

Immer mehr Unternehmen setzen Methoden des maschinellen Lernens und der natürlichen Sprachverarbeitung ein, um aus Textdaten einen wirtschaftlichen Nutzen zu ziehen. So auch die Expert.ai, die sich im Bank und Versicherungssektor mit sprachgetriebenen AI-Lösungen mittlerweile einen Namen gemacht hat. Um Talente anzulocken, hatte die Expert.ai im Herbst 2022 für den Hackathon „Turn Language into Action: a Natural Language Hackathon for Good“ 10.000 Dollar als Preisgeld und für hochkarätige Trainingsgutscheine ausgeschrieben.
Das Geld war das eine, aber für uns gab es definitiv andere Gründe, warum wir im September 2022 bei dem Event dabei sein wollten. Neben der Challenge und dem Austausch mit Fachleuten waren drei Dinge für uns besonders spannend:
- Die Analysemöglichkeiten der Expert.ai Natural Language API ausprobieren
- Einen eigenen ML-Algorithmus zur Textklassifikation entwickeln
- Das Open-Source-App-Framework Streamlit testen
Wie schon angedeutet ist Expert.ai ein führendes Unternehmen im Bereich Natural Language Understanding. Beim Hackathon ging es natürlich nicht nur darum, Talente anzulocken, das war etwas lapidar, ich gebe es zu!
Dem Unternehmen ging es darum, etwas Gutes zu bewegen und mit der expert.ai Natural Language API eine Anwendung mit gesellschaftlichem Mehrwert zu entwickeln. So lassen sich über die API unter dem Einsatz von Natural Language Processing und Künstlicher Intelligenz beispielsweise bestimmte Emotionen in Texten auffinden, bestimmte Themen oder Hassreden erkennen. Das kann für die Gesellschaft wichtig sein.
Tweet Depression Detector: Eine App, die bedrückende Tweets entdeckt
Unsere Idee für den Hackathon war die Entwicklung einer App namens „Tweet Depression Detector“. Diese App sollte in der Lage sein, depressive Tendenzen und Emotionen in den sozialen Medien aufzufinden. Der gesellschaftliche Mehrwert wäre groß: Immer mehr Menschen entwickeln Depressionen, und ihre Anzahl nimmt stetig zu. Äußere Faktoren wie Inflation und die Pandemie verstärken diesen Trend. Auch die Nutzung von sozialen Netzwerken kann Auslöser von Depressionen sein. Die App kann natürlich keine ärztliche Diagnose oder den Weg zum Therapeuten ersetzen. Aber sie gibt Hinweise auf Tweet-Texte und zeigt Häufungen an, sodass betroffenen Personen Hilfe angeboten werden könnten.
So wollten wir vorgehen
Um unseren Textklassifikationsalgorithmus für die Erkennung von depressiven Tendenzen zu trainieren, wollten wir verschiedene Trainingsdatensätze der Data Science-Plattform Kaggle verwenden. Zusätzlich sollte die Verwendung der Expert.ai API unserer App dabei helfen, 39 verschiedene Emotionen aus Texten herauszufiltern.
Über ein Dashboard – das wir mit Streamlit, einem Open-Source-Framework für Machine Learning and Data Science Entwickler, entwickeln wollten – sollte eine Person Tweets eingeben und auf depressive Tendenzen überprüfen können. Diese Tweets werden dafür im Backend der App von einem Machine-Learning-Modell und der Expert.ai API analysiert. Bei Streamlit handelt es sich um eine Open-Source-Bibliothek, mit der Machine-Learning-Modelle schnell und einfach integriert und ansprechende Dashboards gestaltet werden können.
Was kann die Expert.ai Natural Language API?
Expert.ai, der Veranstalter des Hackathons, bietet wie gesagt KI-Technologien im Bereich Natural Language Understanding an, um sprachenintensive Prozesse zu automatisieren und Mehrwerte aus Sprachdaten zu generieren. Die Expert.ai Natural Language API ist ein Cloud-basierter REST-Dienst, der folgende KI-unterstützenden Funktionen bereitstellt:
- Textkategorisierung: Klassifizierung von Texten in verschiedene Themenbereiche
- Entitätenerkennung: Erkennung von Personen, Orten, Organisationen und anderen relevanten Entitäten in Texten
- Emotionserkennung: Erkennung von Emotionen in Texten
- Textzusammenfassung: Automatische Erstellung von Zusammenfassungen langer Texte
- Übersetzung: Übersetzung von Texten in verschiedene Sprachen
- Textgenerierung: Automatische Erstellung von Texten auf Basis von vorhandenen Texten oder Textmustern
Wie lässt sich die API für die Textklassifikation in unserer App nutzen?
Die Emotionserkennung von Expert.ai ergänzt die Depressionserkennung in unserer App. Abbildung 1 zeigt die 39 verschiedenen erkennbaren Emotionen und die zugehörigen Hauptkategorien:

Abbildung 1: Identifizierbare Emotionen durch die Expert.ai Natural Language API
Im folgenden Code seht ihr ein Beispiel dafür, wie die API verwendet werden kann, um Emotionen aus einem Text zu extrahieren:
from expertai.nlapi.cloud.client import ExpertAiClient
client = ExpertAiClient()
def emotional_trait_analysis(text, taxonomy="emotional-traits",language="en"):
output = client.classification(body={"document": {"text": text}},
params={'taxonomy': taxonomy, 'language': language})
print("List of emotions found in the text:")
for category in output.categories:
list_of_labels = [
{
"emotional_categories": category.hierarchy[0],
"emotional_labels": category.label,
"emotional_score": category.score
}
]
return list_of_labels
Die API nimmt als Eingabe einen zu analysierenden Text und eine Sprachdefinition entgegen. Als Ergebnis wird eine Liste zurückgespielt, die für jede im Text gefundene Emotion bestimmte Eigenschaften enthält, wie: Um welche Emotion handelt es sich? Wie häufig wurde sie entdeckt? Außerdem werden Punkte vergeben und die Emotion einer Kategorie zugeordnet.
Ein Beispiel:
It is 2 o’clock in the morning. Awake but tired. I need to sleep but my brain has other ideas… i hate my live 🙁
In diesem Tweet entdeckt die API die Emotion „Hass“ aus der Kategorie „Ressentiments“ .
Vorteile und Schwächen der API
Die Installation und Einrichtung der Expert.ai Natural Language API erfolgte mit Python. Die verfügbare Dokumentation half uns dabei, dies schnell und einfach zu realisieren. Auch die Implementierung der verschiedenen Analysen war dank der Dokumentation unkompliziert.
Eine Schwäche zeigte sich allerdings auch: Die Rückgabewerte sind etwas schwer verständlich, unzureichend beschrieben und teilweise auch unvollständig. Das führte zum Beispiel dazu, dass der Score einer Emotion nicht weiterverwendet werden konnte.
Schritt für Schritt zur „fähigen“ App
Das Training kann beginnen …
Wie gesagt, sollte es das Ziel unserer App sein, depressive Äußerungen in Sozialen Netzwerken zu identifizieren. Dafür muss die App Tweets nach depressiven und nicht depressiven Tendenzen unterscheiden, also klassifizieren können. Dabei hilft ihr ein Algorithmus, der sich nach anfänglichem Training immer weiter verbessert. Unsere Aufgabe bestand also darin, ein solches Machine-Learning-Modell zu entwickeln. Dafür haben wir verschiedene Kaggle-Datensätze kombiniert, vorverarbeitet und mit Hilfe der Expert.ai API angereichert.
Texte klassifizieren
Für das Trainieren der Machine-Learning-Modelle benutzten wir die drei Datensätze, die auf der Website Kaggle bereitgestellt werden:
- Twitter Dataset + Feature Extraction
- Sentimental Analysis for Tweets
- Twitter Depression Dataset
Nachdem die verschiedenen Datensätze zusammengeführt wurden, ergab sich eine Gesamtzahl von 67.084 Tweets. Davon enthielten 32.230 Tweets Anzeichen von Depressionen, während 34.854 Tweets keine solchen Anzeichen aufweisen. Dies führt zu einer relativ ausgeglichenen Verteilung der Tweets in Bezug auf die beiden Klassen innerhalb unseres Datensatzes.
Um ein valides Modell zu trainieren und zu testen, teilten wir den Datensatz in eine Trainings- und eine Testdatenmenge auf. 80 % des Datensatzes wurden als Trainingsdaten verwendet, während die restlichen 20 % als Testdaten dienten. So konnte wir testen, ob unser Modell auch auf unbekannten Daten sicher funktioniert.
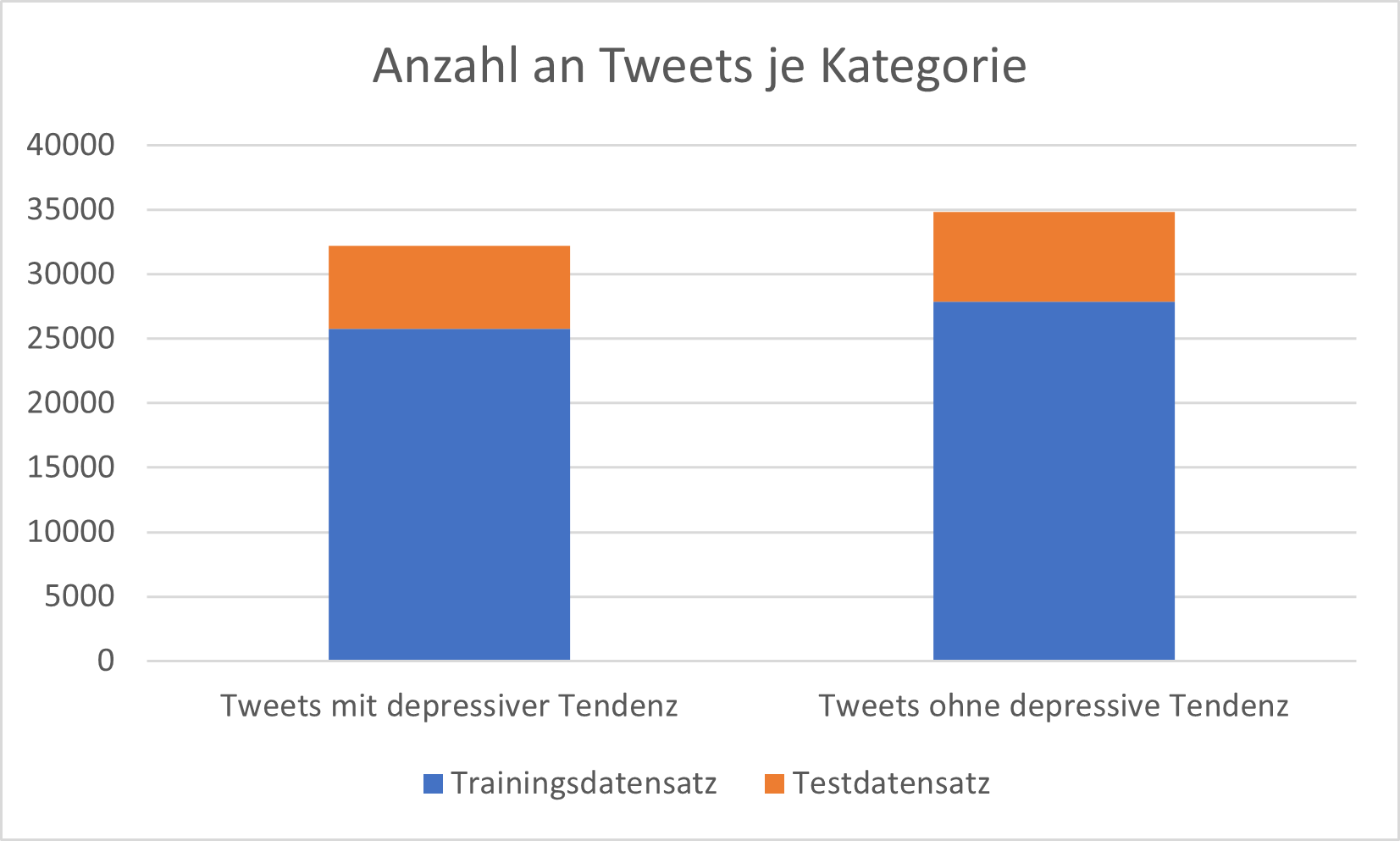 Abbildung 2: Verteilung der Anzahl an Tweets auf die Klassen „Tweets mit depressiver Tendenz“ und „Tweets ohne depressive Tendenz“
Abbildung 2: Verteilung der Anzahl an Tweets auf die Klassen „Tweets mit depressiver Tendenz“ und „Tweets ohne depressive Tendenz“
Zur Veranschaulichung der Trainingsdaten zeigt Abbildung 3 zwei Beispiele. Im Datensatz sind die Tweets in zwei Kategorien eingeteilt: „1“ steht dabei für Tweets mit depressiven Tendenzen und „0“ für Tweets ohne depressive Tendenzen.
| Text | Label |
| „It is 2 o’clock in the morning. Awake but tired. I need to sleep but my brain has other ideas… i hate my live 🙁„ | 1 |
| „just had a real good moment. i missssssssss him so much“ | 0 |
Daten vorverarbeiten
Textdaten haben im Allgemeinen eine sehr hohe Anzahl von Merkmalen aufgrund der Vielzahl von Wörtern. Einfache Algorithmen des maschinellen Lernens stoßen bei solch hochdimensionalen Daten an ihre Grenzen. Deshalb kann es beim Natural Language Processing hilfreich sein, die Anzahl der Wörter so weit wie möglich zu reduzieren und die Daten mit ein paar Kniffen auf die Weiterverarbeitung vorzubereiten.
Die folgenden Vorverarbeitungsschritte haben wir auf unseren Datensatz angewandt:
- Konvertierung in Kleinbuchstaben
- Entfernung von Satzzeichen und bestimmten Sonderzeichen
- Entfernen von sogenannten Stopwords mit wenig Bedeutung (z. B. „at“ oder „on“)
- Lemmatisierung: das heißt, unterschiedliche Wortformen wie „changed“, „changes“ oder „changer“ werden durch das einfache Wort „change“ ersetzt.
Betrachten wir wieder unseren bereits bekannten Beispielsatz:
It is 2 o’clock in the morning. Awake but tired. I need to sleep but my brain has other ideas… i hate my live 🙁
Nach Anwendung dieser Schritte ergibt sich dieser vereinfachte Tweet:
oclock morning awake tire need sleep brain idea hate live
Abschließend werden die bereinigten Tweets in eine Wort-Dokument Matrix transformiert. Jede Zelle in dieser Matrix enthält die Häufigkeit eines bestimmten Wortes für einen bestimmten Tweet. Diese Matrix wird als Feature-Input für das Training des Machine-Learning-Modells verwendet. Wenn ihr mehr über die Vorverarbeitung von Textdaten lesen möchtet, findet ihr hier einen interessanten Blogeintrag dazu (Link).
Algorithmus und Modell trainieren
Als Machine-Learning-Modell zur Klassifizierung von Tweets in Depression (=1) oder Nicht-Depression (=0) haben wir uns für den Naive Bayes-Algorithmus entschieden. Dieses probabilistische Lernmodell basiert auf dem Bayes-Theorem und hat einige Vorteile:
- Relativ einfach und gut interpretierbar
- Relativ geringe Anzahl an Trainingsdaten notwendig
- Tendiert nicht zu Overfitting
- Gute Performance in vielen Anwendungen (oft als Baseline-Algorithmus in Projekten benutzt)
Der Algorithmus basiert auf der Annahme, dass jedes Merkmal (in diesem Fall jedes Wort) in einem gegebenen Text unabhängig von den anderen Merkmalen ist. Diese Annahme ist oft nicht ganz richtig, aber es ermöglicht dem Algorithmus, schnell Schätzungen über die Wahrscheinlichkeiten zu berechnen und Vorhersagen zu treffen.
In der Praxis hat sich gezeigt, dass der Naive Bayes Algorithmus oft gute Ergebnisse erzielt und für viele Anwendungen wie Spamfilterung, Sentimentanalyse und Textkategorisierung geeignet ist. Es ist jedoch zu beachten, dass es auch moderne Methoden gibt die besser für Textklassifikation geeignet sind, zum Beispiel die Verwendung von tiefen neuronalen Netzen (Deep Neural Networks) und die Verwendung von Word-Embeddings. Deshalb wird Naive Bayes oft als Basismodell verwendet, um komplexere Methoden damit zu vergleichen.
Eine erste Implementierung des Algorithmus kann mit Machine-Learning-Bibliotheken wie sklearn sehr einfach erstellt und trainiert werden:
from sklearn.naive_bayes import MultinomialNB model_MNB = MultinomialNB() model_MNB.fit(X_train,Y_train)
Die Variable „X_train“ sind beispielsweise die vorverarbeiteten Tweets und „Y_train“ die zugehörigen Labels (Depressive Tendenz (=1). nicht depressive Tendenz (=0)).
Für unser Projekt haben wir zwei Modelle trainiert. Während das Baseline-Modell ausschließlich mit den vorverarbeiteten Texten trainiert wurde, wurden für das Advanced-Modell zusätzlich die erkannten Emotionen der Texte als Features verwendet.
Ergebnisse evaluieren
Nach dem Training sollten unsere beiden Machine-Learning-Modelle in der Lage sein, Tweets hinsichtlich depressiver Tendenzen zu unterscheiden. Bei einem sensiblen Thema wie Depression müssen wir uns auf die Ergebnisse verlassen können. Dafür galt es die Qualität der Textklassifikation gründlich zu evaluieren. Anhand der bereits erwähnten Testdaten, also der Daten, die für das Training der Modelle nicht benutzt wurden und dem Algorithmus daher noch unbekannt waren.
Abbildung 4 zeigt eine sogenannte Konfusionsmatrix für das Advanced-Modell:
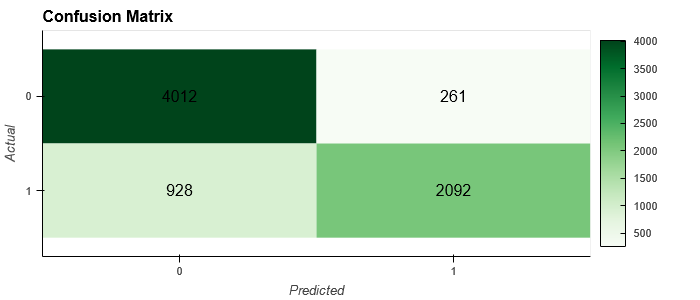 Abbildung 4: Konfusionsmatrix des erweiterten Modells
Abbildung 4: Konfusionsmatrix des erweiterten Modells
Eine Konfusionsmatrix ist ein gängiges Werkzeug zur Bewertung der Leistung von Klassifikationsmodellen. In einer Konfusionsmatrix werden die vorhergesagten Labels hinsichtlich depressiver Tendenzen mit den tatsächlichen Labels aus den Testdaten verglichen. Die Diagonale von oben links nach unten rechts enthält alle richtig klassifizierten Tweets.
Das Ergebnis konnte sich sehen lassen:
Die Genauigkeit (Accuracy) betrug 0,84. Das bedeutet, dass insgesamt 84% der Tweets im Testdatensatz richtig klassifiziert wurden.
Accuracy = (4012 + 2092) / (4012 + 261 + 928 + 2092) = 0.84
Darüber hinaus ergab das erweiterte Modell eine Präzision von 0,89, was bedeutet, dass 89 % aller als depressiv gekennzeichneten Tweets tatsächlich eine depressive Tendenz aufweisen.
Precision = 2092 / (2092+ 261) = 0.89
Das Baseline-Modell erreichte dagegen eine Genauigkeit von 79 %, was im Vergleich zum erweiterten Modell eine geringere Leistung darstellt.
Entwicklung mit Streamlit
Zur Entwicklung unserer App haben wir uns wie schon erwähnt für die junge Streamlit-Technologie entschieden. Streamlit ist ein Open-Source-App-Framework in der Sprache Python und besitzt mindestens 5 interessante Vorteile:
- Einfachheit: Streamlit ermöglicht Entwicklern, schnell und einfach interaktive Anwendungen zu erstellen, ohne dass tiefgreifende Kenntnisse in Webentwicklung erforderlich sind.
- Skalierbarkeit: Streamlit-Anwendungen können problemlos auf mehrere Prozessoren und Hosts skaliert werden, um die Leistung und die Verfügbarkeit zu verbessern.
- Open Source: Streamlit ist Open Source und ermöglicht dem Team, die Software an seine Anforderungen anzupassen und erweiterte Funktionen hinzuzufügen.
- Unterstützt verschiedene Datenformate: Streamlit unterstützt verschiedene Datenformate wie Tabellen, Text, Bilder, Charts, etc.
- Integrationsfähigkeit: Streamlit kann einfach mit anderen Bibliotheken und Tools wie Pandas, Matplotlib etc. integriert werden.
Das Ergebnis konnte sich sehen lassen: Unser Streamlit Dashboard bot eine benutzerfreundliche Oberfläche, über die Anwendende unseren erprobten Algorithmus nutzen konnten, um Textbeiträge auf depressive Inhalten hin zu überprüfen. Das heißt, eine Person gibt einen beliebigen Tweet ein, um diesen über eines der zwei Textklassifikationsmodelle, die wir eingebunden haben, klassifizieren zu lassen.
- Modell 1: Das Baseline-Modell verwendet nur den reinen Text als Eingabe.
- Modell 2: Das erweiterte Machine-Learning-Modell erkennt zusätzlich Emotionen, die der Expert.ai-API geläufig sind.
Durch einen Klick auf den „Evaluate Tweet!“-Button wird der in Python entwickelte Backend-Code mit dem ausgewählten Modell aufgerufen.
Ein Erklärvideo, das die Funktionen des Dashboards ausführlicher beschreibt, finder ihr in unserer Einreichung für den Hackathon (Link).
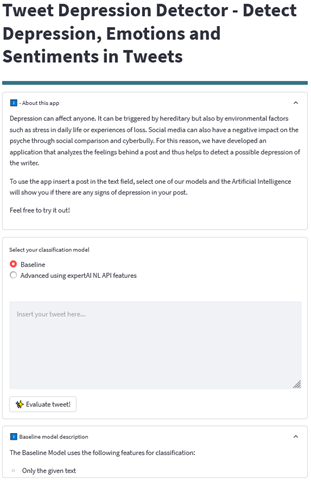
Abbildung 5: Auszug des Tweet Depression Detectors
Abbildung 6 zeigt, wie einfach ein Dashboard implementiert werden kann. Die Implementierung eines Batchs wird ab Zeile 10 beschrieben. Für den Batch selbst wird in Zeile 12 bis 15 ein Radio Button und in Zeile 17 ein einfacher Button ohne Funktion definiert.
Die Implementierung mit Streamlit war für uns auch deshalb leicht, weil wir unser Python Backend ohne eine weitere Programmiersprache (z. B. Typescript) nutzen konnten.
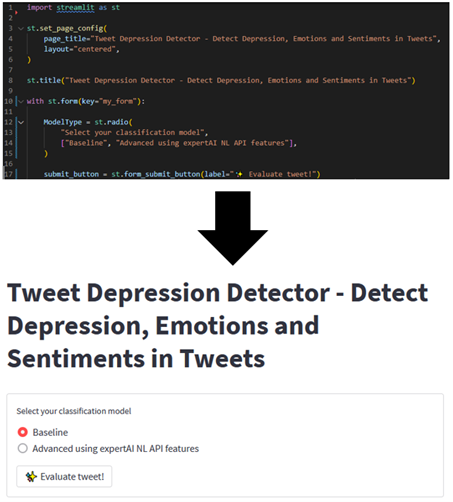
Abbildung 6: Streamlit Implementierungscode und resultierende App
Was wir vom Hackathon mitnehmen
Im Laufe des Hackathons haben wir einige Dinge gelernt:
- Wir hatten die Möglichkeit, die Natural Language API von Expert.ai kennenzulernen, mit der sich umfangreiche Analysen mit minimalen Entwicklungskosten durchführen lassen.
- Wir haben uns noch mehr verdeutlicht, dass Künstliche Intelligenz nicht nur auf die Wirtschaft ausgerichtet sein sollte, sondern auch eine wichtige Rolle bei der Lösung gesellschaftlicher Herausforderungen wie Armut, Gesundheit und Umwelt spielen kann. Es ist wichtig, sowohl wirtschaftliche als auch gesellschaftliche Perspektiven bei der Nutzung von KI zu berücksichtigen, um eine nachhaltige Zukunft zu gestalten.
- Wir haben unsere erste Web-Applikation mit Streamlit entwickelt, und das Tool hat uns überzeugt. Unsere Applikation ließ sich damit schnell und einfach entwickeln und bereitstellen. Wir werden das Framework definitiv weiter nutzen.


