

An sich ist die Visualisierung von Daten – und hier insbesondere von größeren Datenmengen – in Form von Tabellen, Graphen oder Zeitreihen mittlerweile ein Standard, der von allen marktgängigen Reporting-Werkzeugen beherrscht wird.
Es gibt allerdings durchaus auch Fragestellungen, bei denen die tabellarische Darstellung eher aussagelos ist oder keine oder nur eingeschränkte Interpretation der Daten zulässt. Insbesondere sind hier Daten betroffen, deren Interpretation von geografischen Rahmenbedingungen abhängt. Hier muss man wissen, dass ca. 80% der Daten einen Ortsbezug haben und somit bei entsprechender Fragestellung in Verbindung mit Kartenmaterial auszuwerten sind.
Diese Lücke haben einige Anbieter – und hier insbesondere die großen Anbieter von Werkzeugen zur Berichtserstellung – erkannt und ihr Portfolio ergänzt. Allerdings erweisen sich hier vielfach die bestehenden Architekturen und Versionen als „Klotz am Bein“ und die Notwendigkeit, zu anderen Tools kompatibel sein zu müssen und die im Laufe der Jahre historisch gewachsenen Features weiter unterstützen zu müssen (eine neue Version soll ja in der Regel immer mehr können als die Vorgängerversion) als hinderlich.
Diese „ökologische Nische“ bietet daher den Nährboden für kleinere Anbieter, die mit schlanken Werkzeugen ohne ellenlange (Versions-)Historie diesen Markt für sich in Anspruch nehmen können. Einer dieser Anbieter ist die in Karlsruhe ansässige Firma „DISY Informationssystem GmbH„. Disy bietet mit seinem Tool Cadenza ein vollständig Browser-basiertes Reportingwerkzeug an, das die interaktive Darstellung von Daten auf Kartenmaterial zur seinem besonderem Anliegen erklärt hat. Das Tool hat sich mittlerweile bewährt und insbesondere in den Verwaltungen von Bund, Ländern und Kommunen Fuß gefasst.
Bei OPITZ CONSULTING haben wir uns disy Cadenza sehr genau angesehen. Wie unsere ersten Schritte und Erfahrungen aussahen, erfahrt ihr in diesem Blogartikel.
Was macht disy Cadenza so besonders?
Disy Cadenza ist ein Reporting-Werkzeug, mit dem du klassische Berichte erstellst und Daten in Tabellen und Diagrammen visualisierst. Der eigentliche Clou dieses Tools ist jedoch die interaktive Darstellung von Kennzahlen auf Kartenmaterial – sofern sich die Daten in räumlichen Kontexten analysieren lassen. „Interaktiv“, weil die Möglichkeit besteht, Daten „räumlich“ durch entsprechende grafisch zu definierende Filter einzugrenzen.
Wenn dies entwicklungsseitig eingestellt wurde, wirken die so definierten Filter auf alle Elemente der Arbeitsmappe. Zusätzlich besteht die Möglichkeit, Reichweiten mithilfe eines Layers darzustellen („Welche Orte sind binnen eines definierten Zeitraumes zu erreichen?“) und Wegstrecken mit speziellen Infos anzureichern (z. B. Berechnung der Fahrtstrecke zwischen zwei Orten).
Die Besonderheit dieses Tools liegt weniger in der Form der Darstellung (andere Reportingwerkzeuge bieten auch die Option der Darstellung von Daten auf Karten) – es ist die weitreichende Integration dieser Visualisierung in die Administrations- und Reportingmöglichkeiten dieses Tools.
Für Analyselösungen mit diesen Möglichkeiten wurde der Begriff der „Business- und Location-Intelligence-Lösung“ geprägt.
In Disy Cadenza ist seit dem Frühjahrsrealease 2024 eine Schnittstelle verfügbar, um eigene Skripte zu integrieren, z. B. in R oder Python. Diese Schnittstelle ermöglicht es, die Ergebnisse eigener, beliebiger Analysen im gegebenen Reportingkontext zu integrieren und so auch die Ergebnisse komplexer Analysen über ein zentrales Portal zugänglich zu machen.
Am Anfang steht … die Installation
Cadenza kann in verschiedenen Varianten betrieben werden: Als Stand-Alone-Variante in einer lokalen Installation auf einem Desktop, als Web-Variante in einer Serverinstallation, die in einen Browser dargestellt wird oder über die Mobile-Variante, welche den Betrieb der Anwendung auf mobilen Endgeräten unterstützt.
Zur Evaluation wird für die beiden erstgenannten Varianten eine Demoversion mit ausgeliefert. Grundlage für diesen Artikel ist die Analyse der Demoversion für die Web-Variante.
Die Installation gestaltet sich sehr einfach: Die gelieferte Archivdatei entpacken – fertig!
Das Ergebnis ist ein Zielverzeichnis, welches alle zum Betrieb erforderlichen Dateien enthält: 
Zum Start der Web-Version ist der mitgelieferte Applikationsserver (Apache Tomcat) mit dem Skript „startup“ im Unterverzeichnis „CadenzaWeb/bin“ zu starten, die Arbeit kann dann losgehen.
 Ich muss hier anmerken, dass dieses Vorgehen deswegen so einfach funktioniert, weil die vor-konfigurierte Demoversion verwendet wird. Sie hat den Vorteil, dass die Verbindung zur Repository-Datenbank konfiguriert ist, die Konfiguration einer anderen Datenbank als Repository ist jedoch möglich und wird später gezeigt werden. Darüber hinaus können die Eigenschaften des Applikationsservers über Konfigurationsdateien angepasst werden.
Ich muss hier anmerken, dass dieses Vorgehen deswegen so einfach funktioniert, weil die vor-konfigurierte Demoversion verwendet wird. Sie hat den Vorteil, dass die Verbindung zur Repository-Datenbank konfiguriert ist, die Konfiguration einer anderen Datenbank als Repository ist jedoch möglich und wird später gezeigt werden. Darüber hinaus können die Eigenschaften des Applikationsservers über Konfigurationsdateien angepasst werden.
Der andere Teil der Wahrheit ist, dass ein Repository in einer ORACLE- oder PostgreSQL – Datenbank liegen muss. Andere Datenbanken werden aktuell für das Cadenza Repository nicht unterstützt – allerdings zeigt sich disy auch gerne bereit, die Liste der unterstützten Datenbanken auf Nachfrage zu erweitern.
Zuerst die Pflicht: Der „klassische Bericht“
Jedes Reporting-Werkzeug muss Daten darstellen können. Diese eher „archaische“ Variante der Tabellensilos ist hierbei ebenso das Pflichtprogramm wie die aufbereitete Darstellung in Form von Diagrammen.
Die Berichte werden in Arbeitsmappen gespeichert – diese Ordnung hilft dir, deinen Bericht in der Vielzahl der verfügbaren Berichte wiederzufinden. Alternativ gibt es auch die Möglichkeit nach Stichworten zu suchen, um damit in Verbindung stehende Berichte zu finden.
Die gewünschten Informationen sind noch nicht verfügbar? OK. Wir müssen einen neuen Bericht anlegen. Der Einfachheit halber legen wir zunächst eine Arbeitsmappe an und in diese Arbeitsmappe einen Bericht. Nachdem das Icon angeklickt und der gewünschte semantische Layer ausgewählt worden ist, gelangst du zur Oberfläche für die Berichtserstellung.

Auf den ersten Blick erinnert das Frontend an das Konkurrenzprodukt Microsoft PowerBI. Hier können wir einen Bericht definieren. Dafür wählen wir die darzustellenden Daten und Attribute aus, die in Filtern Anwendung finden sollen.
Im ersten Schritt müssen wir die Datenquelle in der rechten Spalte „Datenmanager“ auswählen. Sobald die gewünschte Darstellungsform ausgewählt ist, können wir in unserer Funktion als Datenmanager die gewünschten Attribute per Drag and Drop in den Designer ziehen. Die Ausprägungen des ausgewählten Attributes werden sofort in der gewählten Darstellung visualisiert. Die Darstellung berücksichtigt dabei die im „semantischen Layer“ – auf diesen komme ich später noch einmal zurück – definierte Hierarchie der Objekte. Die Reihenfolge der Spalte, die du in der Abbildung siehst, lässt sich über die Reihenfolge im Designer festlegen.

Ebenso ist die Einbindung von Diagrammen problemlos: Anstelle des Visualisierungstyps „Tabelle (aggregiert)“ wählst du den passende Diagrammtyp aus und schon wird die aktuelle Darstellung konvertiert. Hierbei bleiben auch Filter etc. erhalten.
Zur Kür: Die Darstellung von KPIs auf Karten
Soweit – so gut. Kommen wir zurück zur eigentlichen Domäne von Cadenza: der Darstellung bestimmter Kennzahlen, also KPIs, auf Kartenmaterial. Dieses erfolgt in den gleichen Strukturen wie in einem klassischen Bericht mit der gleichen Methode: Es sind Dimensionsdaten und Kennzahlen auszuwählen. Ebenso können Filter definiert werden. Nur wird als Visualisierungstyp hier ein Element aus der Gruppe „Karten“ ausgewählt und bei den Dimensionen muss darauf geachtet werden, dass diese einen Ortsbezug aufweisen. „Ortsbezug“ bedeutet hier, dass die Attributwerte geocodiert sein müssen.
Beispiel: Gastronomie in Heidelberg
Ist das Datenmaterial vorhanden, ist die Erstellung einer Liste von Gastronomiebetrieben geübte Praxis. Die folgende Abbildung zeigt, wie das in Cadenza aussieht. Dazu sei angemerkt, dass auf der linken Seite des Fensters, das die Abbildung zeigt, Filter definiert wurden um Betrieb mit unvollständiger Adresse auszuschließen. Ein weiterer Filter erlaubt die Einschränkung auf den Ort – in diesem Beispiel ist noch keine Einschränkung erfolgt.

Interessiere ich mich für Betriebe in der Nähe eines bestimmten Standorts, so kann die Darstellung auf Kartenmaterial hilfreicher sein:
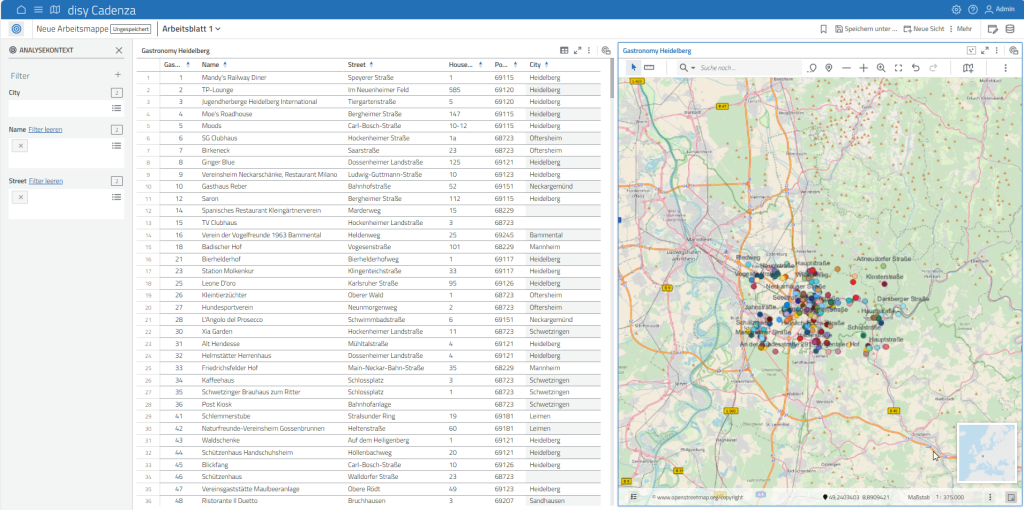
Da es nun ein wenig unübersichtlich wird, wird eine Einschränkung auf den Ort eingefügt (z.B. „Dossenheim“). Der Filter wirkt auf beide Elemente des Arbeitsblatts: Links in der Liste werden die Betriebe auf Dossenheim beschränkt. Auch auf der Karte finden sich nur die gefilterten Datenpunkte. Um die Lage der Gastronomiebetriebe besser begutachten zu können, kann ich in die Karte hineinzoomen und das Restaurant mit der passenden Lage auswählen.
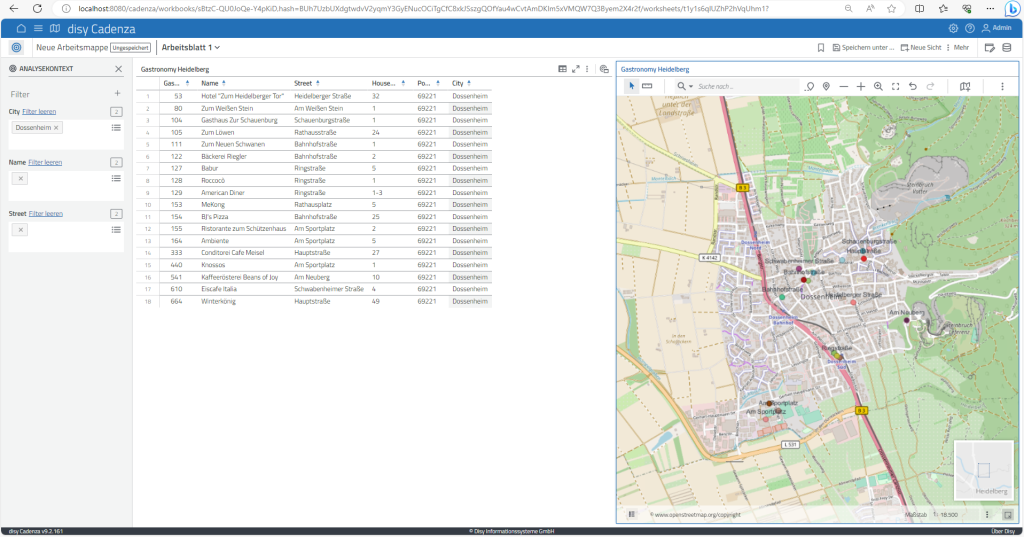
Das in diesem Beispiel verwendete Kartenmaterial stammt von OpenStreetMap. Hier sind jedoch auch Karten anderer Dienste verwendbar – ebenso proprietäre Dienste zur Geocodierung der Attributwerte.
Perspektivisch immer wichtiger: Die API zu externen Inhalten
Weil extensive Datenanalyse auch mit Mitteln künstlicher Intelligenz zunehmend wichtiger wird, hat auch Integrierbarkeit dramatisch an Bedeutung gewonnen. Das heißt, wir brauchen Schnittstellen zu externen Programmen und Skripten. Das Herbstrelease, das seit 2023 verfügbar ist, deckt diesen Bedarf ab, frühere Versionen weniger. Wer eine ältere Version nutzt, sollte daher dringend über ein Update nachdenken!
Ein „externer Inhalt“ kann ein Analyse-Skript sein (hier werden mit R und Python die im Datenanalysekontext gängigen Programmiersprachen unterstützt), genauso gut kann es jedoch auch die Bereitstellung von Daten sein oder eine weitere Form der Datenvisualisierung kann über diese Schnittstelle bereitgestellt werden.
Zur Einbindung der externen Inhalten gibt es in der Management-Konsole den Menüpunkt „Analyse-Erweiterung“. Hier können zuvor erstellte Inhalten eingebunden, mit erforderlichen Berechtigungen in Cadenza versehen und entsprechend ihrer Funktion kategorisiert werden.
Der Prozess zur Durchführung der Analyse läuft dann so ab:
- Überprüfung der Berechtigung,
- Cadenza stellt dem Skript die Eingangsdaten als Input zur Verfügung
- das Programm oder Skript startet und stellt den Output zur Visualisierung bereit,
- Cadenza nimmt die Daten entgegen und visualisiert die Daten in einer Arbeitsmappe
Da hier ggf. Berechtigungen zur Nutzung der bereitgestellten Daten beachtet werden müssen, sind entsprechende Mechanismen zur Beschränkung der Visualisierung zu definieren.
Wer hierzu mehr erfahren möchte: Mit der genaueren Darstellung dieser Schnittstelle nebst einiger Beispiele für deren Nutzung wird sich ein weiterer Blogbeitrag beschäftigen.
Definition der semantischen Schicht
Mit Cadenza soll Cadenza jede Person einer Fachabteilung in der Lage sein, mit den vorhandenen Daten eine Visualisierung zu erstellen. Um das zu erreichen, müssen wir die physikalische Datenmodellierung, die sich bekanntlich eher technisch optimieren möchte als an Anwendungsfreundlichkeit, so „umzuformulieren“, dass Fachanwender damit arbeiten können. Diese logische Sicht auf die Daten nennt sich „semantische Schicht“.
Es ist also klar, dass ein großer Teil der Magie von BI-Tools in der Bereitstellung der Daten stattfindet. Schauen wir uns diesen Teil genauer an.
Die Ausgangslage ist, dass die Nutzdaten – also die Daten, mit denen die Anwendenden arbeiten sollen – in einer Datenbank vorliegen. Anders als bei der Repository-Datenbank kann das jede via JDBC verfügbare Datenbank sein.
Im ersten Schritt ist diese Datenbank anzubinden. Hierzu ist die „Management Console“ zu verwenden. Die Management Console ist das universelle Administrationswerkzeug von CADENZA und wird uns im folgenden häufiger begegnen. Diese Console zu ist über das Zahnradsymbol in der Menuleiste (durch roten Kreis in Abbildung XY markiert) zu öffnen, sofern der Benutzer über Administratorprivilegien verfügt.

1. Schritt: Anlegen des Repositories
Zum Anlegen eines Repositories nutzen wir die Schaltfläche „Repositorys“. Es erscheint eine weitere Maske, die zum eine Liste der verhandenen Repositories enthält (und die durch anklicken des jeweiligen Repositorynamens dann geändert werden können).

Zum Anlegen ist der Menupunkt „Neues Repository“ (rechts oberhalb der Repositoryliste) anzuklicken.
In dem sich öffnenden Fenster sind zum einem der Name des Repositorys anzugeben (hierbei ist es sinnvoll darauf zu achten, dass der Name sprechend und eindeutig ist!) sowie die beiden Optionen „Projekte“ und „Veröffentlichungskontrolle“ zu definieren. Unter „Veröffentlichungskontrolle“ verbirgt sich die Option, die Versionen des Repositorys jeweils zu speichern und damit auch die Möglichkeit, auf ältere Versionen zurückspringen zu können. Die Option bedingt, dass später ein CDS („Cadenza Data Storage“) definiert wird.
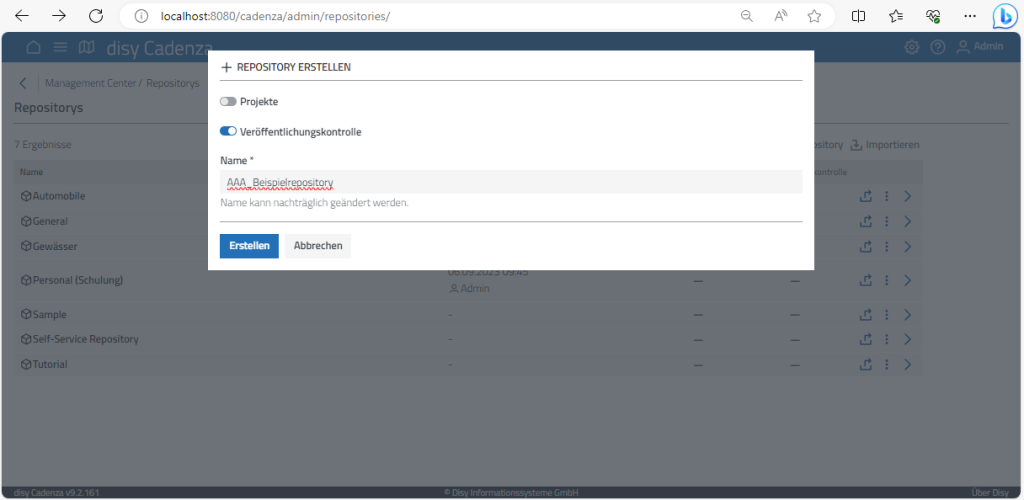
Nach Eingabe des Namens und Wahl der beiden Optionen auf „Erstellen“ klicken und schon ist die Hülle des Repositorys erstellt. In den folgenden Schritten wird diese Hülle mit Inhalt gefüllt. (Hinweis: Die beiden Wahlmöglichkeiten sind optional. Da sie ggf. weiteren Aufwand nach sich ziehen, solltest du diese nur auswählen, wenn sie wirklich gewünscht werden.)
2. Schritt: Anbinden der Datenbank
Das Anbinden einer Datenbank als Datenquelle ist eine eher unkomplizierte Angelegenheit. Ausgehend von der Startseite nach Anmeldung (Wichtig: Der Anwender muss über Administratorprivilegien verfügen!) ist unter dem Menupunkt „Datenquellen“ die Option zur Anbindung neuer Datenquellen verfügbar.
 Anklicken dieser Option öffnet ein weiteres Fenster, in die Zugangsdaten einzutragen sind:
Anklicken dieser Option öffnet ein weiteres Fenster, in die Zugangsdaten einzutragen sind:
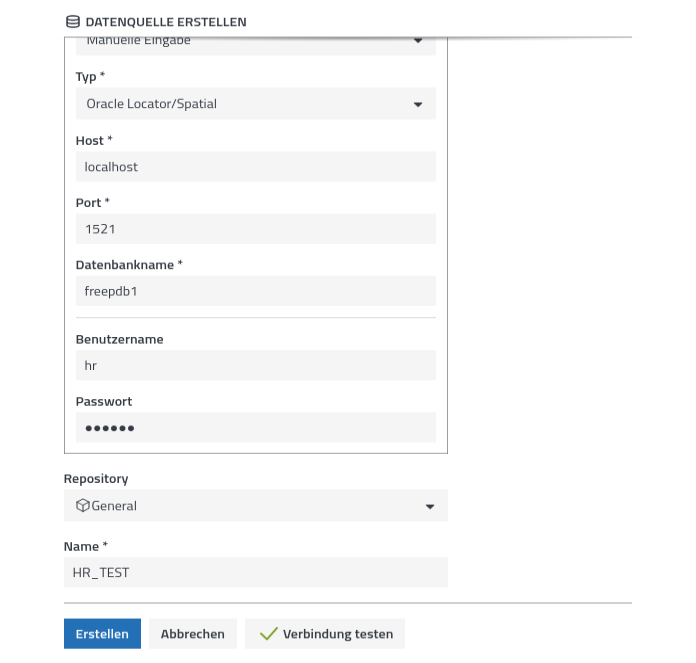
Nach erfolgreichem Test wird die Datenquelle durch Anklicken von „Erstellen“ verfügbar gemacht. Die Auswahl möglicher Datenquellen ist aktuell auf diese acht beschränkt:
- ArcGIS Feature Service
- Elasticsearch
- H2
- Microsoft SQL Server
- Oracle Locator/Spatial
- PostgreSQL/PostGIS
- WFS
- SAP HANA (seit Release 9.3 (Herbst 2023))
Die auf den ersten Blick nicht allzu üppige Unterstützung verschiedener Quellsysteme verdient indes einen zweiten Blick: Hier handelt es sich um gängige Vertreter von relationalen und File-basierten Datenbanken ebenso wie die Möglichkeit zur Anbindung von Big-Data-Umgebungen. Und sollte eine gewünschte Datenbank nicht unterstützt werden: Frag‘ am besten bei disy nach – hier ist man gerne bereit, die Liste verfügbarer Datenbanken zu ergänzen, sofern der Bedarf besteht.
3. Schritt: Definition der Präsentationschicht
Ist die Datenbank mit den Quelldaten erst einmal angebunden, bleibt noch die Aufgabe, die Spalten in der Datenbanktabellen als Attribute des Metalayers für die Endanwender sichtbar zu machen und die erforderlichen Berechtigungen zu vergeben.
Hierzu dient das Item „Objekttyp“ in der Administrationskonsole:

Ein „Objekttyp“ ist zunächst analog zu einer „Tabelle“ auf einer Datenbank zu verstehen. Es handelt sich also um ein generalisiertes Objekt, das die verschiedenen Datenobjekte (Attribut, Parameter o.ä.) enthält, die zur Darstellung in einem Bericht oder in einer Analyse vorgesehen sind. Durch Anklicken von „Objekttypen“ öffnet sich die Liste der bereits definierten Objekttypen nebst der Möglichkeit, neue Objekttypen anzulegen:
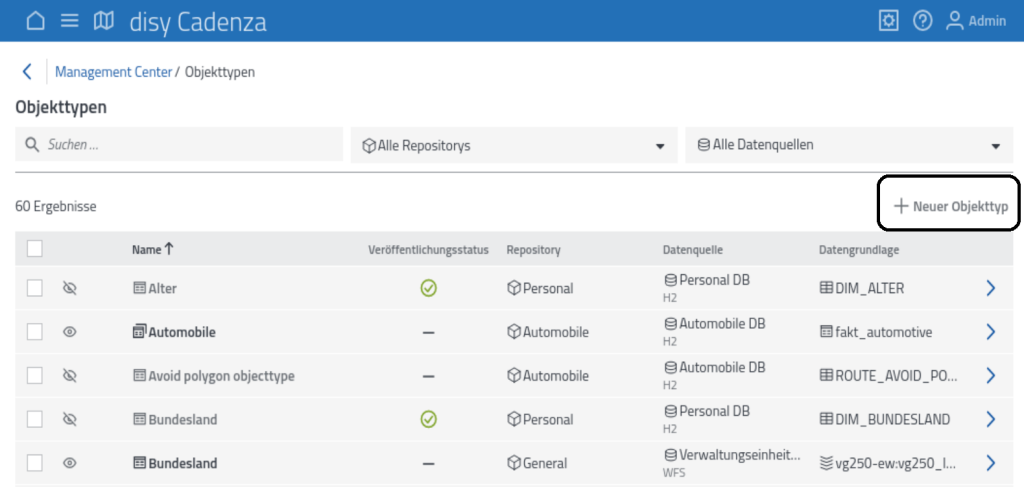 Beim Anklicken von „Neuer Objekttyp“ ergeben sich zwei Optionen zum weiteren Verfahren:
Beim Anklicken von „Neuer Objekttyp“ ergeben sich zwei Optionen zum weiteren Verfahren:
- Die Option „Einfachen Objekttyp erstellen …“ bietet die Möglichkeit, einen Objekttyp aus einer vorhandenen Datenquelle einzubinden. Hierbei werden per default alle Objekte des ausgewählten Typs übernommen. Es besteht jedoch die Möglichkeit, die darzustellenden Objekte auszuwählen.
- Die Option „Zusammengesetzten Objekttyp erstellen …“ bietet die Möglichkeit, Objekte verschiedener zuvor erstellter, einfacher Objekttype zu einem neuen Objekttyp zusammenzufügen. Diese Option hilft bei der Zusammenstellung von Objekten, die für definierte Analysen erforderlich sind und vereinfacht hierbei insbesondere die Vergabe von Zugriffrechten.
Einfachen Objekttyp erstellen
Zur Erstellung eines einfachen Objekttyps diese Option wählen, sodass die Liste der zuvor definierten Datenquellen erscheint und zur Auswahl der gewünschten Datenquelle auffordert:
 Nach Auswahl der Datenquelle wird die Liste der verfügbaren Objekte abgerufen und zur Auswahl gestellt:
Nach Auswahl der Datenquelle wird die Liste der verfügbaren Objekte abgerufen und zur Auswahl gestellt:
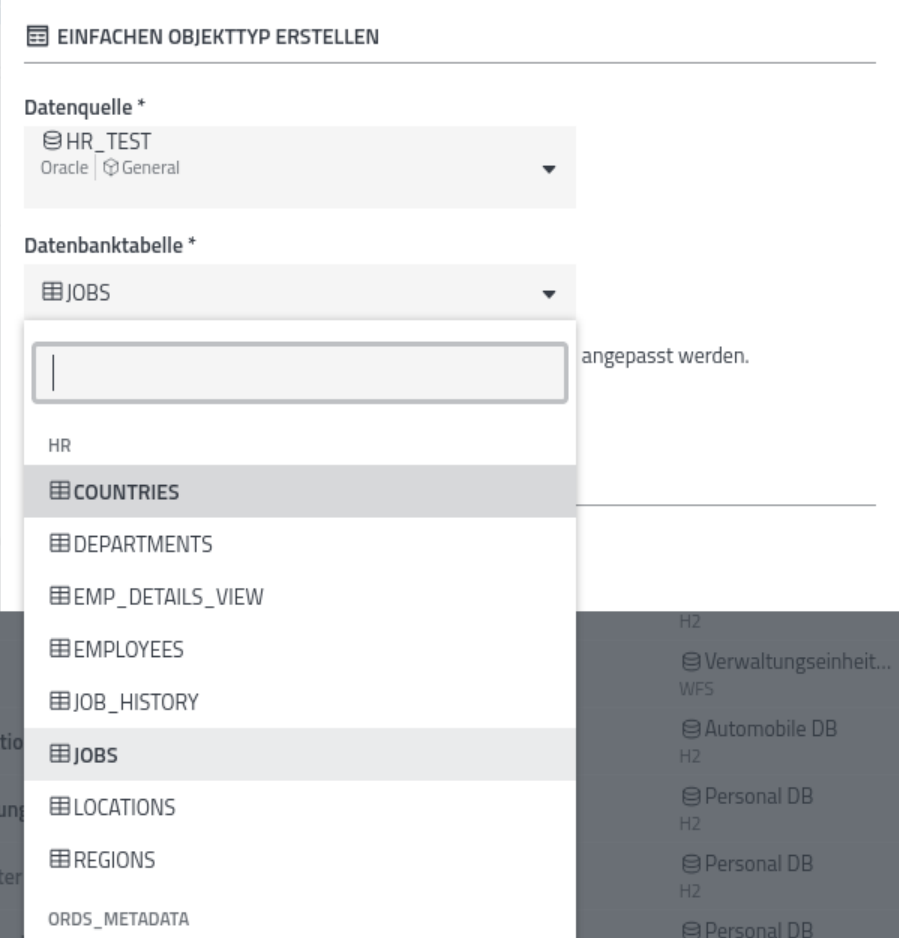 Nach Auswahl der Objekt kann noch der Name des Objekts angepasst werden (hier ist ein für den (Fachbereichs-)Anwender sprechender Name zu bevorzugen!). Zur weiteren Bearbeitung wird nun die Liste der verfügbaren Attribute dargestellt:
Nach Auswahl der Objekt kann noch der Name des Objekts angepasst werden (hier ist ein für den (Fachbereichs-)Anwender sprechender Name zu bevorzugen!). Zur weiteren Bearbeitung wird nun die Liste der verfügbaren Attribute dargestellt:
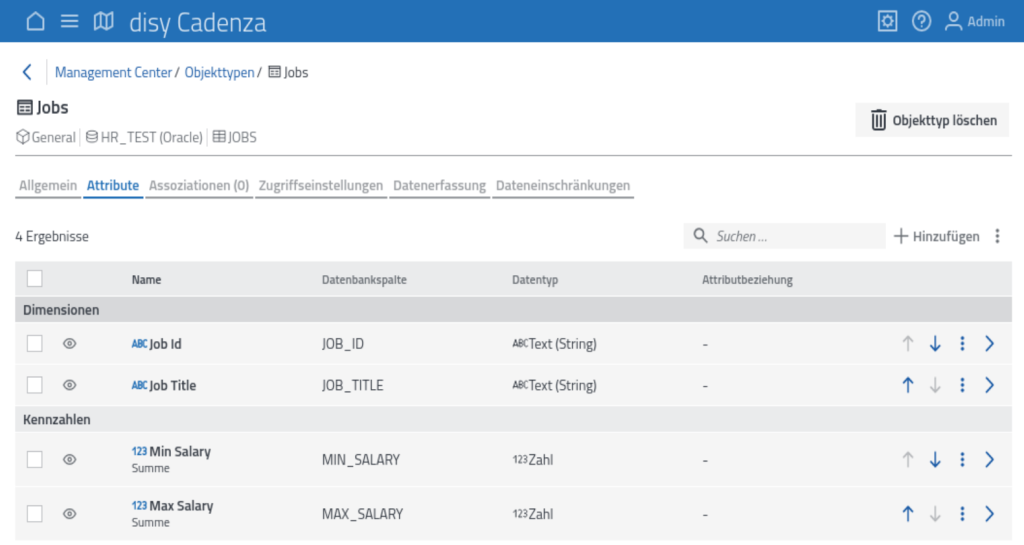 Da die Daten einer Tabelle oder eines Objekttyps allein in der Regel keine Aussagen darstellen, sind die Verknüpfungen zwischen den Objekttypen zu definieren. Dieses geschieht unter dem Punkt „Assoziationen“.
Da die Daten einer Tabelle oder eines Objekttyps allein in der Regel keine Aussagen darstellen, sind die Verknüpfungen zwischen den Objekttypen zu definieren. Dieses geschieht unter dem Punkt „Assoziationen“.
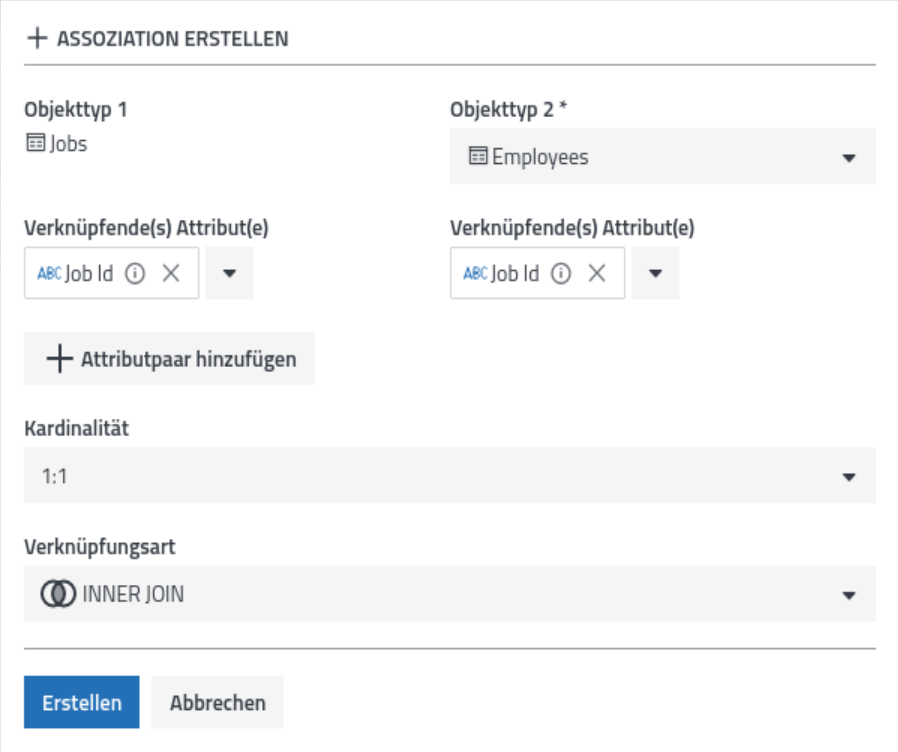
Durch Anklicken von „Erstellen“ wird wieder das zu erstellende Artefakt, in diesem Fall die Assoziation, angelegt und kann dann im weiteren Verlauf genutzt werden. Last but not least muss noch die Zugriffsberechtigung zugewiesen werden. Hierzu auf den Reiter „Zugriffsberechtigungen“ wechseln.

Hier ist zunächst die Gruppe bzw. der Anwender auszuwählen, dem die Berechtigung zugewiesen werden soll um dann zu definieren, in wie weit der Anwender bzw. die Gruppe die Daten verwenden darf. Durch „Erstellen“ wird die Berechtigung dann zugewiesen.
Darüber hinaus wird an dieser Stelle noch die Möglichkeit geboten, neben der horizontalen Einschränkung der Daten (durch Auswahl der verwendbaren Objekte) die Daten auch vertikal einzuschränken. Hierzu können „statische Dateneinschränkungen“ definiert werden. Diese Bedingungen sind können von Anwendenden nicht umgangen werden und beschränken somit die verfügbaren Daten.
In diesem Punkt unterscheidet sich diese Option übrigens von der Möglichkeit, Dateneinschränkungen benutzerbezogen zu definieren. Letztgenannten Option ist optionaler Bestandteil der Berechtigungsvergabe und auch auf diesem Arbeitsblatt zu definieren.
Einbindung von Advanced Analytics
In der vorliegenden Version sind die Möglichkeiten für elaborierte Analysen eher begrenzt: Die mitgelieferten Mittel der Visualisierung entsprechenden den Standards der retrospektiven Betrachtung. Hier werden durch die Integration von Kartenmaterial durchaus weitergehende Möglichkeiten eröffnet.
Allerdings genügt dieses nicht mehr den aktuellen Stand, wo prädikative Analysen mit verschiedenen Analysemöglichkeiten erforderlich wären. Diesem trägt der Hersteller jedoch mit zukünftigen Releases Rechnung: So ist das Frühjahrsrelease 2024 um die Möglichkeit ergänzt worden, beliebige Skripte in R oder Python zur Generierung darstellbarer Datasets auszuführen. Diese Option ermöglicht natürlich auch die Nutzung neuronaler Netze u. ä. zur Datenanalyse.
Wir dürfen also auf die Erweiterungen in den zukünftigen Releases gespannt sein.
Verwaltung der Zugriffsrechte
Anforderung
Die Verwaltung der Zugriffsrechte ist bei BI-Frontends immer ein leidiges Thema: Niemand schränkt diese Rechte gerne ein und eigentlich hätte jeder Nutzer gerne uneingeschränkte Berechtigungen. Doch es gibt regulatorische Anforderungen, z. B. durch DSGVO, Verträge und juristische Rahmenbedingungen, die diese Rechte einschränken und einen sicheren Umgang mit Daten vorschreiben. Somit sind Datenzugriffe in einer Organisation immer zu begrenzen, sowohl horizontal (Einschränkung der verfügbaren Attribute) oder auch vertikal (Einschränkung der Datenmenge an Hand von Merkmalsausprägungen).
Auf der einen Seite ist hierfür eine weitgehende Detaillierung erforderlich, die aber auch Fehlermöglichkeiten birgt. Daher sollte ein Frontend zur Vergabe der Zugriffsrechte optimalerweise so gestaltet sein, dass die Rechtevergabe
- zum einen auf verschiedenen Ebenen möglich ist,
- diese aber so übersichtlich gestaltet wird, dass nachvollziehbar bleibt, welche Rechte jeweils effektiv vergeben sind.
Realisierung der Rechtevergabe bei disy Cadenza
Um den verschiedenen Benutzer nicht individuell Rechte zuweisen zu müssen – das würde bei großen Benutzerkreisen zu unübersichtlich und aufwändig werden – werden Benutzer mit gleichen Bedarfen in Gruppen zusammengefasst. Entsprechend werden die Berechtigungen auch an Gruppen vergeben. Dieses Vorgehen entspricht dem Standard und wird von Cadenza unterstützt.
Die Verwaltung der Zugriffsrechte erfolgt in der Managementkonsole unter den Menüpunkten „Benutzergruppen“ und „Benutzerrollen, Freigabestufen“. Um die Benutzergruppen zu erstellen, klickst du auf den Punkt „Benutzergruppen“: Daraufhin erscheint dieses Fenster:
Daraufhin erscheint dieses Fenster:

Der Hersteller hat standardmäßig vier Benutzergruppen vordefiniert und mit entsprechenden Rechten versehen:
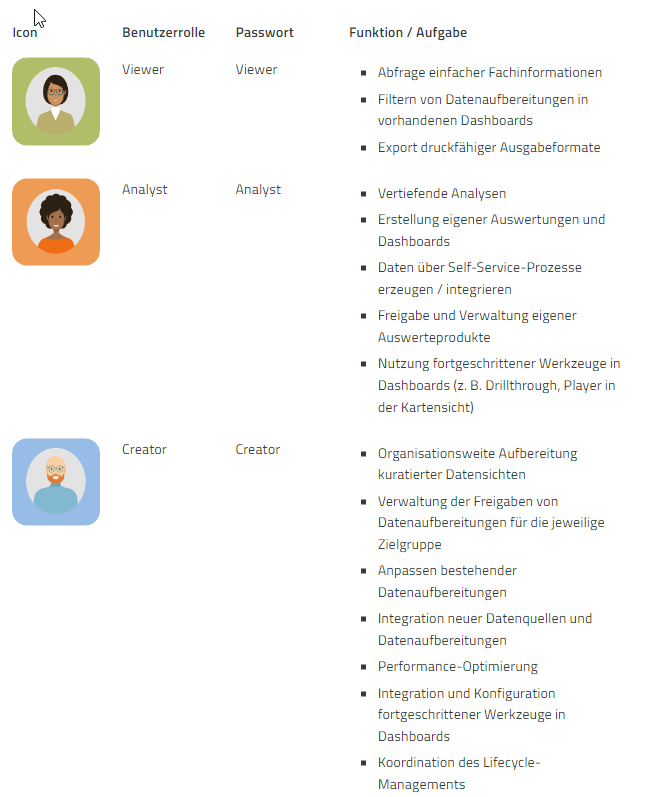

In den meisten Fällen kommt man mit diesen vier Gruppen schon sehr weit – im Bedarfsfall können aber zusätzliche Gruppen angelegt werden. Sind die Benutzergruppen definiert, müssen noch die Berechtigungen zugewiesen werden.
Mein Fazit
In „kleinen“ Systemen, bei denen eine enge Zusammenarbeit zwischen Entwicklern, Administratoren und Anwendern möglich ist und nicht zu viele Anwender mit dem Tool arbeiten, bietet dieses Tool alles, was ein Anwenderherz begehrt. Das gilt umso mehr, wenn der Entwickler fehlende Funktionalitäten durch Erstellen von R- und Python-Skripten ergänzen kann.
Hast du große Anwenderkreise, sehr komplexer Datenmodelle mit vielen Objekten oder stark regulierte Kontexte, bleibt disy Cadenza meiner Meinung nach noch ein wenig Luft nach oben für weitere Entwicklungen:
- Aktuell geht ab einem gewissem Punkt der Überblick über erteilte Berechtigungen verloren
- und es fehlt eine schnelle Möglichkeit zur Analyse erteilter Berechtigungen.
Es ist jedoch davon auszugehen, dass dieses Problem im Zuge der weiteren Entwicklung behoben wird.
Ein wenig Luft verbleibt noch bei der Vergabe von Berechtigungen: Prinzipiell sind die für die meisten Installationen ausreichend. Nicht zuletzt aufgrund gesetzlicher Anforderungen können Berechtigungen sehr granular vergeben werde. Daher ist hier besondere Sorgfalt an den Tag zu legen. Wünschenswert wäre daher eine Übersicht über effektiv erteilte Privilegien auf Benutzerebene um eine etwaige Fehlersuche insbesondere bei großen Systemen mit vielen Benutzern zu unterstützen. Im Grenzfall umfangreicher Datenmodelle wird der Anwender dann vor die Herausforderung gestellt, den Überblick über die je Benutzerrolle erteilten Berechtigungen zu bewahren.
Jenseits dieser Grenzfälle und für alle, die auf der Suche nach einem leichtgewichtigen, Browser-basierten Reportingwerkzeug mit allen nötigen Funktionen sind, lohnt sich hingegen ein detaillierter Blick auf disy Cadenza.



