
")
In zwei vorangegangenen Artikeln von Falk Schramm wurden bereits einige Grundlagen zu generativer KI und RAG angesprochen. Mit meiner Artikelserie „To RAG or not to RAG“ möchte ich den Fokus noch einmal besonders auf diese Fragen bezüglich Retrieval Augmented Generation (RAG) richten:
- Welche Aufwände und Prozesse bringt RAG mit sich?
- Braucht es immer einen RAG-Ansatz? Wann ist er sinnvoll ist und wann vielleicht eher nicht?
Doch auch in dieser Serie fangen wir zunächst vorne an und ich erkläre, was RAG ist und wofür es eingesetzt wird. Wer sich hier bereits auskennt, darf natürlich gerne weiter unten einsteigen.
Was ist RAG?
RAG (Retrieval Augmented Generation) erweitert das „Wissen“ eines LLM (Large Language Model) durch Spezialwissen, welches sich nicht im gelernten Wissen eines LLM befindet oder nur unzureichend abgebildet ist, z. B. aufgrund des Veröffentlichungsdatums des LLM. Dieses Spezialwissen kann auch firmeninternes Wissen sein, das in Form von Dokumenten in Formaten wie PDF, DOCX oder MD (Markdown) vorliegt. Wenn es für die Bearbeitung durch ein LLM bereitgestellt werden soll, muss es in eine Form gebracht werden, die das Modell versteht. Dafür eignen sich sogenannte Vektor-Datenbanken. Über eine semantischen Suche können hier große Mengen an Text verfügbar gemacht werden. So können relevante Textteile bereitgestellt werden, die ein LLM braucht, um seine Antworten zu generieren.
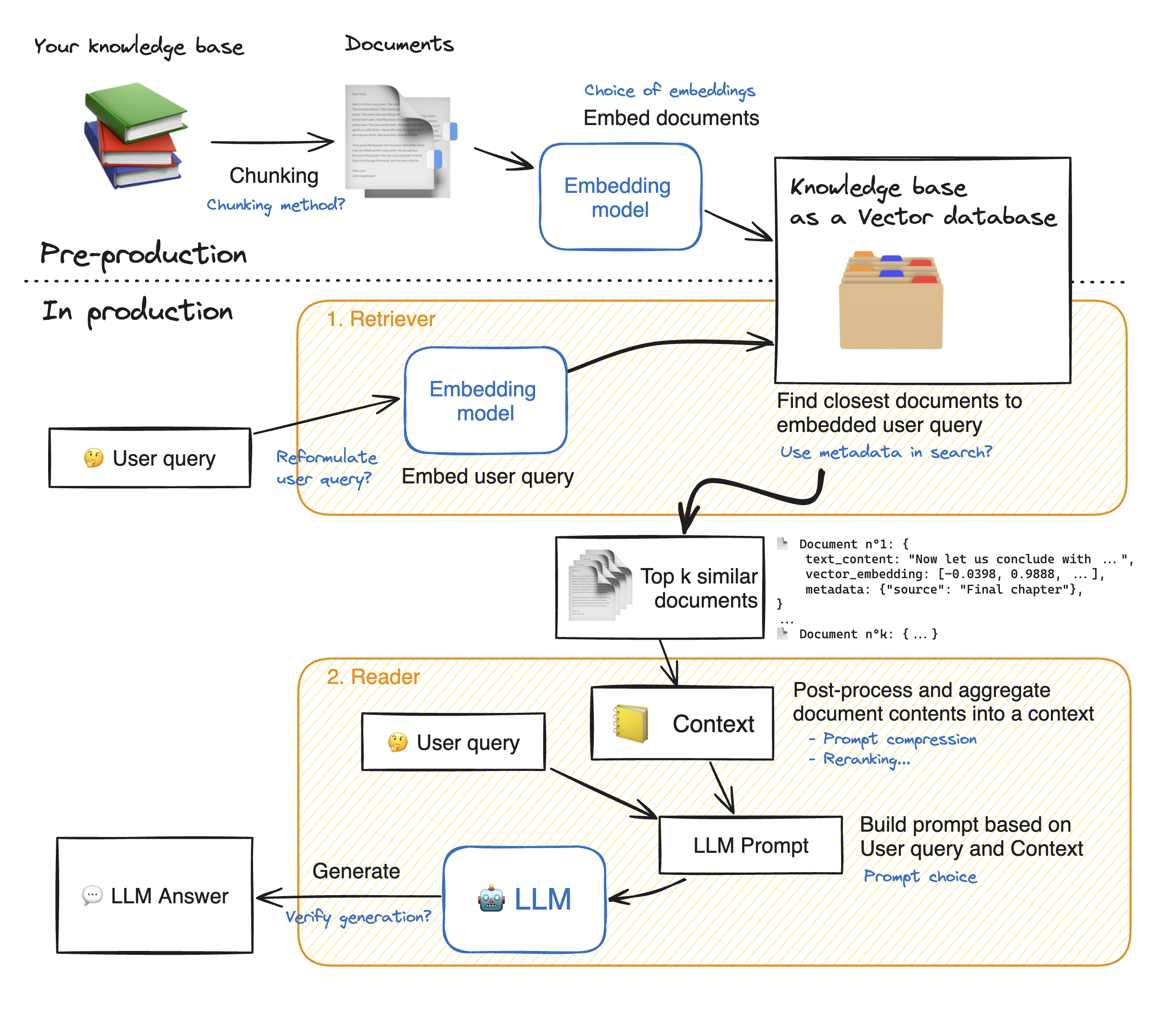
Abbildung 1: Die Schritte vom Wissen zur Antwort (Bild-Quelle: https://huggingface.co/learn/cookbook/advanced_rag):
- Dokumente werden zunächst zerteilt (chunking),
- in einen Vektor überführt (embedding)
- und dann in der Vektordatenbank abgespeichert.
- Bei der Abfrage (query) werden zunächst relevante Chunks in der Vektordatenbank gesucht (similarity search)
- und die besten Matches (top k) dem Kontext hinzugefügt.
- Aus diesen Inhalten generiert das LLM nun seine Antwort.
Warum RAG?
Wenn es nur darum ginge, ein Dokument in den Kontext des LLM zu stellen und es analysieren zu lassen, wäre es einfach. Doch leider gibt es technische Einschränkungen: Das Modells kann nämlich nur eine limitierte Menge an Informationen verarbeiten.
Deshalb kann es nützlich sein, wenn man große Mengen an Informationen auswerten möchte, diese in semantische Blöcke aufzuteilen. Mittels RAG lassen sich diese vorselektieren und passend zur gewünschten Aufgabe auswählen.
Welche Begrenzung gibt es genau?
Ein wichtiger Begriff, wenn wir über die Begrenzung der Informationsmenge sprechen, ist das Kontextfenster: Es begrenzt die Anzahl der Token, die von einem Modell verarbeitet werden können. Dabei müssen die Eingabe- und Ausgabe-Token zusammengerechnet werden, um die Grenzwerte einzuhalten. Die Kontextfenster der aktuellen Modelle haben sich erheblich erweitert:
| Modell | Kontextfenster in Tokens | entspricht Text |
| GPT-3 | 2.000 | ca. 2-3 Seiten |
| GPT-3.5-Turbo Instruct | 4.000 | ca. 3.000 Worte (englisch), 6 Seiten |
| Mistral Tiny (7B) | 8.000 | ca. 6.000 Worte, 12 Seiten |
| GPT-4 | 8.000 | ca. 6.000 Worte, 12 Seiten |
| Llama 3 | 8.192 | ca. 6.000 Worte, 12 Seiten |
| GPT-3.5 Turbo | 16.000 | ca. 12.000 Worte, 24 Seiten |
| Mistral Small | 16.000 | ca. 12.000 Worte, 24 Seiten |
| Mistral Medium | 32.000 | ca. 24.000 Worte, 48 Seiten |
| Gemini Pro | 32.000 | ca. 24.000 Worte, 48 Seiten |
| GPT-4-32k | 32.000 | ca. 24.000 Worte, 48 Seiten |
| Claude 2 | 100.000 | ca. 75.000 Worte, 150 Seiten |
| GPT-4-Turbo | 128.000 | ca. 96.000 Worte, 192 Seiten |
| Llama 3.1 | 128.000 | ca. 96.000 Worte, 192 Seiten |
| Claude 2.1 | 200.000 | ca. 150.000 Worte, 300 Seiten |
| Gemini 1.5 | bis zu 1.000.000 | ca. 750.000 Worte, 1500 Seiten |
Demgegenüber stehen aber auch unterschiedliche Kosten, die zu berücksichtigten sind. Diese sind von Anbieter zu Anbieter verschieden, daher können wir diese hier nicht im Einzelnen darstellen. Quellen im Internet finden sich leicht.
Nun stellt sich die Frage: Setze ich auf größere Kontextfenster? Oder arbeite ich mit kleinen Kontextfenstern, und setze auf semantische Suche? Hier die drei wichtigsten Vor- und Nachteile beider Varianten auf einen Blick sowie passende Anwendungsfälle:
Größere Kontextfenster – Vorteile
- Verbesserte Kohärenz bei langen Inhalten: Größere Kontextfenster ermöglichen es dem Modell, mehr Informationen zu speichern und zu verarbeiten, was für die Erstellung kohärenter und detaillierter Antworten in langen Dokumenten oder Gesprächen unerlässlich ist. Dies ist vorteilhaft für Anwendungen wie das Zusammenfassen langer Artikel, das Erstellen juristischer Verträge oder die Bearbeitung langer Kundensupport-Chats, bei denen Kontinuität entscheidend ist.
- Verbesserte Informationsspeicherung: Mit einem größeren Fenster können LLMs mehr historische Eingaben referenzieren, wodurch sie den Kontext über lange Interaktionen hinweg beibehalten können. Dies ist nützlich für Konversations-Agenten, für die Beantwortung von Fragen, die mehrere Runden umfassen, oder für die Zusammenfassung umfassender Berichte.
- Geringerer Bedarf an Kürzung: Bei umfangreichen Texten müssen bei kleineren Kontextfenstern oft Teile der Eingabe gekürzt oder ausgelassen werden, was zu unvollständigen oder ungenauen Antworten führen kann. Ein größeres Fenster kann einen größeren Teil des Eingabetextes umfassen, wodurch das Risiko verringert wird, wichtige Details zu übersehen.
Größere Kontextfenster – Nachteile
- Höhere Rechenkosten: Die Verarbeitung größerer Kontextfenster erfordert mehr Rechenressourcen, was zu längeren Antwortzeiten und höheren Kosten führt. Dies kann sich bei Echtzeitanwendungen oder bei begrenztem Budget negativ auswirken.
- Erhöhtes Risiko irrelevanter Informationen: Ein größeres Fenster kann auch mehr irrelevante Inhalte enthalten, die das Modell ablenken und die Qualität der Antwort beeinträchtigen können. Modelle mit großen Kontextfenstern müssen sorgfältig geführt werden, um sich auf die wichtigsten Teile der Eingabe zu konzentrieren.
- Komplexität in der Prompt-Entwicklung: Größere Kontextfenster können die Gestaltung von Prompts komplexer machen. Denn es ist herausfordernd, umfangreiche Eingaben kohärent zu strukturieren. Prompt-Designer müssen die enthaltenen Informationen sorgfältig abwägen, um das Modell nicht mit überflüssigen Details zu überfrachten.
Kleinere Kontextfenster – Vorteile
- Geringere Latenz und Kosteneffizienz: Kleinere Kontextfenster erfordern weniger Rechenressourcen, was zu schnelleren Verarbeitungszeiten und niedrigeren Betriebskosten führt. Dies ist vorteilhaft für Anwendungen, die zahlreiche Anfragen schnell bearbeiten müssen.
- Gezielte Antworten: Ein kleineres Fenster kann dazu beitragen, den Fokus des Modells auf den unmittelbarsten und relevantesten Kontext einzugrenzen, wodurch die Gefahr der Einführung von nicht verwandten Inhalten verringert wird. Dies ist oft von Vorteil bei Anwendungen wie dem kurzen Austausch mit dem Kundensupport oder schnellen Antworten in Q&A-Systemen.
- Einfachheit in der Implementierung: Bei kleineren Fenstern ist die Erstellung von Eingabeaufforderungen in der Regel einfacher. Die Gefahr, das Modell mit fremden Informationen zu überfrachten, ist geringer, was die Einrichtung erleichtert und oft zu konsistenteren Antworten führt.
Kleinere Kontextfenster – Nachteile
- Begrenzte Informationskapazität: Der größte Nachteil kleinerer Kontextfenster ist die geringere Informationskapazität. Dies kann zu unzusammenhängenden oder sich wiederholenden Antworten führen, wenn das Modell nicht in der Lage ist, ausreichend Kontext über eine lange Eingabe zu speichern.
- Häufiges Abschneiden in großen Dokumenten: Bei einem begrenzten Token-Limit müssen kleinere Fenster häufig abgeschnitten werden, was dazu führen kann, dass kritische Details ausgelassen werden, was die Qualität der Antworten in Anwendungen, die eine umfassende Analyse oder Synthese großer Texte erfordern, verringert.
Anwendungsfälle für größere Kontextfenster
Bestimmte Anwendungen eignen sich besser für größere Kontextfenster, insbesondere bei der Verarbeitung umfangreicher Textdaten oder wenn die Beibehaltung von Informationen über lange Eingaben unerlässlich ist:
- Dokumentenzusammenfassung: Bei der Zusammenfassung langer Inhalte, wie z. B. Forschungsarbeiten oder juristische Dokumente, muss das Modell umfangreichen Text ohne Abschneiden berücksichtigen, was von einem größeren Kontextfenster erheblich profitieren kann.
- Detaillierte Konversationen: In Anwendungen für den Kundensupport oder virtuelle Assistenten, bei denen die Benutzer längere Interaktionen mit mehreren Umdrehungen durchführen, hilft ein größeres Kontextfenster dem Modell, die Kontinuität und den Kontext der Konversation über die Zeit zu erhalten.
- Datenextraktion und -analyse: In Fällen, in denen das Modell Informationen aus großen Datensätzen oder Dokumenten extrahiert, z. B. aus medizinischen Berichten oder Jahresabschlüssen, stellt ein größeres Kontextfenster sicher, dass keine wichtigen Informationen ausgelassen werden.
Anwendungsfälle für kleinere Kontextfenster
Kleinere Kontextfenster können dagegen gut in Anwendungen funktionieren, die schnelle Antworten benötigen, bei denen die Ressourcen begrenzt sind oder bei denen knappe Informationen ausreichen:
- Echtzeit-Q&A-Systeme: Anwendungen, die einfache Fragen beantworten, können oft effektiv in kleineren Kontextfenstern funktionieren. Beispiele hierfür sind schnelle Fragen des Kundendienstes oder einfache FAQ-Bots.
- Klassifizierung von Kurztexten: Aufgaben wie Spam-Erkennung, Stimmungsanalyse oder Kurztextklassifizierung erfordern keine umfangreichen Kontextfenster. Das Modell muss nur kurze Nachrichten oder Phrasen verarbeiten, weshalb ein kleineres Kontextfenster ideal ist.
- Transaktionsbezogene Interaktionen: Anwendungen, die kurze, transaktionale Interaktionen verarbeiten (z. B. Restaurantreservierungen oder Wetteraktualisierungen), benötigen im Allgemeinen keinen umfangreichen Kontext. Kleinere Fenster rationalisieren die Antworten und reduzieren die Verarbeitungszeit.
Quelle: Medium Artikel „Understanding Context Windows in LLMs“, Tahier Saeed
Welche Rolle spielt die Performance?
Große Informationsmengen enthalten natürlich nicht immer nur relevante Inhalte zu einer bestimmten Fragestellung. Es ist daher vorteilhaft, zunächst die Inhalte zu ermitteln, die mit der Anfrage in Zusammenhang stehen. Insbesondere für die Performance der Anwendung ist dies enorm wichtig.
Hier hilft der RAG-Ansatz: Basierend auf einer Ähnlichkeitssuche (Similarity Search) werden nur jene Inhalte in das Kontextfenster importiert, die in einem relevanten Zusammenhang mit der Anfrage stehen. Diese Suche findet statt, bvor das LLM eine Antwort generiert. Sie ist ein rein mathematischer Vergleich von Vektoren und damit viel performanter, als die Auswertung der gesamten Datenmenge.
Daraus resultieren
- ein reduzierter Tokenverbrauch,
- eine geringere Netzwerklatenz
- und damit schnellere Reaktionszeiten bei der Generierung der Antwort.
Vektordatenbanken sind auf diese Suche spezialisiert. Es gibt Extensions für bekannte Datenbanksysteme wie Postgres oder Oracle, aber auch speziell für diesen Zweck entwickelte Datenbanken wie Weaviate oder Chroma (beide Open Source) und auch kommerzielle Produkte.
Fazit: Wann setzte ich RAG ein?
So kommt man schlussendlich zu der Frage: Benötige ich für meinen Anwendungsfall ein RAG oder nicht? Welche Aspekte müssen dabei berücksichtigt werden?
Wie groß sind meine Daten/Dokumente?
Macht eine Zerlegung Sinn, oder passen sie einfach in ein Kontext-Fenster des LLM meiner (Kosten-)Vorauswahl.
Wie volatil sind die Daten/Inhalte? Werden sie oft geändert, oder sind sie statisch?
Bei sich oft ändernden Daten muss man sich überlegen, ob das erneute Verarbeiten der Ausgangsdaten durch eine andere Speicherung und Filterung verbessert werden kann. Hier ist vielleicht die Vektordatenbank nicht unbedingt das geeignete Mittel. Durch den Einsatz sogenannter Tools im LLM kann auch auf andere Datenbanken mit eigenen Filter Werkzeugen zugegriffen werden (ElasticSearch, OpenSearch, Solr, …).
Handelt es sich um strukturierte oder unstrukturierte Inhalte?
Strukturierte Inhalte lassen sich gut zerlegen und in einer Vektordatenbank abspeichern. Unstrukturierte Inhalte verlangen unter Umständen viel Probieren, um die optimalen Zerlegungsparameter zu bestimmen. Wenn die Dokumentgröße und die Kosten es zulassen, könnte es hier einfacher sein, das Dokument direkt an das LLM zu übergeben.
Wie langlebig oder kurzlebig sind meine Daten und Dokumente (Gültigkeitsdauer, Ablaufdatum)?
Kurzlebig gültige Daten sollten aus Gründen der Performance der Vektordatenbank nach Ablauf der Gültigkeit wieder entfernt werden. Hier ist der jeweilige Aufwand dafür abzuschätzen. Bei kleineren Dokumenten kann auch hier ggf. auf ein RAG verzichtet werden.
Wie oft greife ich auf diese Daten mit Hilfe der KI zu?
Wenn viele Zugriffe auf die gleichen Daten erfolgen, hat das RAG einen Vorteil, da es Rechenleistung beim LLM einspart, und somit die Antwortzeiten und Kosten geringhält.
Wenn die Daten nur selten oder sogar nur einmalig ausgewertet werden sollen, kann auch hier eine Vektordatenbank unter Umständen gar nicht erforderlich sein.
Weiterlesen …
Wenn ein RAG zum Tragen kommen soll oder muss, kommt der Pre-Production-Prozess aus Abbildung 1 (siehe oben) zum Einsatz.
Lesen Sie im zweiten Teil dieser kleinen Artikelserie:
- Wie die Prozessschritte im Einzelnen aussehen
- und worauf dabei zu achten ist



