
This very short article will contribute to the section „Analytics with R“ and how results can be visualized using Tableau. The following few maps depict those Twitter posts that match the keywords „refugee“, „asyl“ or „flüchtlinge“ and that include readable information about the origin (location) of the post.
After data was collected and preprocessed in R, we used a Tableau Trial-Version to visualize results in the best possible manner. Tableau is an easy-to-use Software for visualisation and comes with a 14-days free-to-use version after installation.
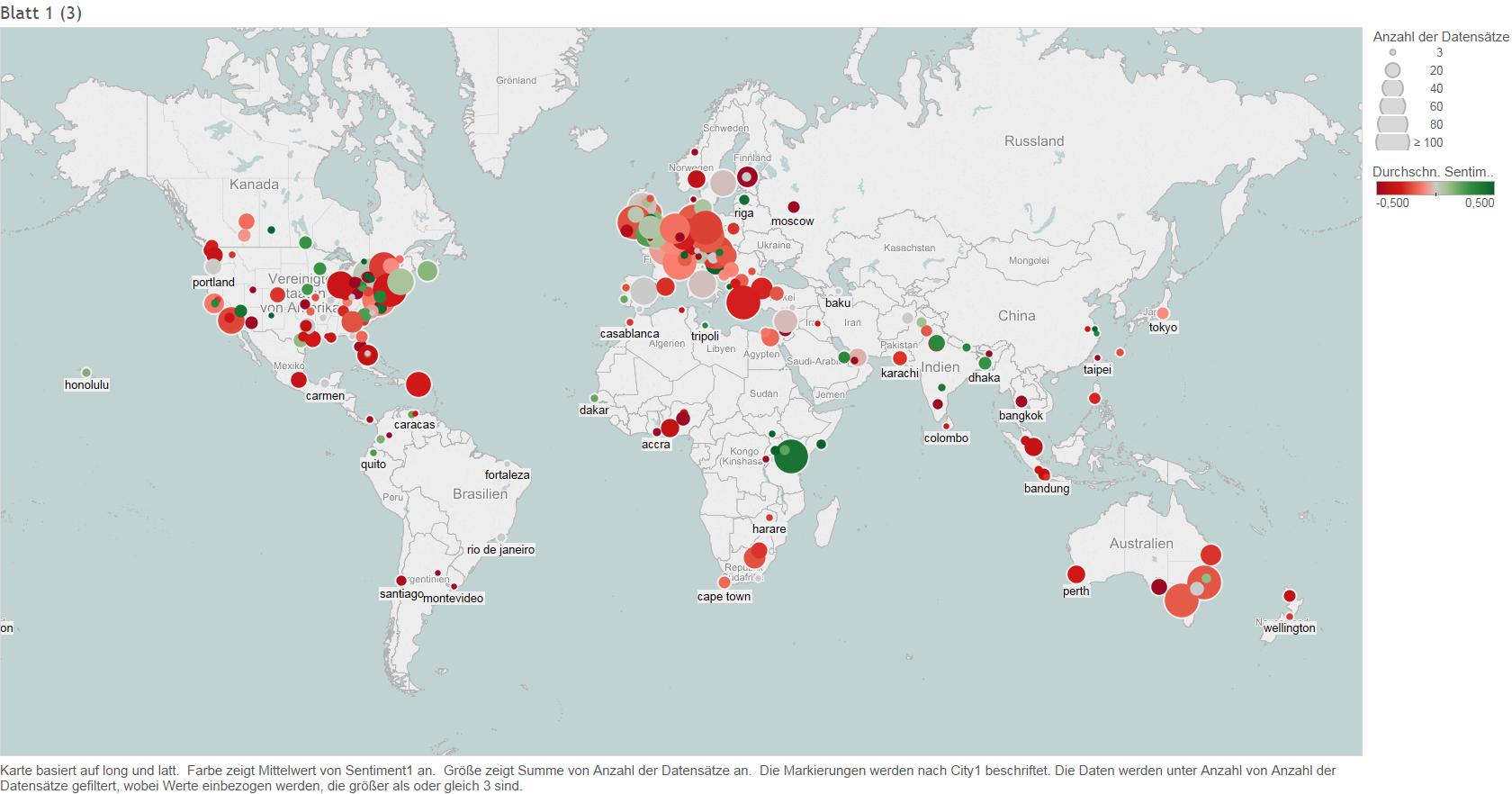
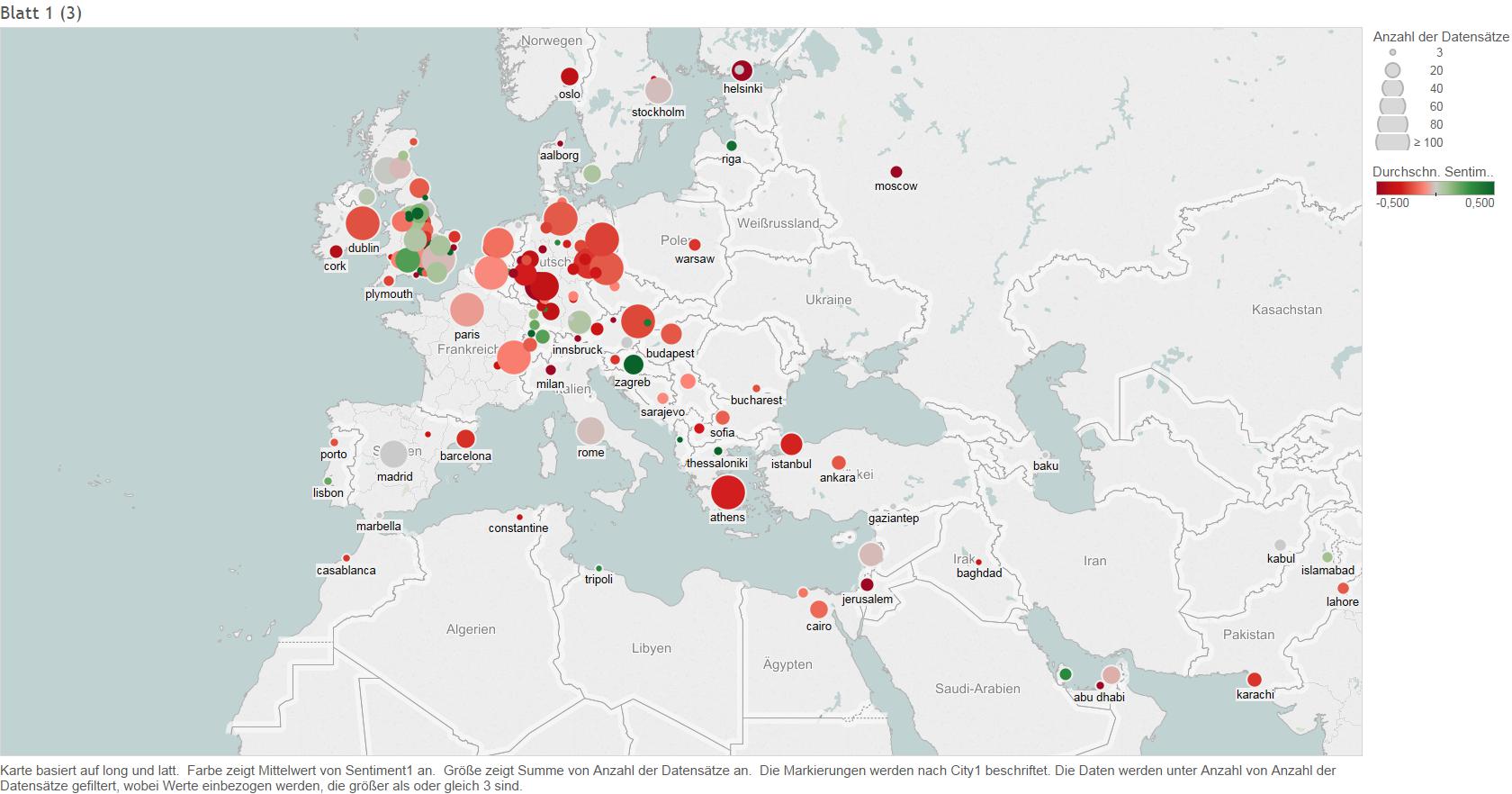
The color represents the average sentiment score of the posts originating from the location, the size of the bubbles shows the number of tweets per Location. Tweets have been collected between 06th and 8th of November 2015.
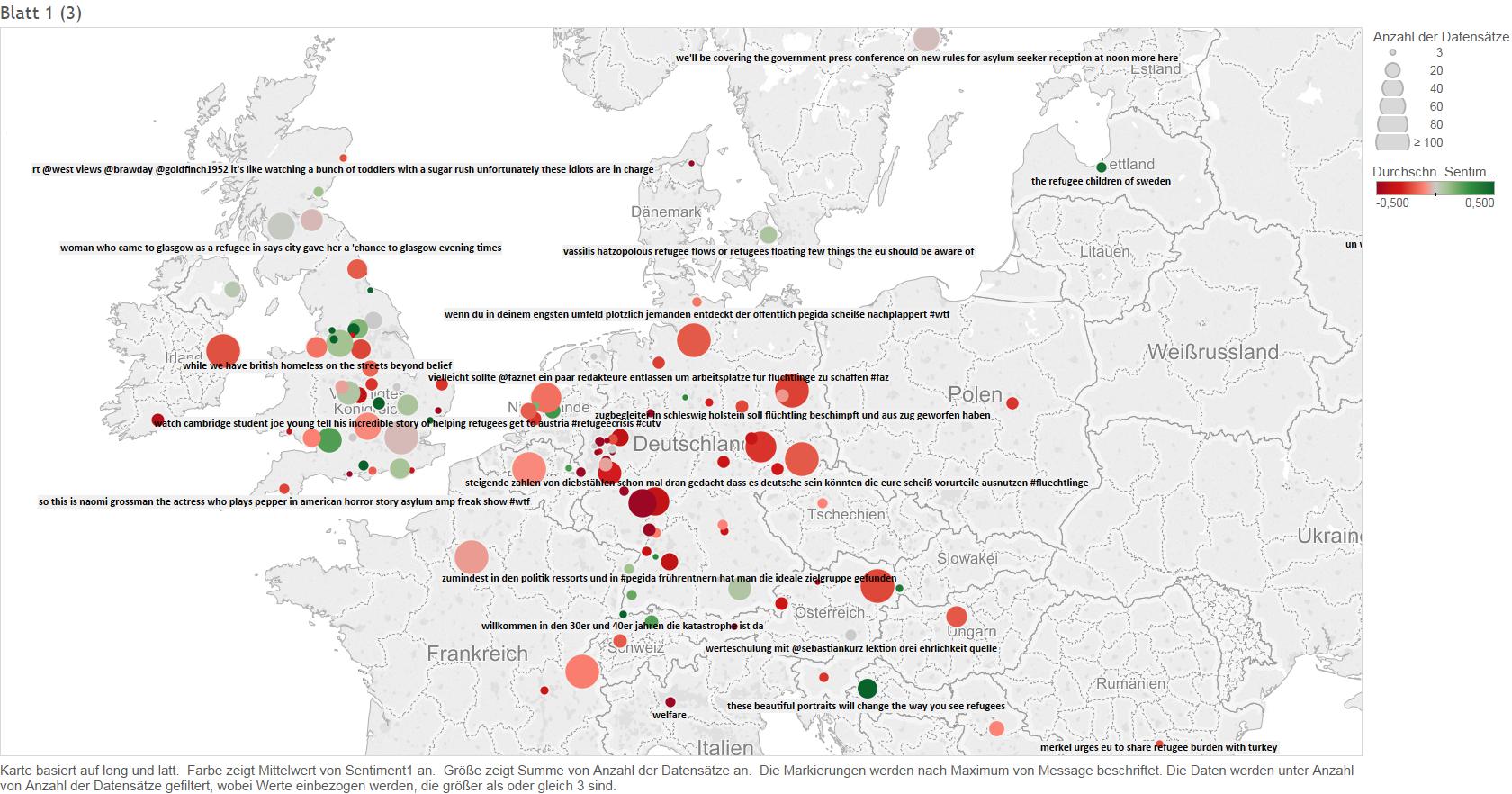
The upper map additionally illustrates, what kind of tweets are included in total analysis. For this one tweet per location was randomly chosen to be displayed on the map.
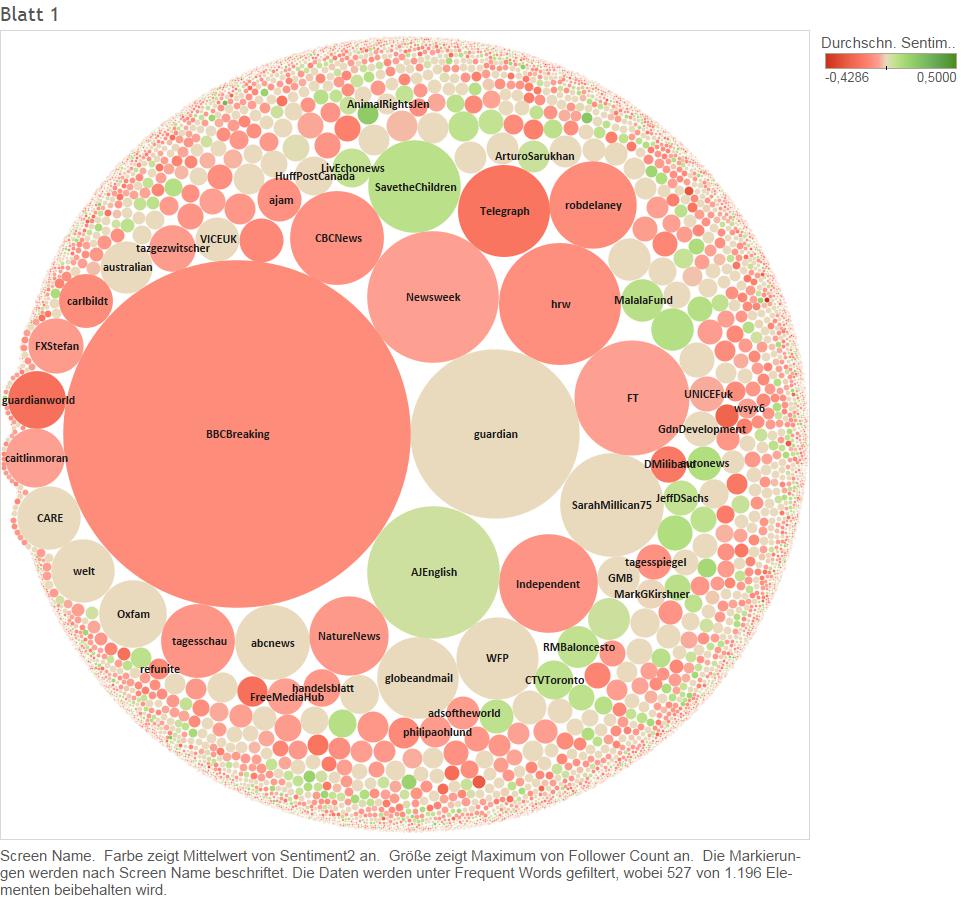
If you are further interested in data analysis in R and visualization in Tableau do not hesitate to contact me. If you simply want to practice with Tableau, download the Software from the Tableau Website (http://www.tableau.com/).
The final dataset for the Tableau analysis:
… here comes the original json file and additional information required for full analysis:
http://www.file-upload.net/download-11039881/Data.zip.html
… and here comes the R Skript for preprocessing the data (assumes the input data being a json file from twitter developer API):
#set JAVA HOME PATH
Sys.setenv(JAVA_HOME=“C:\\Program Files\\Java\\jre1.8.0_40″)
library(tm)
library(class)
library(rJava)
library(RWeka)
library(wordcloud)
library(stringi)
library(plyr)
library(rjson)
library(jsonlite)
library(stringr)
library(data.table)
library(plyr)
url = ‚path_to_JSON‘
plainText = readLines(url, encoding = „UTF-8“)
length(plainText)
#—————————————————–
# read json
tweets = ls()
text = matrix(„0“, length(plainText), 8)
for (i in 1:length(plainText))
{
#tweets[i] = jsonlite::fromJSON(plainText[i])
tweets = fromJSON(plainText[i])
if (!is.null(tweets$user$screen_name)){
text[i,1] = tweets$user$screen_name }
else {
text[i,1] = NA }
if (!is.null(tweets$text)){
text[i,2] = tweets$text }
else {
text[i,2] = NA }
if (!is.null(tweets$place$country)){
text[i,3] = tweets$place$country }
else {
text[i,3] = NA }
if (!is.null(tweets$place$country_code)){
text[i,4] = tweets$place$country_code }
else {
text[i,4] = NA }
if (!is.null(tweets$user$location)){
text[i,5] = tweets$user$location }
else {
text[i,5] = NA }
if (!is.null(tweets$lang)){
text[i,6] = tweets$lang }
else {
text[i,6] = NA }
if (!is.null(tweets$timestamp_ms)){
text[i,7] = tweets$timestamp_ms }
else {
text[i,7] = NA }
if (!is.null(tweets$user$followers_count)){
text[i,8] = tweets$user$followers_count }
else {
text[i,8] = NA }
# print
if (i/100 == floor(i / 100) )
{
print(paste(floor(i/length(plainText) * 100),‘ Prozent ausgelesen.‘))
}
}
#——————————————————-
# check results
length(text[ ,1])
# regexp:
screenName = gsub(„[^[:alnum:]///‘ ]“, „“, text[ ,1])
message = text[ ,2]
location_1 = gsub(„[^[:alnum:]///‘ ]“, „“, text[ ,3])
location_2 = gsub(„[^[:alnum:]///‘ ]“, „“, text[ ,4])
location_3 = gsub(„[^[:alnum:]///‘ ]“, „“, text[ ,5])
lang = text[ ,6]
timestamp = as.numeric(text[ ,7])
follower_count = text[ ,8]
Data <- data.frame(screenName = as.factor(screenName), message = as.factor(message),
location_1 = as.factor(location_1), location_2 = as.factor(location_2),
location_3 = as.factor(location_3), lang = as.factor(lang),
timestamp = as.factor(timestamp), follower_count = as.factor(follower_count)
)
#function most frequent elements
freqfunc <- function(x, n)
{
tail( sort(table(as.character(x)), decreasing = FALSE, na.last = NA), n)
}
#call function
freqfunc(Data$message, 5)
freqfunc(Data$screenName, 5)
## z.B. remove duplicates
g = Data[ !duplicated(Data$message), ]
# clean text
# tolower
g$message = stri_trans_tolower(g$message, locale = NULL)
g$message[3]
# URLs
g$mentionedURL = sapply( g$message,
function(x)
{
ww = regmatches(x, gregexpr(‚http[s]?://(?:[a-zA-Z]|[0-9]|[$-_@.&+]|[!*\\(\\),]|(?:%[0-9a-fA-F][0-9a-fA-F]))+‘, x))
ww2 = do.call(paste, c(as.list(ww)))
ww3 = paste(ww2, collapse = ‚ ‚)
return(ww3)
}
)
g$message[3]
# blanks
g$message = gsub(‚\n‘, ‚ ‚, g$message)
g$message[3]
# delete referrer
g$message = gsub(„rt @[a-zA-Z0-9]+: „, “ „, g$message, perl=T)
g$message[3]
# URLs by ‚URL‘
g$message = gsub(‚http[s]?://(?:[a-zA-Z]|[0-9]|[$-_@.&+]|[!*\\(\\),]|(?:%[0-9a-fA-F][0-9a-fA-F]))+‘, “, g$message)
# signs to ignore
g$message = gsub(„[^a-zA-Z0-9 ‚@#öäüßÜ–Ü„Ü]“, “ „, g$message)
# multiple blanks
g$message = gsub(„(?<=[\\s])\\s*|^\\s+$", "", g$message, perl=TRUE)
# numbers alone
g$message = gsub(‚\\s*(?
g$message[3]
#————————————— Find Location ——————————-
g$message = as.character(g$message)
countryList = read.csv(‚path_to_csv/All_Cities_WorldWide.csv‘, sep=‘;‘, header = TRUE, dec=‘.‘)
countryList = subset(countryList, nchar(as.character(City)) > 3)
countryList = subset(countryList, Population > 100000)
countryList2 = read.csv(‚path_to_csv/countries.csv‘, sep=‘,‘, header = TRUE, dec=‘.‘)
countryList2 = tolower(countryList2$English.Name)
countryList2 = gsub(„[^a-zA-Z0-9 ‚öäüßÜ–Ü„Ü]“, “ „, countryList2)
suchVector = as.vector(c(as.character(countryList$City), as.character(countryList2)))
Text = stri_trans_tolower(g$location_3, locale = NULL)
#Text = g$message
suchVectorTokenized = gsub(“ „, „@“, suchVector)
indexDoppel = which(grepl(„@“, suchVectorTokenized))
nurDoppelnamen = suchVectorTokenized[indexDoppel]
for (i in 1:length(nurDoppelnamen)) {
Text = gsub(suchVector[indexDoppel][i], nurDoppelnamen[i], Text)
print(i*length(Text))
}
findCity = function(sentences, countryList)
{
scores = laply(sentences, function(sentence, Countries_and_Cities)
{
word.list = str_split(sentence, ‚\\s+‘)
words = unlist(word.list)
pos.matches = match(words, Countries_and_Cities)
pos.matches = as.factor(pos.matches[!is.na(pos.matches)])
best = names(sort(summary(pos.matches), decreasing=TRUE))[1:3]
if (is.null(best) || is.na(best))
{
return (c(NA, NA, NA))
}
countryIndex = as.integer(best)
return(Countries_and_Cities[countryIndex])
}, countryList)
country.df = scores
return(country.df)
}
Countries = findCity(Text, suchVectorTokenized)
Countries = gsub(‚@‘, ‚ ‚, Countries)
g$City1 = as.factor(Countries[ ,1])
g$City2 = as.factor(Countries[ ,2])
g$City3 = as.factor(Countries[ ,3])
# ——- coordinates —————-
a = numeric()
latt = numeric()
long = numeric()
x <- countryList$City
for (i in 1:length(g$City1)) {
if (length(which(x %in% g$City1[i])) == 1) { # hier stadt mit den meisten einwohnern auswählen…
a = which(x %in% g$City1[i])[1]
latt[i] = countryList[a, 6]
long[i] = countryList[a, 7]
print(i)
}
else if (length(which(x %in% g$City1[i])) > 1) {
a = which(x %in% g$City1[i])
b = which.max(countryList[a, 5])
latt[i] = countryList[a, 6][b]
long[i] = countryList[a, 7][b]
print(i)
}
else {
latt[i] = NA
long[i] = NA
}
}
g$latt = as.numeric(latt)
g$long = as.numeric(long)
# ———— frequent words in vectors —————
frequentWords = strsplit(as.character(g$frequentWords), split=’|‘, fixed=TRUE)
relevantWords = matrix(‚NA‘, length(frequentWords), 4)
for (i in 1:length(frequentWords)) {
temp = unlist(frequentWords[i])
#print(temp)
if (length(temp) == 0)
{
relevantWords[i, ] = c(NA, NA, NA, NA)
}
else if (length(temp) == 1)
{
relevantWords[i, ] = c(temp[1], NA, NA, NA)
}
else if (length(temp) == 2)
{
relevantWords[i, ] = c(temp[1:2], NA, NA)
}
else if (length(temp) == 3)
{
relevantWords[i, ] = c(temp[1:3], NA)
}
else if (length(temp) == 4)
{
relevantWords[i, ] = c(temp[1:4])
}
}
g$relevantWord1 = relevantWords[ ,1]
g$relevantWord2 = relevantWords[ ,2]
g$relevantWord3 = relevantWords[ ,3]
g$relevantWord4 = relevantWords[ ,4]
#————— Sentimentanalyse ——————-
pos = scan(‚E:/TEMP Ordner TestDaten/TEMP Twitter/positive-words.txt‘, what=’character‘, comment.char=‘;‘)
neg = scan(‚E:/TEMP Ordner TestDaten/TEMP Twitter/negative-words.txt‘, what=’character‘, comment.char=‘;‘)
#Funktion
score.sentiment = function(sentences, pos.words, neg.words, .progress=’none‘) {
sentiments = laply(sentences, function(sentence, pos.words, neg.words) {
word.list = str_split(sentence, ‚\\s+‘)
words = unlist(word.list)
pos.matches = match(words, pos.words)
neg.matches = match(words, neg.words)
pos.matches = !is.na(pos.matches)
neg.matches = !is.na(neg.matches)
# score ermitteln durch summe(pos) – summe(neg) und durch tweetlänge teilen
score = sum(pos.matches) – sum(neg.matches)
score2 = (sum(pos.matches) – sum(neg.matches)) / length(words)
return(c(score, score2))
}, pos.words, neg.words, .progress=.progress )
sentiments.df = data.frame(Sentiment_1=sentiments[ ,1], Sentiment_2=sentiments[ ,2])
return(sentiments.df)
}
# call Sentimentanalyse:
sentiment = score.sentiment(g$message, pos, neg)
g$Sentiment1 = sentiment[ ,1]
g$Sentiment2 = sentiment[ ,2]
# —————————Corpus for WordCloud———————————-
cleanText = g[ ,2]
#create Corpus german
germanTweets = cleanText[g$lang == ‚de‘]
length(germanTweets)
text_corpus_german <- Corpus(VectorSource(germanTweets))
# Stemming
c1 <- tm_map(text_corpus_german, stripWhitespace)
c2 <- tm_map(c1, stemDocument, language = "german")
c3 <- tm_map(c2, removeWords, stopwords("german"))
# Ergebnisse anschauen:
lapply(c3[1:3], as.character)
# Erstelle WordCount über Corpus
BigramTokenizer <- function(x) NGramTokenizer(x, Weka_control(min = 2, max = 2))
unigrams = DocumentTermMatrix(c3)
bigrams = DocumentTermMatrix(c3, control = list(tokenize = BigramTokenizer))
# Ergebnisse sichten
dimnames(unigrams)$Terms
length(dimnames(unigrams)$Terms)
# reduce no of terms
s.unigram_german = removeSparseTerms(unigrams, 0.999)
s.bigram_german = removeSparseTerms(bigrams, 0.999)
s.unigram_german = data.matrix(s.unigram_german)
s.bigram_german = data.matrix(s.bigram_german)
m_german = cbind(s.unigram_german, s.bigram_german)
dim(m_german)
#————-create Corpus english————————————
nongermanTweets = cleanText[g$lang != ‚de‘]
length(nongermanTweets)
text_corpus_nongerman <- Corpus(VectorSource(nongermanTweets))
# Stemming
c1 <- tm_map(text_corpus_nongerman, stripWhitespace)
c2 <- tm_map(c1, stemDocument, language = "english")
c3 <- tm_map(c2, removeWords, stopwords("english"))
# Ergebnisse anschauen:
lapply(c3[1:3], as.character)
# Erstelle WordCount über Corpus
BigramTokenizer <- function(x) NGramTokenizer(x, Weka_control(min = 2, max = 2))
unigrams = DocumentTermMatrix(c3)
bigrams = DocumentTermMatrix(c3, control = list(tokenize = BigramTokenizer))
# Ergebnisse sichten
dimnames(unigrams)$Terms
length(dimnames(unigrams)$Terms)
s.unigram_nongerman = removeSparseTerms(unigrams, 0.999)
s.bigram_nongerman = removeSparseTerms(bigrams, 0.999)
s.unigram_nongerman = data.matrix(s.unigram_nongerman)
s.bigram_nongerman = data.matrix(s.bigram_nongerman)
m_nongerman = cbind(s.unigram_nongerman, s.bigram_nongerman)
colnames(m_nongerman)
# —————TF-IDF Standardization:———————————————–
# chose whether german or english
m = m_nongerman
#m = m_german
docsize = rowSums(m*(m > 0))
res1 = m / docsize*log(nrow(m) / (1 + rep(colSums(m > 0), each = nrow(m)))) * (m > 0)
Y_TFIDF = res1
Y_TFIDF = na.omit(Y_TFIDF)
#——————— PLOTS ——————————————————
# Sum wordcount
# … without standardization
#termDocMatrix = t(as.data.frame(apply(m, 2, sum)))
# … or with standardization
termDocMatrix = t(as.data.frame(apply(Y_TFIDF, 2, sum)))
termDocMatrix = as.data.frame(termDocMatrix)
colnames(termDocMatrix) = colnames(m)
# Word Cloud erstellen
ap.m <- t(as.matrix(termDocMatrix))
ap.v <- sort(rowSums(ap.m), decreasing=TRUE)
ap.d <- data.frame(word=names(ap.v), freq=ap.v)
table(ap.d$freq)
pal2 <- brewer.pal(8, "Set1")
png(„c:/wordcloud.png“, width=1200, height=800)
wordcloud(ap.d$word, ap.d$freq, scale=c(7, 0.4), min.freq=3,
max.words=150, random.order=FALSE, rot.per=.15, colors=pal2)
dev.off()
# save
write.table(g, „your_path/Tweets_Asyl.csv“, sep = „;“, row.names = FALSE, dec=‘,‘, quote=TRUE)




2 Kommentare
Very interesting post! Well done! Thanks for sharing 🙂
One question though, how did you extracted the tweets data set? Which software or tools did you used? As far as I know there are some restrictions in terms of the time frame you can extract (at least for free) using existing twitter API as of today.
Also, which hashtags/criteria did you applied in your extraction?
I think is really important know where the data comes from, to understand it’s not truncated and reflects the most relevant tweets, therefore opinions.
Hi,
I used a word list for search containing the following german and english words: „Flüchtling(e), refugee(s)“. No hashtags were specified.
Then I only searched for „de“ and „en“ posts, all done by a little streaming application that catches all outgoing Posts.
Generally there are two ways of catching tweets via Twitter API: Tee easier one is done on historized tweets that were posted during the last 48 hours:
library("twitteR")
library("wordcloud")
library("tm")
library("stringi")
# Your keys here:
api_key = " *** "
api_secret = " *** "
access_token = " *** "
access_token_secret = " *** "
setup_twitter_oauth(api_key,api_secret,access_token,access_token_secret)
# Search
searchString = "refugee"
tweets = searchTwitter(searchString, n=10000, lang=NULL, since="2015-10-01", until="2015-10-10",
locale=NULL, geocode=NULL, sinceID=NULL, maxID=NULL,
resultType=NULL, retryOnRateLimit=120)
# How many results were found
length(tweets)
# get an element out of the list ...
tweets[[4]]$created
#save text in array
text <- sapply(tweets, function(x) x$getText())
text = stri_trans_tolower(text, locale = NULL)
The other way is catching the twitter outgoing stream directly which I did not realized with R.