

Chatbots für Spezialwissen – Teil 1: Konzepte
Wenn es um Chatbots geht, geistern seit einige Zeit Begriffe wie Retrieval Augmented Generation (RAG), Semantische Suche und Large Language Model (LLM) durch die Medien. Mit Hilfe dieser Techniken sollen Chatbots Fragen beantworten können, auf die herkömmliche Suchmaschinen keine oder nur unzureichende Antworten anbieten. Was steckt dahinter?
In diesem Zweiteiler möchte ich zunächst kurz vorstellen, was genau sich hinter RAG, Semantischer Suche und den Prompts des LLM verbirgt. Anschließend werden Implementierungsansätze und Herausforderungen beim produktiven Einsatz beleuchtet. Wir haben die Techniken selbst ausprobiert und teilen unsere Erfahrungen mit Ihnen.
Teil 1: Was Sie über Retrieval Augmented Generation, Semantische Suche und Prompts wissen sollten: Versuch einer verständlichen Erklärung
In weiteren Artikeln gehen wir auf tiefergehende Erfahrungen und Lösungsansätze mit unterschiedlichen Implementierungen und Technologien ein.
Retrieval Augmented Generation
Öffentlich verfügbare LLM (wie z.B. das vielzitierte ChatGPT) besitzen auf Grund ihres Trainings eine große Menge an Allgemeinwissen. Obwohl dieses Wissen nicht immer korrekt und vollständig ist, reicht es für eine unverbindliche Unterhaltung locker aus. Für den produktiven Einsatz sind Korrektheit und Vollständigkeit der Antworten eines Chatbots jedoch unverzichtbare Kriterien. Man denke beispielsweise an einen Chatbot, der auf Anfragen von Kunden reagiert.
Am Beispiel des Chatbots für Kundenanfragen lässt sich auch eine weitere Problematik veranschaulichen: Trotz des umfangreichen Allgemeinwissens besitzt ein LLM kein Spezialwissen über das Angebot eines Unternehmens. Dieses Spezialwissen muss für den Chatbot in Form einer Wissensbasis verfügbar gemacht werden.
Das durch einen Chatbot zu erschließende Spezialwissen ist dabei nicht auf Angebote eines Unternehmens beschränkt: Informationen aus dem Intranet, interne Dokumente, externe Standards (DIN, ISO etc.) , Tickets zu Supportanfragen, Foren und vieles mehr kommt als Quelle für Spezialwissen in Frage.
Die Nutzung von Spezialwissen zur Beantwortung von Anfragen ist der Use Case für Retrieval Augmented Generation (RAG). Dahinter steckt die Idee, dass das LLM die Eingabe des Nutzers nicht direkt beantwortet. Stattdessen werden vorher aus der Wissensbasis relevante Informationen (Textstellen) als Kontext für die Beantwortung der Nutzereingabe extrahiert. Das LLM wird angewiesen, diesen Kontext für die Beantwortung zu verwenden und sein Allgemeinwissen nicht oder erst in zweiter Linie zu nutzen.
Die folgende Grafik illustriert die Schritte, die im Einzelnen durchlaufen werden.
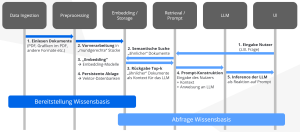 Semantische Suche
Semantische Suche
Die Auswertung der Wissensbasis und das Ermitteln der relevanten Kontexts ist Aufgabe der Semantischen Suche. Eine einfache Stichwortsuche à la Google reicht nämlich typischerweise nicht aus: Der Nutzer formuliert seine Anfrage umgangssprachlich und in seinen eigenen Worten. Er kennt und verwendet möglicherweise nicht die „richtigen“ Stichwörter.
Eine numerische Bewertung, wie ähnlich sich zwei Texte im Hinblick auf ihren Inhalt sind, ist eine seit langem untersuchte Fragestellung in der Linguistik. Im Kontext der Sprachverarbeitung durch Computer (NLP, Natural Language Processing) erfolgt diese Bewertung anhand von Embeddings. Dafür wird ein Text in einen Zahlenvektor umgewandelt und so, mathematisch gesprochen, der Text in einen Vektorraum „eingebettet“ (engl. Embedding). Diese Vektorräume besitzen im Unterschied zu unser 3-dimensionalen Welt höhere Dimensionen. Typische Werte sind etwa 768, 1024 oder 1536.
Der Abstand zwischen zwei Texten lässt sich nun als Abstand der Textvektoren numerisch berechnen. Die „Magie“ des Embeddings besteht darin, dass inhaltlich ähnliche Texte in Textvektoren umgewandelt werden, die kleine Abstände voneinander haben. Beispielsweise werden die Texte „Ich mag meinen Hund“ und „Ich mag meinen vierbeinigen Freund.“ einen kleineren Abstand besitzen als die Texte „Ich mag meinen Hund.“ und „Ich mag indisches Essen.“
Für die semantischen Suche wird die Eingabe des Nutzers mit Hilfe des Embeddings in einen Textvektor umgewandelt und mit den Vektoren aus der Wissensbasis verglichen. Die der Eingabe am nächsten liegenden Vektoren/Texte werden als Ergebnis der semantischen Suche zurück geliefert.
Wie Embeddings genau funktionieren, kann hier nicht dargestellt werden. Embeddings sind ein sich schnell entwickelndes Thema der aktuellen Forschung. Für den interessierten Leser empfehlen wir die Webseite SBERT und das METB-Leaderboard der Plattform HuggingFace als Einstieg in eine Vertiefung.
Prompts: Anweisungen an das LLM
LLM sind im Kern nur eine komplexe statistische Methode, um aus einer natürlich sprachigen Eingabe, dem Prompt, eine Ausgabe zu erzeugen. Im Falle von Retrieval Augmented Generation besteht der Prompt aus der Nutzereingabe, dem ermittelten Kontext und Anweisungen für die Beantwortung.
Warum sind Anweisungen notwendig? Genau wie Menschen brauchen LLMs eine klare Aufgabenbeschreibung: Wie soll geantwortet werden, wenn der Kontext für die Beantwortung einer Frage nicht ausreicht? Wie soll mit Anfragen umgegangen werden, die sich nicht auf die Wissensbasis beziehen? Wie soll geantwortet werden, wenn der Nutzer nach einem Konkurrenzprodukt fragt? Dies und weitere Fragen sind für den produktiven Einsatz eines Chatbots zu klären.
Welche Anweisungen dem LLM gegeben werden, hängt vom jeweiligen Use Case und den Nutzern des Chatbots ab: Wenn die Nutzer des Chatbots Kunden eines Unternehmens sind, werden an Korrektheit, Vollständigkeit und Verhalten bei „Out-of-Topic“ Anfragen hohe Anforderungen gestellt.
Wenn die Nutzer des Chatbots dagegen ein internes Expertenteam sind (z.B. eine Fachabteilung), könnte beispielsweise die Behandlung von „Out-of-Topic“ Anfragen ausgelassen werden. Auch Anforderungen an Vollständigkeit und Korrektheit stellen sich möglicherweise anders dar.
Das Verständnis dieser weniger Konzepte reicht bereits aus, um die grundlegende Funktion von Chatbots mit Spezialwissen zu verstehen. Wie schlagen sich diese Konzepte in der Praxis? Welche Herausforderungen und Lösungsansätze gibt es?
In weiteren Artikeln gehen wir auf tiefergehende Erfahrungen und Lösungsansätze mit unterschiedlichen Implementierungen und Technologien ein.
RAG or not to RAG, Teil 1: Wann braucht es einen RAG-Ansatz
RAG or not to RAG, Teil 2: Prozesse und Aufwand in der Praxis
Was steckt hinter RAG und Semantischer Suche?
RAG und Semantische Suche in der Praxis



