

Ich persönlich brenne für das Thema KI (künstliche Intelligenz), insbesondere für NLP-Technologien (Verarbeitung von natürlicher Sprache). Was lag also näher, als in einem Projekt ein eigenes KI-Model anzulernen und auf bestimmte Bedürfnisse anzupassen? Gesagt, getan. Modelle, die ich hierfür nutzen wollte, waren schnell gefunden, auch eine Datenbasis in Form von 800 PDF-Dokumenten habe ich zur Verfügung gestellt bekommen. Dann die Ernüchterung: Wie bekomme ich diese Texte, die größtenteils eingescannte Papiere sind, in eine für mich nutzbare Form? Unweigerlich musste ich mich somit mit OCR-Technologien auseinandersetzen und bin dabei auf Tesseract gestoßen. Damit habe ich es geschafft, eine Datenbasis aufzubauen, um meine Modelle zu trainieren.
Was ist OCR?
Optical Character Recognition oder Optische Zeichenerkennung, kurz OCR, ist die Umwandlung von gescannten oder gedruckten Textbildern und handgeschriebenem Text in bearbeitbaren Text zur maschinellen Weiterverarbeitung. Diese Technologie ermöglicht es Maschinen, den Text automatisch zu erkennen. Patel et al. (2012) beschreiben sie wie eine Kombination aus Auge und Verstand des menschlichen Körpers. Das Auge kann den Text auf den Bildern sehen, aber eigentlich verarbeitet und interpretiert das Gehirn den mit dem Auge gelesenen Text. (Vgl. Patel, C., Patel, A., Patel, D., Tesseract: A Case Study, 2012, S. 50.)
Tesseract
Das Open-Source-Anwendung Tesseract wurde zwischen 1984 und 1994 bei HP entwickelt und 1995 noch einmal modifiziert und verbessert, um eine höhere Genauigkeit bei der Bilderkennung zu erreichen. Obwohl ursprünglich von HP entwickelt, wurde es nie selbst von HP produktiv eingesetzt. Bis zur Freigabe 2005 als Open Source stand die Entwicklung von Tesseract still, wurde dann aber von Google bis 2018 fortgesetzt. Nach 2018 wurde das Projekt von der GitHub- Community übernommen und wird dort bis heute weiterhin gepflegt. (https://github.com/tesseract-ocr/tesseract)
Wie arbeitet Tesseract?
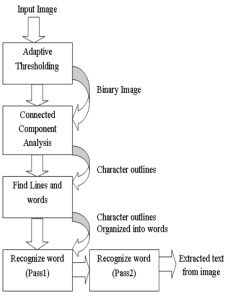
Tesseract arbeitet schrittweise wie in Abbildung 1 auch dargestellt:
- Der erste Schritt ist die adaptive Schwellenwertbildung, das Bild wird durch ein Schwellenwertverfahren in Binärdaten umgewandelt.
- Der nächste Schritt ist die Analyse der verbundenen Komponenten. Zeilen und Regionen werden auf festen Abstand oder proportionalen Text analysiert.
- Die Suche nach Zeilen und Wörtern. Der Text wird mit Hilfe von definierten Leerzeichen und Zeichenabständen in Wörter unterteilt.
- Es folgt die Texterkennung in zwei Schritten. Im ersten Durchgang wird versucht, jedes Wort des Textes zu erkennen. Jedes zufriedenstellend erkannte Wort wird an einen adaptiven Klassifikator als Trainingsdaten weitergegeben (Pass1). Durch das Training des Klassifikators soll dieser im zweiten Schritt dazu befähigt werden, ein noch besseres Ergebnis liefern zu können (Pass2).
- Im letzten Schritt wird der fertig extrahierte Text als String zurückgeliefert.
Einbinden von Tesseract in Python-Code
Tesseract lässt sich als Konsolenprogramm installieren, was auch die Grundvoraussetzung für die Nutzung in Python oder R ist. Eine Installationsanleitung findet sich unter https://tesseract-ocr.github.io/tessdoc/Installation.html. Unter Windows kann es ggf. noch nötig sein, auf die entsprechenden Sprachmodelle via Systemvariable zu zeigen. Dazu wird einfach die Variable TESSDATA_PREFIX, welche auf den Ordner tessdata im Tesseract Installationsverzeichnis zeigt, angelegt.

Die Nutzung in R und Python lässt sich über die entsprechenden Bibliotheken abbilden. Welche Programmiersprache genau benutzt wird, hängt vom Anwendungsfall und auch von den Präferenzen des Entwicklers ab. Im Hintergrund nutzen alle Lösungen immer die entsprechend installierte Tesseract-Version.
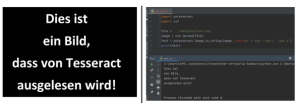
Das Einbinden von Tesseract in Python-Code gestaltet sich sehr einfach. Als Schnittstelle zu Tesseract dient in Python die Bibliothek „pytesseract“. Mit nur ein paar Zeilen Code, wie in Abbildung 3 zu sehen, lässt sich bereits der Text aus einem Bild auslesen und danach im Quellcode weiterverwenden
Wenn die OCR-Technologie an Grenzen stößt
Bei der Nutzung eines computergestützten OCR-Systems können einige Probleme auftreten. Zwischen einigen Buchstaben und Ziffern gibt es nur einen sehr geringen sichtbaren Unterschied, den ein Computer nicht verstehen kann. Zum Beispiel ist es schwierig, zwischen der Ziffer „0“ und dem Buchstaben „O“ zu unterscheiden. Ebenfalls kann es sehr problematisch sein Text zu extrahieren, der in einen sehr dunklen Hintergrund eingebettet oder auf andere Wörter oder Grafiken gedruckt ist, da das OCR-System ggf. Umrisse von Buchstaben oder Symbolen nicht erkennt oder falsch interpretiert. Außerdem muss berücksichtigt werden, dass OCR eine Technologie ist, die sich in der kontinuierlichen Weiterentwicklung befindet und die verfügbare Software unterschiedliche Genauigkeitsstufen bietet. So existieren auch in der Tesseract-Community mehrere Sprachmodelle, welche laufend weiterentwickelt werden, mit unterschiedlichen Anwendungsbereichen und Genauigkeiten. (https://github.com/tesseract-ocr/tessdata/)
Die besten Ergebnisse werden in der Regel mit einer Lösung erzielt, die auf den Anwendungsfall angepasst ist. Dies beinhaltet aber das Anlernen von eigenen Sprachmodellen, was genügend Trainingsdaten und Ressourcen voraussetzt sowie entsprechender Aufbereitung der einzulesenden Dokumente. Vorgefertigte, allgemeine OCR-Systeme haben daher meist eine wesentlich breitere Akzeptanz, die sofortige Einsatzfähigkeit ist dabei von besonderem Interesse. Je nach Qualität der einzulesenden Dokumente kann es aber auch hier notwendig sein, Anpassungen an den Dokumenten vorzunehmen.
Etwas nachgeholfen: Tricks und Kniffe für die Texterkennung mit Tesseract
In der Praxis wird man selten nur perfekt skalierte und optisch klare Bilder für die Texterkennung vorfinden, wie im vorangegangenen Beispiel in Abbildung 3. Häufig kommt es durch unterschiedliche Bildqualitäten zu Fehlern. Da Tesseract sich aber direkt in Python-Code einbinden lässt, stehen uns alle Möglichkeiten der Programmiersprache zur Verfügung, um ein besseres Ergebnis zu erzielen.
Vor dem Auslesen durch Tesseract lassen sich z. B. durch die Bibliothek cv2 die Bilder entsprechend nachbearbeiten. So wird im folgenden Beispiel die Umwandlung in Schwarz-Weiß vorgenommen und das Bild entsprechend skaliert:

Aber auch nach dem Auslesen lässt sich der gewonnene Text aufbereiten. Hier zwei Beispiele, die sich einfach umsetzen lassen:
1. Eine schnelle und effektive Möglichkeit ist das Definieren einer Funktion, wie im folgenden Codebeispiel dargestellt. Die Funktion befreit den extrahierten Text von unerwünschten Zeichen und Symbolen, sowie überflüssigen Leerzeichen, die andernfalls zu Fehlinterpretationen führen können. In Python ist dies durch reguläre Ausdrücke und Replace-Methoden schnell umsetzbar.
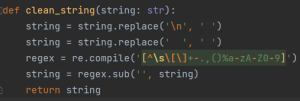
2. Bei Tesseract lassen sich Optionen setzen, um die Texterkennung von vornherein auf die vorhandene Datenbasis vorzubereiten. Im folgenden Codebeispiel wurde die Textsprache beispielsweise auf Englisch (-l eng) gesetzt und der PSM-Wert auf 6 (–psm 6), was Tesseract dazu veranlasst, einen Blocktext zu erwarten. Der OEM-Wert (–oem 1) bestimmt die Engine, die für die Bilderkennung genutzt wird. Tesseract unterstützt derzeit drei verschiedene Engine Modes, die sich hinsichtlich Performance und Genauigkeit unterscheiden.

Mehr Infos und weitere Optionen rund um Tesseract sind im offiziellen Github-Projekt zu finden: https://github.com/tesseract-ocr/tesseract
Wann ist Tesseract die richtige Wahl?
Tesseract ist als Open Source kostenlos verfügbar. Damit bietet sich das Programm für alle an, die erste Schritte in der Texterkennung gehen wollen oder kleinere Anwendungsfälle haben und nicht direkt in eine Lösung der großen Softwarehersteller investieren wollen, also für kleinere Projekte, bei denen große OCR-Lösungen Oversized und zu teuer wären. Was aber nicht ausschließt das auch Tesseract für große Projekte genutzt werden kann, da wie bereits erwähnt die Möglichkeit besteht Modelle für den eignen speziellen Anwendungsfall zu generieren, wenn eine entsprechende Datenbasis vorhanden ist.
Zusätzlich hat sich Tesseract als Vorfilterungssystem bewährt. Das heißt, bevor Dokumente z. B. Microsofts Forms Recognizer zugeführt werden, werden sie von Tesseract nach Stichpunkten durchsucht und auf Relevanz geprüft. Wir von Opitz Consulting konnten so in einem aktuellen Projekt die Kosten für den Kunden aktiv reduzieren, da nur relevante Seiten dem Micorosoft Forms Recognizer zugeführt wurden, in dem jede gelesene Seite Kosten verursacht.
Quellen
Hegghammer, Thomas: OCR with Tesseract, Amazon Textract, and Google Document AI: a benchmarking experiment, in: Journal of Computational Social Science, Nr. 1, S. 861–882, DOI: https://doi.org/10.1007/s42001-021-00149-1
Hoffstaetter, Samuel: Python-tesseract is a python wrapper for Google’s Tesseract-OCR, <https://pypi.org/project/pytesseract/>
Patel, Chirag, Patel, Atul, Patel, Dharmendra: Optical Character Recognition by Open source OCR Tool Tesseract: A Case Study, in: International Journal of Computer Applications, S. 50–56, DOI: http://dx.doi.org/10.5120/8794-2784
Smith, Ray: An Overview of the Tesseract OCR Engine,
in: Ninth International Conference on Document Analysis and Recognition (ICDAR
2007), S. 629–633, DOI: https://doi.org/10.1109/ICDAR.2007.4376991
Tesseract-OCR: Tesseract Open Source OCR Engine, <https://github.com/tesseract-ocr/tesseract>


