Silver-Layer
Im Silver-Layer erfolgt die weitere Verarbeitung, Formatierung und Strukturierung der Daten sowie die Anpassung der Datentypen. Für jede Tabelle wird ein eigener Codeblock definiert, der Spalten, Datentypen, Kommentare und Bedingungen enthält. Zusätzlich wird ein Constraint auf die Spalte BestellungID definiert, um Zeilen mit NULL-Werten zu entfernen. Auch in diesem Layer entstehen Streaming-Tabellen.
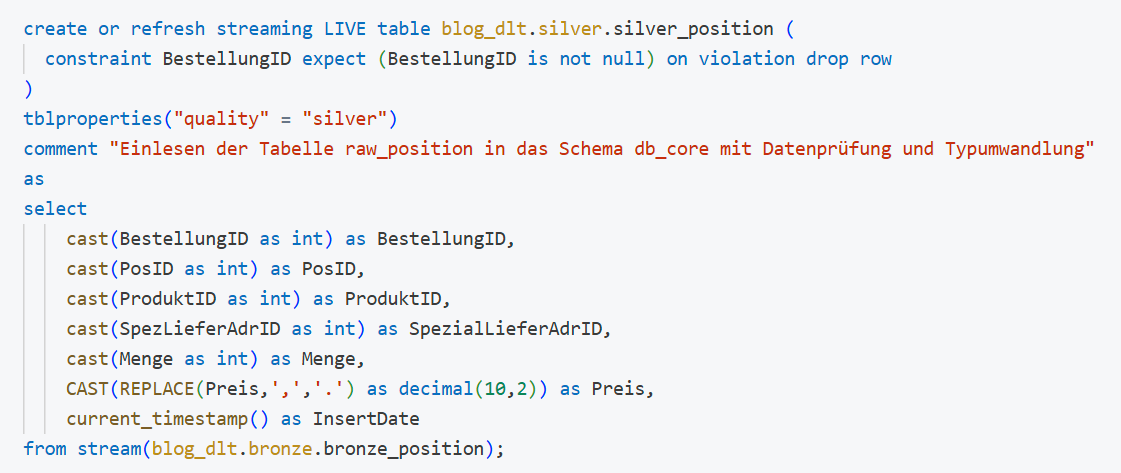
Beispiele für möglichen Constraints:
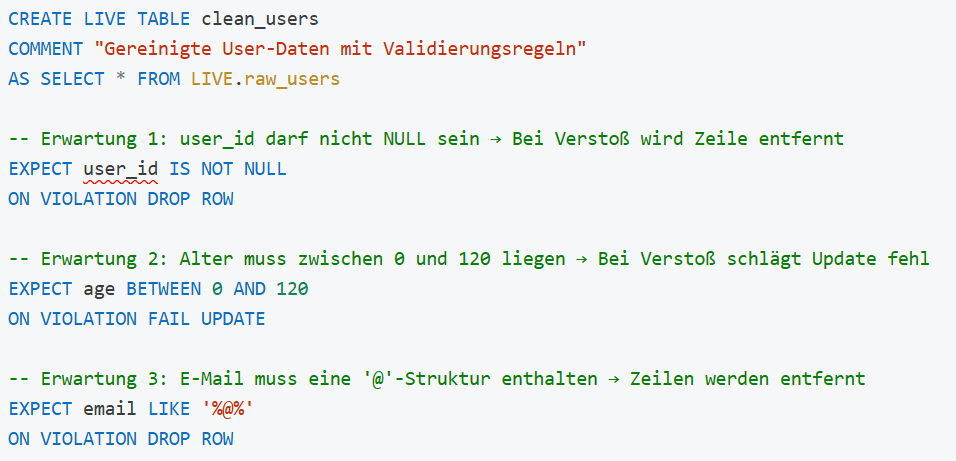 Gold-Layer
Gold-Layer
Im Gold-Layer werden Dimensionstabellen nach SCD2-Logik erstellt. DLT stellt hierfür integrierte Funktionen bereit, die automatisch Versionierung, Zeiträume sowie das Schließen alter Datensätze übernehmen.
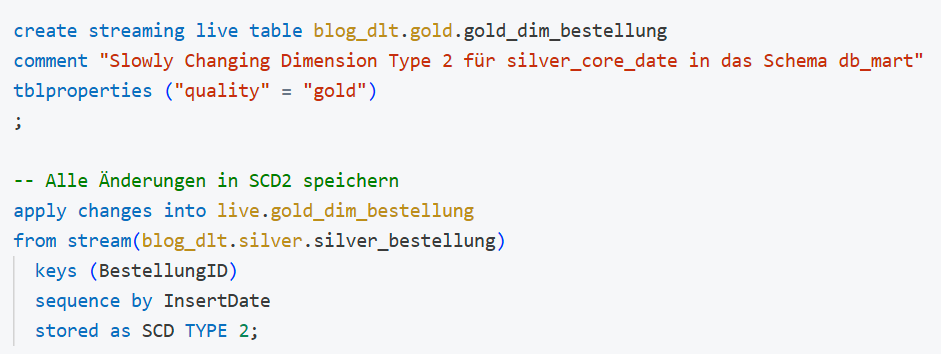 Abbildung 3: Dimension
Abbildung 3: Dimension
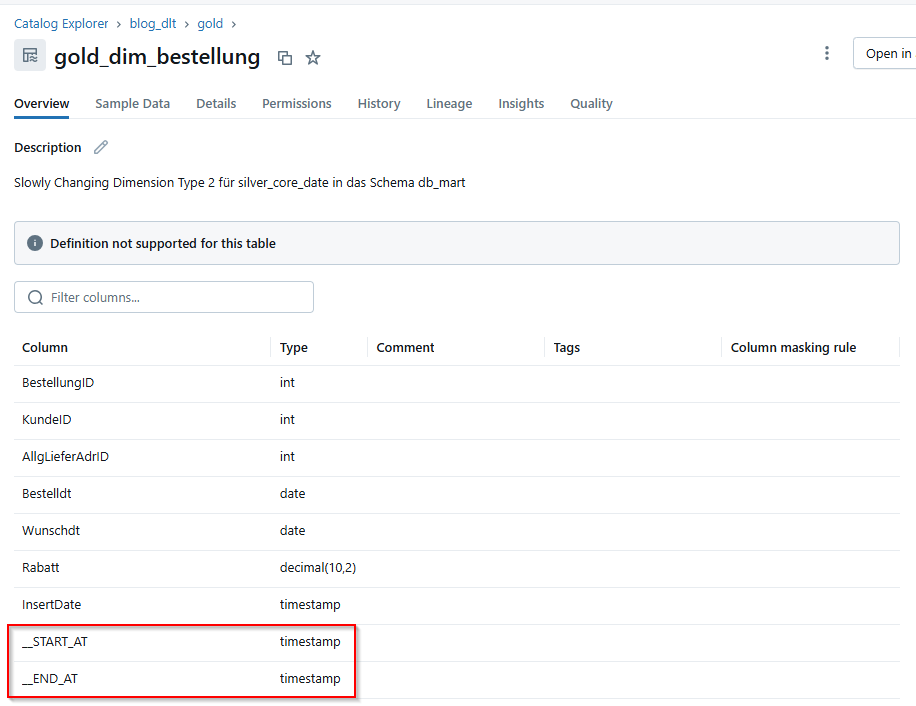 Abbildung 4: SCD2
Abbildung 4: SCD2
Anschließend wird die Faktentabelle generiert, in die die jeweiligen IDs der Dimensionen integriert werden. Damit ist das Star-Schema vollständig aufgebaut.
 Abbildung 5: Fakten
Abbildung 5: Fakten
 Abbildung 6: Star-Modell
Abbildung 6: Star-Modell
Ausführung und Workflows
Um DLT nutzen zu können, wird eine Pipeline erstellt. In ihr werden MatViews definiert, einschließlich Cluster und zugehöriger Notebooks. DLT erkennt dabei automatisch die korrekte Ausführungsreihenfolge. Im Beispiel sind Raw-Layer vom Silver- und Gold-Layer getrennt. Eine Aufsplittung von Silver- und Gold-Layer wäre selbstverständlich ebenfalls möglich.
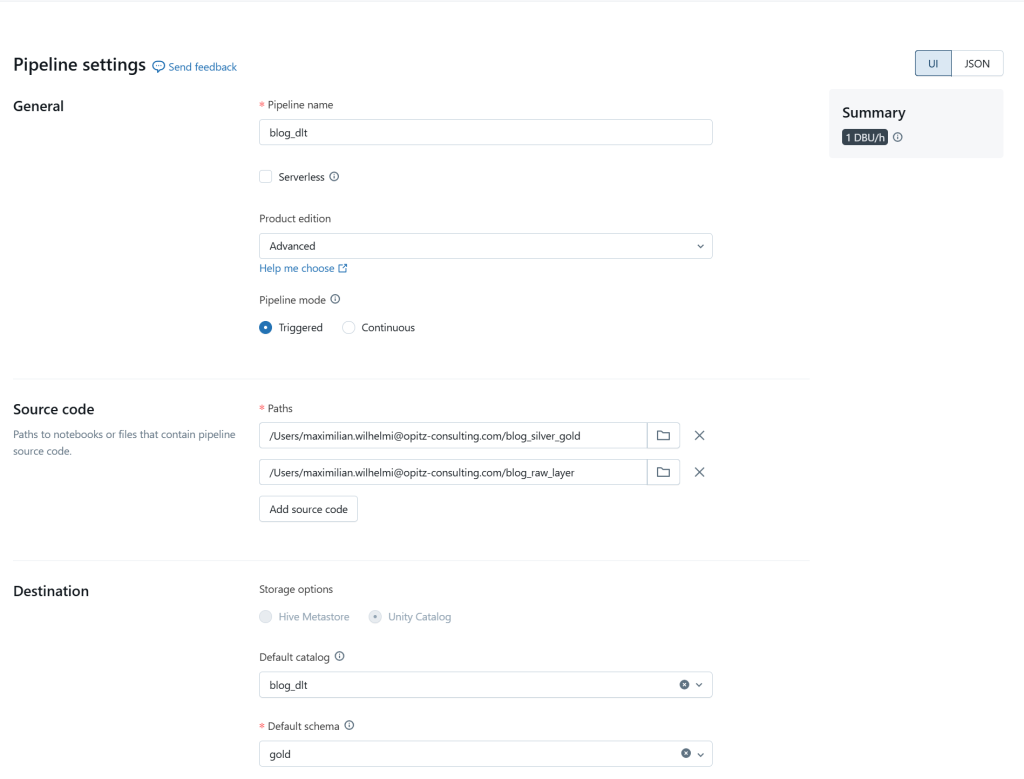 Abbildung 7: Pipeline
Abbildung 7: Pipeline
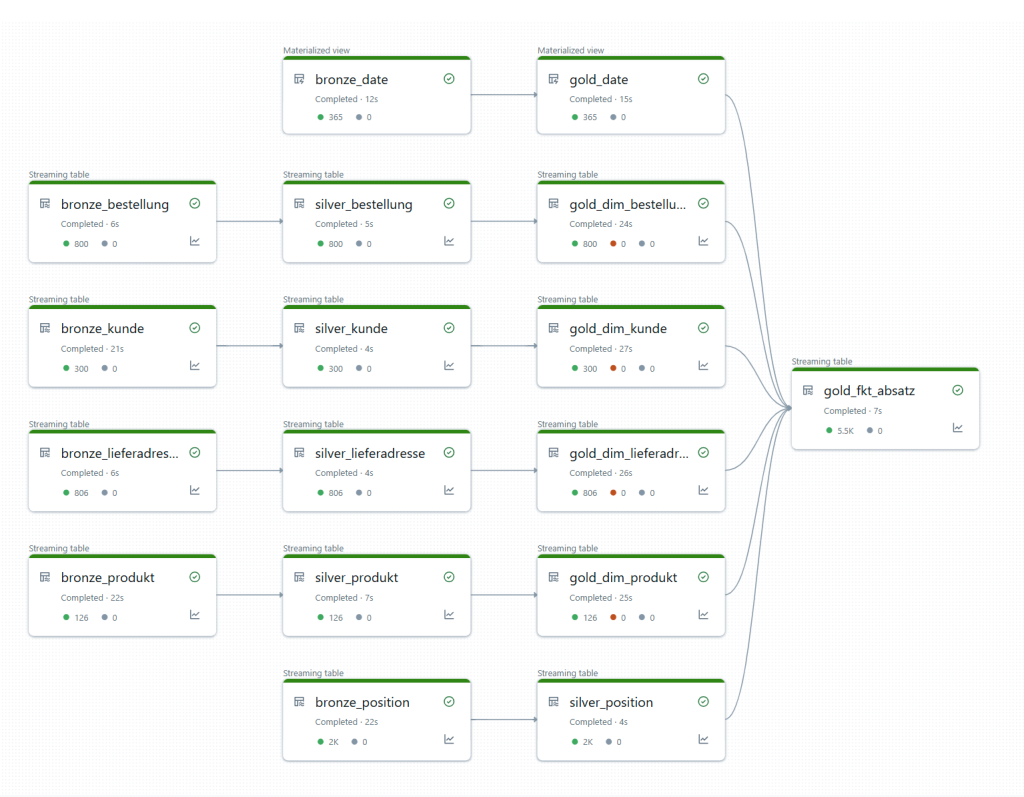
Abbildung 8: Modell
Databricks Workflows basieren auf Jobs und ermöglichen komplexe Abhängigkeiten. Ein Workflow besteht aus mehreren Tasks. Unser Prozess wird über einen Job ausgelöst, der die Pipeline ausführt.
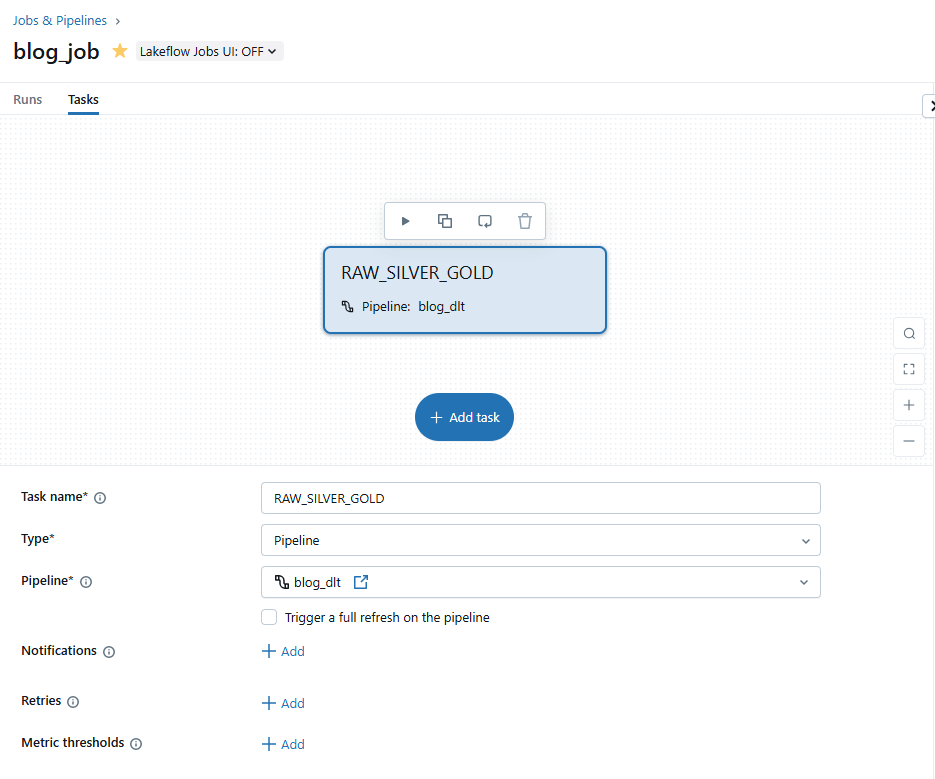 Abbildung 9: Job
Abbildung 9: Job
Jede Ausführung beinhaltet Logs, Metriken, Status sowie Artefakte wie erzeugte Tabellen oder Dateien. Ein weiterer wichtiger Aspekt ist die Darstellung der Data Lineage, die in Databricks bis auf Spaltenebene erfolgt.
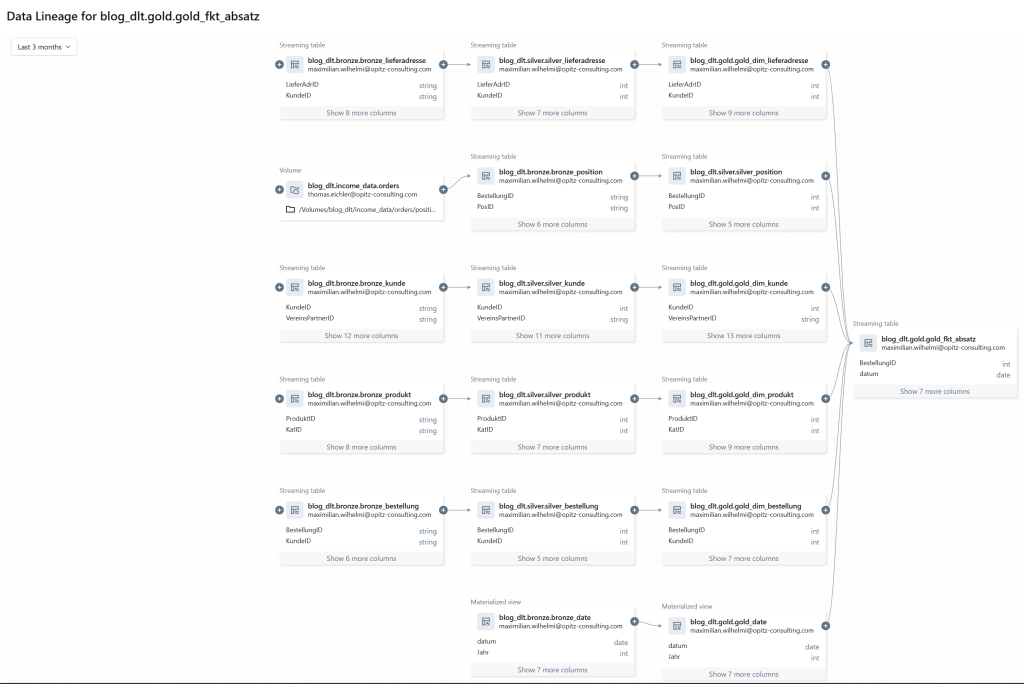 Abbildung 10: Lineage overview
Abbildung 10: Lineage overview
Diese geht bis auf Spaltenebene runter.
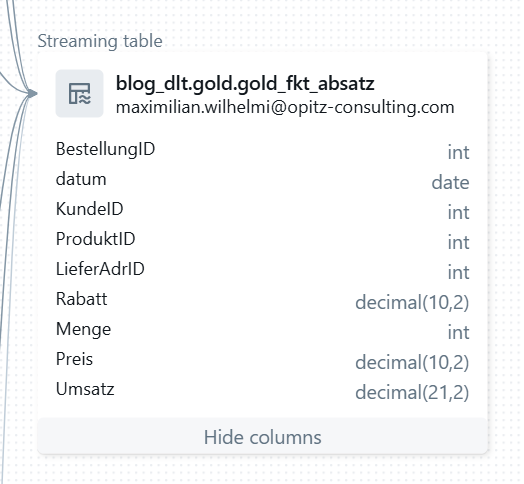 Abbildung 11: Lineage detail
Abbildung 11: Lineage detail
Feeling Databricks DLT
Die Arbeit im Projekt zeigt, dass SQL allein für komplexere File-Verarbeitung nicht ausreicht und Python in Kombination mit SQL die beste Herangehensweise darstellt. Der RAW-Layer lässt sich mithilfe von KI-Tools sehr schnell entwickeln, während ab dem Conformed-Layer solide Python-Kenntnisse erforderlich sind. SQL-Abfragen dauern meist nur wenige Sekunden, allerdings benötigen auch Cluster-Initialisierungen eine gewisse Zeit. Die Notebook-Umgebung ist angenehm, jedoch wird komplexere Logik schnell unübersichtlich, weshalb eine sehr strukturierte Arbeitsweise notwendig ist. Gleiches gilt insbesondere für den Gold-Layer.“
Mehr aus dieser Blogserie
Teil 1: Medaillon-Architektur, Delta Live Tables und dbt in der Praxis
Teil 2: Was ist Databricks? Was bietet mir das Tool?
Teil 3: Was ist DBT und warum ist es für moderne Datenpipelines so wichtig?
Teil 4: Gegenüberstellung der Ansätze und Fazit
Viel Spaß beim Lesen!


