
In einer Firma zu jedem Thema stets den richtigen Kopf zu finden, der einem damit weiterhelfen kann oder bereits Erfahrung gesammelt hat ist nicht immer leicht. Gerade für sehr innovative, neue oder aber auch exotische Themen gleicht dies der Suche nach der Nadel im Heuhaufen. Auch wir bei OPITZ CONSULTING sind mit diesem Problem konfrontiert, dass wir für die Herausforderungen der Kunden stets den richtigen Experten zur Hand haben möchten. Diesen zu finden erweist sich jedoch bei der Vielzahl an Themen oft schwierig und das Pflegen von Skill-Datenbanken ist in dem sehr schnelllebigen IT-Business mühseelig.
Ende letzten Jahres gingen wir diese Herausforderung mit einem neuen Ansatz an, weg von einem Ansatz Wissen durch Menschen zu strukturieren hin zu einem Ansatz jegliche Form von Daten zu nutzen, um daraus die gewüschten Informationen zu extrahieren. Wir gingen von der Voraussetzung aus, dass jemand der alle Daten innerhalb des OPITZ CONSULTING Intranets – Wissensdatenbanken, Foren, Blogs, Verträge, Profile, Projektberichte und -reports, Vertriebliche Dokumente, Fachartikel, etc. – und unserer extern genutzten Systemen wie Twitter oder unserem CattleCrew Blog lesen würde zu jedem Begriff, egal ob Kundenname, Methodik, Plattform oder Technologie, beurteilen könnte wer aus unserer Firma sich mit diesem Thema zumindest am meisten beschäftigt bzw. hierzu den aktivsten Austausch hat. Dies führte uns zu der Zielsetzung eine Maschine in die Lage zu versetzen verschiedenst strukturierte Daten zu verstehen und mit Personen in Korrelation zu setzen, um anschließend daraus abzuleiten wer mit welchen Themen wie viel Erfahrung gesammelt und sich tiefgehend damit beschäftigt hat und diese Informationen jedermann über eine intuitive Suchapplikmation zugänglich zu machen. Einen Anwendungsausschnitt der derzeit im Test befindlichen Applikation ist in folgendem Screenshot zu sehen:

Damit erfüllt diese Herausforderung, die die Verarbeitung von hunderttausenden polystrukturierten Dokumenten und die Auswertung dieser bezüglich Suchbegriffen in wenigen Sekunden voraussetzt, die 3 Dimensionskritierien eines Big Data Projektes. Die angestrebte Lösung lässt sich in 3 Lösungs-Komponenten untergliedern die basierend auf unterschiedlichen Technologien einen Part dieser Aufgabe erfüllen:
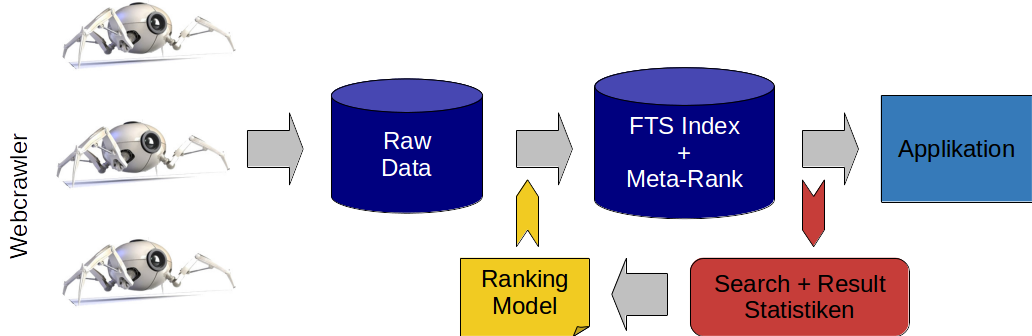
1. Ein Crawler System
Eine Komponente, welches in der Lage ist unterschiedlichste Datenquellen anzuzapfen, alle Inhalte aus diesen zu extrahieren, diesen Inhalt dann zu strukturieren, um in Folge gezielt Informationen wie Titel und Subtitel, Tags, Datum, Autoren, Referenzen und natürlich den eigentlichen Text zu erkennen und diese dann strukturiert in einem volltextindizierten Datenbank abzulegen, ist als erster Schritt erforderlich, um die auszuwertenden Daten überhaupt sammeln zu können.
Das Abzapfen von Datenbanken war hier der einfachste Schritt. Komplizierter wurde es beim Auslesen von Webinhalten unserer eigenen Portale, Foren, Wikis, Ticketsystemen und externen Quellen. Hier kam eine eigensentwcikelte Komponente, welche Crawler4J unter der Haube nutzte zur Anwendung, um Webseiten systematisch abzuwandern, jedoch keine Seite doppelt zu besuchen. Via Apache Tika für PDF und Office Files und JDOM für HTML Content wurden die Webinhalte dann tabellarisch strukturiert und gezielt die benötigten Datenfelder wie Textinhalt, Titel, Autor und Datum von nicht relevanten Inhalten der Webseite wie Navigationsleisten, Header, etc. getrennt. Diese Informationen wurden dann ebenso tabellarisch in einer Datenbank, nach Quelle getrennt persistiert. Derzeit suchen die Crawler jedes Wochenende das gesammte OPITZ CONSULTING Netzwerk ab und aktualisieren damit den nutzbaren Datenbestand.
Auszug aus einem Crawler für Lebensläufe
class CVCrawler extends OCCrawler {
TYPE_FILTER =
""".*\.(css|js|bmp|gif|jpe?g|png|tiff?|mp3|mp4|wav|avi|mov|mpeg|m4v|rm|smil|wmv|swf|wma|zip|rar|gz|pptx?|xlsx?)(\?.*)?$""".r
val VALID_TYPE_FILTER = """.*\.(pdf|docx?)""".r
val PERSON_FROM_FILENAME = """([-_]|^)(\w{3})([-_]|$)""".r
override protected def URL_CONTAINS_FILTER = "vertrieb/kurzprofileundprojektlisten" :: Nil
override protected def URL_EXCLUDE_FILTER = "GetLogon?reason=1" :: Nil
override protected def controller = CVController
override def visit(page: Page) {
val url = page.getWebURL.getURL.toLowerCase
val filename = (url split "/").last.toLowerCase
if (VALID_TYPE_FILTER findFirstIn url isDefined)
try {
if (page.getParseData.isInstanceOf[BinaryParseData]
&& ((filename contains "kurzprofil") || (filename contains "projektliste"))) {
fetchDoc(url)
} else if (url contains "vertrieb/_layouts/wordviewer.aspx?") {
val newUrl = controller.URL_HOME +
("""id=(.{1,3}vertrieb.{1,3}kurzprofileundprojektlisten.+\.docx)""".r findAllMatchIn
url map (_ subgroups 0)).fold("")(_ + _) replaceAll ("%2f", "/")
val newFilename = (newUrl split "/").last.toLowerCase
if (!newUrl.isEmpty && ((newFilename contains "kurzprofil") || (newFilename contains "projektliste")))
fetchDoc(newUrl)
}
} catch {
case e: Exception => println("[ ERROR ] " + url); e.printStackTrace; throw e
}
}
override protected def parse(url: String, rawTitle: String, utf8Html: String, utf8Text: String) {}
private def fetchDoc(url: String) = {
val filename = (url split "/").last.toLowerCase
val output = String.format("%s/%s/%s-%s", CRAWLER_STORAGE, controller.CLASS_NAME, myId.toString, filename)
val request = new HttpGet
request setURI new URL(url).toURI
val httpClient = new DefaultHttpClient(new PoolingClientConnectionManager)
val response = httpClient execute (request, controller.httpContext)
val outputStream = new FileOutputStream(output)
response.getEntity writeTo outputStream
outputStream.close
val data = parseDoc(output)
val doctype = if (filename contains "kurzprofil") "cv" else "projects"
val person = (PERSON_FROM_FILENAME findAllMatchIn filename map (_ subgroups 1)).fold("")(_ + _).toUpperCase
new File(output).delete
if (!person.isEmpty)
persist("CV", "url" -> url :: "person" -> person :: "text" -> data :: "doctype" -> doctype :: Nil)
}
private def parseDoc(file: String) = {
val handler = new BodyContentHandler(Int.MaxValue)
new AutoDetectParser().parse(new FileInputStream(file), handler, new Metadata, new ParseContext)
handler.toString
}
}2. Ein trainiertes Suchmodell
Die gesammelten Daten wurden folgend genutzt um ein Suchmodell zu trainieren. Dies ist erforderlich, um z.B. zusammengehörige Begriffe und Terme in Relation zu setzen. So soll für die Suche nach „Business Process Management“ zum Beispiel auch berücksichtigt werden, dass jemand der sich mit der „camunda Engine“ oder der „Oracle SOA Suite“ beschäftigt auch BPM Erfahrung hat. Warum? Weil diese Begriffe zusammen mit BPM bzw. Business Process Management signifikant häufig in den gleichen Dokumenten verwendet werden.
Beispielkorrelation für den Begriff „BPMN“
SELECT synonym, SUM(correlation) AS correlation
FROM "WordCorrelation"
WHERE to_tsvector('german', word) @@ plainto_tsquery('german', 'BPMN')
GROUP BY synonym;
synonym correlation
soa 0.64738
bpm 0.63298
suit 0.49102
camunda 0.43847
middlewar 0.39210
bpel 0.30738
entwickl 0.26837
adapt 0.19283
twi 0.16736
auotiv 0.14746
osb 0.13263
methodik 0.11273
continent 0.10973
oracl 0.10263
poc 0.10012In R führten wir mit den gesammelten Daten eine Hauptkomponentenanalyse durch, um Begriffe dessen relative Häufigkeit sich über alle Dokumente nur marginal unterschied zu entfernen und nur Begriffe zu behalten die für die Zuordnung eines Textes zu einem bestimmten Themencluster relevant sind. 120 solcher Themencluster konnten wir Bestimmen, für die wir dann die mittlere relative Vorkommenshäufigkeit der verbliebenden Begriffe ermittelten. So ergibt sich für jeden Cluster eine absteigende Folge der hierfür markanten Begriffe. Dies konnte im Folgeschritt genutzt werden, um für jedes Worte dessen Nähe zu jedem anderen Wort in jedem dieser Cluster zu ermitteln. Die daraus resultierende Ergebnismatrix kann dann genutzt werden, um für jede Wortkombination, sofern mindestens eines dieser Worte in unser Ergebnismatrix auftaucht, die hierzu ähnlichsten Begriffe mit der Bestimmung der Ü„hnlichkeit/Korrelation zu ermitteln.
3. Einen Such- & Scoringalgorithmus
Die eigentliche Suche, die primär erstmal eine Volltextsuche ist, welche jedoch das trainierte Modell nutzt, um nicht nach einem Begriff sondern nach einen Themenwolke zu suchen, bildet den Abschlusspunkt, um die gesammelten auf aufbereiteten Daten nutzbar zu machen. Gefundene Dokumente sollen dann nach Quelle, assoziierte Personen und Zusammenhang aggregiert werden, um durch einen adaptiven Scoring Algorithmus ein Ranking für die assoziierten Personen zu erstellen.
Die FTS Engine tsearch2 wurde verwendet, um für Volltextsuche notwenige Funktionalitäten wie Lexembildung (verschiedene Deklinations- bzw. Konjugationsformen des Suchwortes finden), Stemming (Wortstammbildung), Tokenization (Erkennung von Zusammengesetzten Begriffen und korrektes Trennen von Satzbausteinen sowie Interpretation von Satzzeichen) zu implementieren und das Framework zur Entwicklung eines Scoringmechanismus zu nutzen.
Das Scoring stellt das Kernqualitätsmerkmal dieser Suche da und dessen Entwicklung war daher auch eines der aufwändigsten Unterfangen dieses Projektes und muss vielerlei Dinge berücksichtigen:
- Die Mitarbeiter sind unterschiedlich lange im Unternehmen und es existiert dementsprechend unterschiedlich viel Inhalt zu ihnen. Daher sollen Inhalte immer über die Gesamtmenge an Inhalt zu einer Person relativiert werden.
- Einige Nutzer nutzen bestimmte Datenquellen garnicht (z.B. unser Forum) andere Datenquellen aber extrem häufig. Hier muss ein verhältnismäßiger ausgleich zwischen den Datenquellen bei extremer Nutzung geschaffen werden.
- Die Aktualität der Informationen muss eine Rolle spielen.
- Die Kommunikation zwischen WIssenzellen soll berücksichtigt werden. So wird ermittelt, wer z.B. im Forum mit wem über die gesuchte Thematik spricht. Über das Ranking geben Personen einen Teil ihres Ranks an Personen ab, mit denen sie über dieses Thema kommunizieren. So profitiert man beim Ranking davon mit den „Experten“ bzgl. des Suchterms in Kontakt zu stehen und quasi Teil dessen Kompetenz-Clusters zu sein.
Ausschnitt aus der Such- und Scoringquery
WITH qb1 AS (
SELECT
c.person,
c.source,
SUM(oc_rank(query_hard, c.text, c.timestamp) + oc_rank(query_soft, c.text, c.timestamp) / 10) AS rank,
COUNT(*) AS documents,
string_agg(c.text1 || ' ' || c.text2 || ' ' || c.text3 || ' ' || c.text4, ' ') AS text
FROM
"Content" c,
"PVS_Person" p,
search_to_tsquery_hard($1) query_hard,
search_to_tsquery_soft($1) query_soft
WHERE
query_soft @@ c.text AND
p.name = c.person AND
p.cu LIKE $2 AND
p.site LIKE $3
GROUP BY c.person, c.source),
qb2 AS (
SELECT
person,
source,
documents
FROM
"Content_Count")
SELECT
qb1.person,
SUM(qb1.rank / ln(qb2.documents + 10))::real AS rank,
SUM(qb1.documents)::integer AS documents,
string_agg(qb1.text, ' ') AS highlight
FROM qb1, qb2
WHERE qb1.source = qb2.source
AND qb1.person = qb2.person
GROUP BY qb1.person
HAVING SUM(qb1.rank / ln(qb2.documents + 10)) > 0.01
ORDER BY SUM(qb1.rank / ln(qb2.documents + 10)) DESCDa war doch noch was mit Datenschutz
Mit dieser Kernfunktionalität fehlte nur noch eine hübsche Suchoberfläche, um auch das Verhalten gewohnter Websuchmaschinen nachzuahmen, um dieses Werkzeug für jeden nutzbar zu machen. Einen Punkt darf man hierbei natürlich nicht unterschlagen, der auch für uns im Zusammenhang mit Big Data natürlich eine große Rolle spielt: Der Datenschutz. So hat jeder Mitarbeiter bei uns natürlich die Möglichkeit uns systemisch zu untersagen Daten über ihn aus einzelnen oder allen Quellen zu sammeln und auszuwerten.




