

Kann eine Word Cloud Gedanken lesen? Welche Magie steckt hinter NLP, Python und Power BI? „“ In einem Experiment durften wir Harry Potter, Ron und Hermine mit Methoden des Natural Language Processings (NLP) in Word Clouds verwandeln. Was haben wir über sie erfahren? Und haben Harry, Ron und Hermine den Versuch überlebt? Der Tagesprophet[1] (TP) traf die Zauberlehrlinge zu einem exklusiven Interview.

TP: Mir wurde zugetragen, dass ihr in sogenannte „Words Clouds“ verwandelt wurdet. Wenn ich euch so ansehe, besteht ihr jetzt aus farbigen Wörtern verschiedener Größe. Harry, wie fühlst Du dich?

Harry: Ich fühle mich etwas geplättet, halt zweidimensional, aber auch bis oben hin voll mit Informationen.
TP: Verstehe. Aber wie konnte das passieren, waren dunkle Mächte im Spiel?
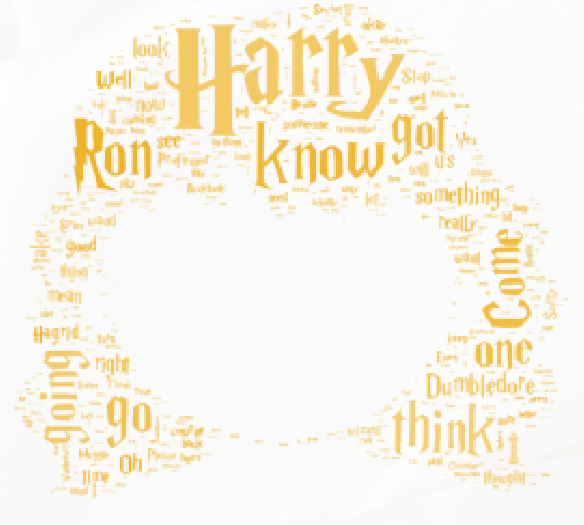
Hermine: Nein, die Muggels[2] nennen es Data Science und Data Visualisation.
TP: Aha … !?
Hermine: Um genau zu sein, haben die dabei Techniken und Methoden des Natural Language Processings (NLP) verwendet. Das ist was Hochtechnisches, das sich aber an der Art, wie natürliche Sprache verarbeitet wird, orientiert. Ziemlich intelligent, hätte ich ihnen gar nicht zugetraut!
TP: In der Tat … Doch woher kommen denn die Wörter in euren „Wortwolken“? Was soll das bedeuten?

Ron: Diese Frage kann ich beantworten. Es sind die Dialoge aus allen Harry-Potter-Filmen. Schuld an all dem war die Maven Magic Challenge[3].Diese richtete sich an Data Scientisten und andere Personen , die sich mit Datenvisualisierung beschäftigen. Die Aufgabe war, Harry-Potter-Dialoge im Rahmen eines Wettstreits auszuwerten. Das finden die dann direkt „voll magic“, wie Muggels halt so sind … Auch eine Hand voll OPITZ CONSULTING Muggels nahm an der Challenge teil. Die haben dann auch das mit den Word Clouds verbrochen.
TP: Ah, ok, die Muggels haben also einen Wettbewerb veranstaltet – und nennen es „Challenge“. Das sieht ihnen ähnlich! Dabei könnte Data Science ja fast ein Teil unserer Welt sein, klingt nach dunklen Künsten, ist da was dran Harry?
Harry: Nein, das ist kein Hexenwerk. Aber wie bei der Zauberei braucht es wohl auch für die Data Science eine Menge Erfahrung und Wissen. Die haben versucht, uns einzuweisen, wir haben das echt nicht verstanden. Die Muggels haben sich da ganz schön reingekniet und waren dafür sogar an einer Universität, so was wie Hogwarts[4]für Fortgeschrittene. An der Challenge, in der unsere Word Clouds entstanden sind, machte „“ wie Ron schon sagte „“ auch eine Hand voll OPITZ CONSULTING Muggels mit, ein Team, dessen Mitglieder sowas im Job machen, und die darin noch besser werden wollen, also so eine Art Quidditch Mannschaft[5]für Datenanalysetechniken. Vom Besen wären die direkt runtergesegelt, aber mit Daten kennen sie sich aus, das muss man schon sagen. Ihrem Team haben sie dann auch einen echten Kampfnamen gegeben, „C42 Next Level Analytics Community“, damit wollen die wohl ihre Besenuntauglichkeit kompensieren … Fehlten nur die passenden Gewänder … dafür gab es blaue T-Shirts.
TP: Quidditch ohne Besen, naja … Was aber sollte das Ganze? Und was hat jeder einzelne dabei gemacht?
Harry: Ein Teil des Teams hat sich mit der Aufbereitung der Daten beschäftigt, und dazu eine besondere Sprache verwendet. Der andere Teil des Teams hat sich um die Sichtbarmachung, oder wie sie es nennen: „Visualisierung“ gekümmert.
TP: Eine besondere Sprache? Eine Schlangensprache? Etwa Parsel[6]?
Harry: Nein, aber der Name der Sprache hatte was mit einer Schlange zu tun. Wie hieß die doch gleich „¦?
Ron und Hermine gleichzeitig: Python!

Harry: Richtig! Python. Wenn ich es richtig verstanden habe, ist Python eine Sprache, die oft für Data-Science-Projekte verwendet wird und besonders für NLP geeignet ist. Es gibt spezielle Pakete, die man mit Python nutzen kann. Eines davon nannten die Muggels Spacy, ein anderes NLTK.
TP: Mensch, Harry, du wirfst mit Fachbegriffen ja nur so um dich, muss ich mir Sorgen machen? Lasst uns mal über etwas anderes sprechen:. Wenn man euch so anschaut, warum sind denn einige Wörter größer als andere? Hermine, kannst Du das beantworten?
Hermine: Das ist so bei einer Word Cloud. Die Größe des Wortes steht für die Häufigkeit, wie oft ein Wort verwendet wurde.
TP: Das kann doch nicht sein! Ich habe eure Filme gesehen und bin mir sicher, dass „you“ oder „and“ viel öfter vorkommen.
Hermine: Das stimmt zwar, aber „you“ und „and“ zählen nicht. Das sind sogenannte Stoppwörter. Die haben keinen relevanten Inhalt und würden wichtigen Wörter einfach nur den Platz wegnehmen. Deshalb wollten die OPITZ CONSULTING Muggels, die in unseren Word Clouds auch nicht mit drin haben. Eine Liste mit Stoppwörtern ist in den NLP-Paketen drin, und kann durch eigene Begriffe erweitert werden. So kann man mit Python Stoppwörter aus Texten entfernen.
TP: Trotzdem, die Wörter kommen mir nicht so ganz echt vor … wurden noch weitere Wörter entfernt?
Hermine: Nicht direkt entfernt, aber bearbeitet. Das machen Data Scientisten anscheinend immer so, die NLP-Pakete für Python helfen ihnen dabei. Zum Beispiel haben sie die Wörter alle „lemmatisiert“. Wenn ich mal eben so drauf los quatsche, spreche ich ja, wenn es um den Baum geht, mal von einem „Baum“, dann von vielen „Bäumen“ oder eines „Baums“. Das System muss dann erst mal lernen, dass damit das gleiche Wort gemeint ist, und aus Bäumen das Wort Baum machen und die dann auch alle richtig mitzählen. Bei Nomen soll das System in der Regel den Singular verwenden:
- Bäume -> Baum
- Räume -> Raum
- Träume -> Traum
Bei Verben den aktiven Präsenz:
- sprachen, sprach,sprachest -> sprechen
- sagen, sagte, sagtest -> sagen
- empfehlen, empfahl, empfohlen -> empfehlen
Und damit sich dabei nicht ein Muggel die Hand blutig schreiben muss, werden die automatisch in der Rechenmaschine vereinheitlicht, bzw. lemmatisiert.
TP: So, so, eine Rechenmaschine … die kann euch ja nicht wirklich verstehen, oder? Bringt die dann nicht vieles durcheinander?
Hermine: Ja, die Gefahr besteht natürlich. Deshalb haben sich die Muggels genaue Aufgaben für sie überlegt, die sie nicht nur schaffen kann, sondern bei denen sie ihnen sogar Haus hoch überlegen ist. Sie zerlegt zum Beispiel im allerersten Arbeitsschritt alle Sätze in ihre Bestandteile. Das nennt sich Tokenisierung. Sprich: Sätze werden in die einzelnen Wörter zerlegt.
TP: Ja, das klingt schlüssig. Warum aber werden in Abbildung 2 die Wortarten, also Verben, Pronomen, Nomen und so weiter, mit genauen Prozentzahlen aufgeführt? Was soll das bringen?
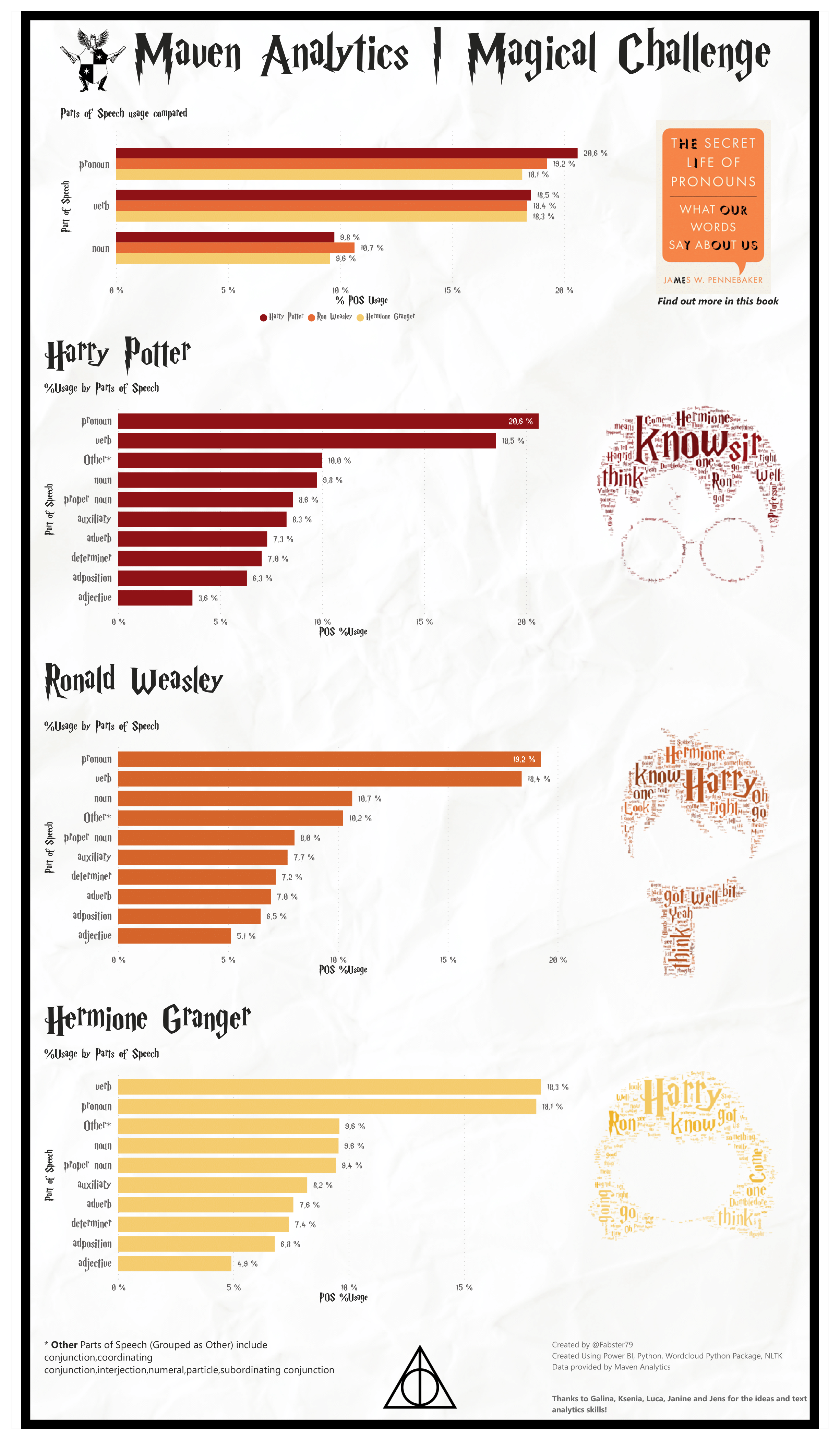
Hermine: Diese Kategorisierung kann man in Python automatisch vornehmen lassen, und damit analysieren, welche Wortarten diese Person am häufigsten verwendet. Das sagt etwas über die Art und Weise aus, wie sie spricht, was wiederum etwas über Ihren Charakter aussagen kann.[7]
Ron: Ich verwende zum Beispiel viele Pronomen, wie I, you, he, she, it.
Hermine: Und ich verwende sehr viele Verben.
TP: Das heißt, die können am Ende eure Gedanken lesen? Schon wieder Zauberei!
Hermine: Ja, ein wenig schon. Man kann noch einen Schritt weiter gehen, und aus der Sprache, die wir sprechen, ableiten, ob wir eher gut oder eher schlecht auf eine Sache zu sprechen sind. Die Muggels nennen es Sentiment Analyse.
TP: Also, nachdem die Texte analysiert wurden und man diese Verarbeitung vorgenommen hat, wie habt ihr denn nun Gestalt angenommen?
Harry: Nun, wir sprachen vorhin schon drüber. Ein Teil des Teams hat die Analyse aus der Rechenmaschine herausgeholt und für alle sichtbar gemacht. Das heißt Visualisierung. Dafür brauchen die Muggels keinen Zauberstab, sondern nur ein Computerprogramm namens „Power BI“.
TP: Zaubern ohne Zauberstab, so ein Wundermittel hätte ich auch gerne! Hab direkt mal nach Power BI gegoogelt … und pah, dort gibt gar keine Word Cloud als Visualisierung. Was sagt ihr jetzt?
Harry: Richtig erkannt! Aber es gibt die Möglichkeit, ein Python Script Visual zu verwenden. Damit können Python Visualisierungen einfach in Power BI eingebunden werden. Das ist super praktisch, weil es eine riesige Anzahl von Visualisierungspaketen in Python gibt. Unsere Word Cloud ist nur eins davon.
TP: Ganz schön clever. Aber wie schafft man es, dass die Word Cloud sogar in eure Köpfe passt und nicht einfach viereckig ist. Sind auch die Farben anpassbar?
Harry: Man kann das über die Parameter des Word-Cloud-Pakets steuern. Dort kann man eine Schriftart definieren, eine Farbe als HSL-Wert übergeben und eine Grafik als Maske hinterlegen.
Ron: Voll krass das mit der Farbe. Über einen Zufallswert kann man da eine Varianz reinbringen, damit sich die Farben ganz leicht unterscheiden, und die Word Cloud somit noch etwas lebendiger wirkt.
TP: Nicht schlecht! Kann ich davon für unser Zeitungslayout noch was lernen?
Ron: Kann schon sein. Die haben zum Beispiel eine Papiertextur als Hintergrund für die Power BI Anwendung verwendet, Icons eingefügt und auch die Farbpalette nach den Hausfarben ausgewählt, um so eine ansprechende Anwendung zu gestalten.
TP: Nun mal Hand aufs Herz. Konnten euch die Muggels eure Geheimnisse entlocken?
Harry: Nein, so weit sind die Muggels noch nicht. Man kann zwar anhand der verwendeten Pronomen gewisse Rückschlüsse auf die Persönlichkeit der Sprecher bzw. der Beziehung von Personen untereinander ziehen, aber wir sind ja fiktionale Charaktere. Das macht es besonders schwierig. Auch hiermit haben sich die Muggels schon beschäftigt, auf einem wissenschaftlichen Niveau, und z.B. ein Programm namens SentiArt entwickelt, um speziell literarische Texte zu analysieren.
TP: Vielen Dank an euch. Sprache analysieren, Gedanken lesen und das Ganze in einer einzigartigen Gestalt sichtbar machen. NLP mit Python und Power BI, diese Zauberwerkzeuge hätten das Zeug für eine Titelstory. Mal sehen was meine Redaktion dazu meint.
Ergänzung der Redaktion:
Es scheint, als wären Word Clouds tatsächlich eine gute Visualisierungsmöglichkeit, um wichtige Informationen aus Texten zu extrahieren. Diese Möglichkeit kann wohl auch für allerlei weitere Texte verwendet werden, also z. B. für E-Mails aus dem Customer Service, Kommentarbeiträge auf Firmenseiten oder Nachrichten aus den Social-Media-Kanälen.
NLP kann man aber nicht nur für die Aufbereitung von Word Clouds benutzen. Ein spannender Anwendungsfall ist die Kategorisierung von E-Mails, indem man das enthaltene Anliegen erkennt. In Kombination mit Maschine Learning, welches mit Vergangenheitsdaten und der getätigten Kategorisierung trainiert wird, kann man dann automatisch kategorisieren.
Wir sind gespannt, was sich die Muggels noch so einfallen lassen!
Mehr zum Thema Textklassifikation im Cattle Crew Blog
Index
[1] Tagesprophet: Der Tagesprophet (im Original: The Daily Prophet) ist, wie es scheint, die größte und bedeutendste Tageszeitung und Print-Publikation in der magischen Welt. (Vgl. https://harry-potter.fandom.com/de/wiki/Der_Tagesprophet)
[2] Muggels, so nennen die Magier und Hexen die nicht-Magier.
[3] Maven Magic Challenge: Das ist so was wie eine Werbeaktion von Maven Analytics. Und das wiederum ist eine Firma, die Kunden dabei hilft, moderne analytische Plattformen aufzubauen. Hier erfahrt ihr mehr über die Maven Magic Challenge: https://www.mavenanalytics.io/blog/maven-magic-challenge
[4] Hogwarts heißt die Schule, auf der Harry Potter und seine Freunde das Zaubern lernen.
[5] Quidditch heißt eine in der Zaubererwelt beliebte Sportart. Sie wird von zwei Mannschaften mit je sieben auf Besen fliegenden Spielern mit insgesamt vier Bällen gespielt. Je Mannschaft dienen drei Ringe, die in 20 Metern Höhe angebracht sind, als Tore. (Vgl. https://de.wikipedia.org/wiki/Begriffe_der_Harry-Potter-Romane#Quidditch)
[6] Parsel ist eine Schlangensprache (Parseltongue), die angeboren ist und selten vorkommt. Die Mehrheit der Zaubererschaft fürchtet sie, da die meisten Parselmünder Schwarzmagier waren. (Vgl. https://de.wikipedia.org/wiki/Begriffe_der_Harry-Potter-Romane#Parselmund)
[7] Es gibt einen Muggel Professor namens James Pennebaker, der sich mit der Erforschung bestimmter verwendeter Wörter aus psychologischer Sicht beschäftigt. So referierte er bei der TED Conference in Austin/Texas über das „geheime Leben der Pronomen“ „“ I, You, Me, We, Us: small words with the tremendous ability to illuminate who we are and how we’re feeling „“ Das solltet ihr euch ansehen: https://www.youtube.com/watch?v=PGsQwAu3PzU
[8] SentiArt ist ein Vector Space basiertes Modell zur Analyse literarischer Texte. https://github.com/matinho13/SentiArt


