
Hochverfügbarkeit ist ein unterschätztes und leider häufig vernachlässigtes Thema. Auch eine Big-Data-Distribution, in der per se eine Datenreplikation auf einzelne DataNodes eingeschaltet ist, sollte hier miteinbezogen und hochverfügbar konfiguriert werden. Es reicht nicht aus, nur die Replikation der DataNodes zu benutzen, sondern die High-Availability-Funktion kann zusätzlich aktiviert werden. Denn sollte der zentrale NameNode ausfallen, ist ein Zugriff auf die im Hadoop Distributed File System (HDFS) zugrunde liegenden Daten nicht mehr möglich. Nicht alle Services können aktuell mit Hochverfügbarkeit konfiguriert werden, aber für einen Großteil ist dies durchaus möglich. So auch für die extrem wichtige Komponente HDFS.
Anhand einer Beispielkonfiguration in einem Cloudera Cluster Stack werden die Aufgaben von NameNode, Standby NameNode oder Secondary NameNode verdeutlicht und es wird mit wenigen Mausklicks eine High-Availability-Konfiguration für den HDFS Service ausgerollt. Der mitinstallierte Secondary NameNode bietet keine Hochverfügbarkeit. Dieser wird als eine Art Unterstützer („Helper“) angesehen, der sich um zeitliche Checkpoints der Metadaten kümmert und für das Verknüpfen von „editlogs“ mit dem „fsimage“ verantwortlich ist. Dies ermöglicht einen schnelleren Restart des NameNodes.
Der NameNode, der die Metadaten des HDFS Clusters hält, wird durch einen zusätzlichen Standby NameNode abgesichert. Es ist dann nicht möglich, einen Secondary NameNode zu benutzen. Andere Aufgaben des NameNodes sind es, die Replikationen bzw. Kopien der Dateien zu überwachen. Sollte eine Kopie beschädigt werden, sorgt dieser für eine erneute Replikation auf den einzelnen DataNodes. In Hadoop Version 2 ist der „Singlepoint of Failure“ des NameNodes nicht mehr vorhanden wie in Version 1. Im „Worst Case“-Scenario übernimmt der Standby NameNode die primäre Aufgabe des ausgefallenen NameNodes.
In diesem Active/Passiv-Szenario wird schnell und automatisch über einen vorher definierten Service mit minimaler Downtime umgeschaltet.
Erreicht wird dies durch den Hochverfügbarkeitsdienst Zookeeper, der Ausfälle registriert und entsprechende Maßnahmen ergreift. Dabei wird anhand von zwei Wegen unterschieden, ob dieser über das „Quorum Journal“-basierte System oder per „Shared NFS Storage“ eingerichtet wird. Cloudera nutzt standardmäßig ersteres. Hierdurch bleibt der NameNode und Standby NameNode durch eine separate Gruppe von JournalNodes synchronisiert.
Anmerkung:
Im Cloudera Manager werden jegliche Konfigurationen über das grafische Interface konfiguriert. Direkt auf dem Server befindliche manuelle Konfigurationsanpassungen werden ignoriert und gegebenenfalls zurückgerollt.
Konfiguration High Availability Cloudera am Beispiel einer 5.11-Installation.
-
HDFS Service über den Cloudera Manager auswählen
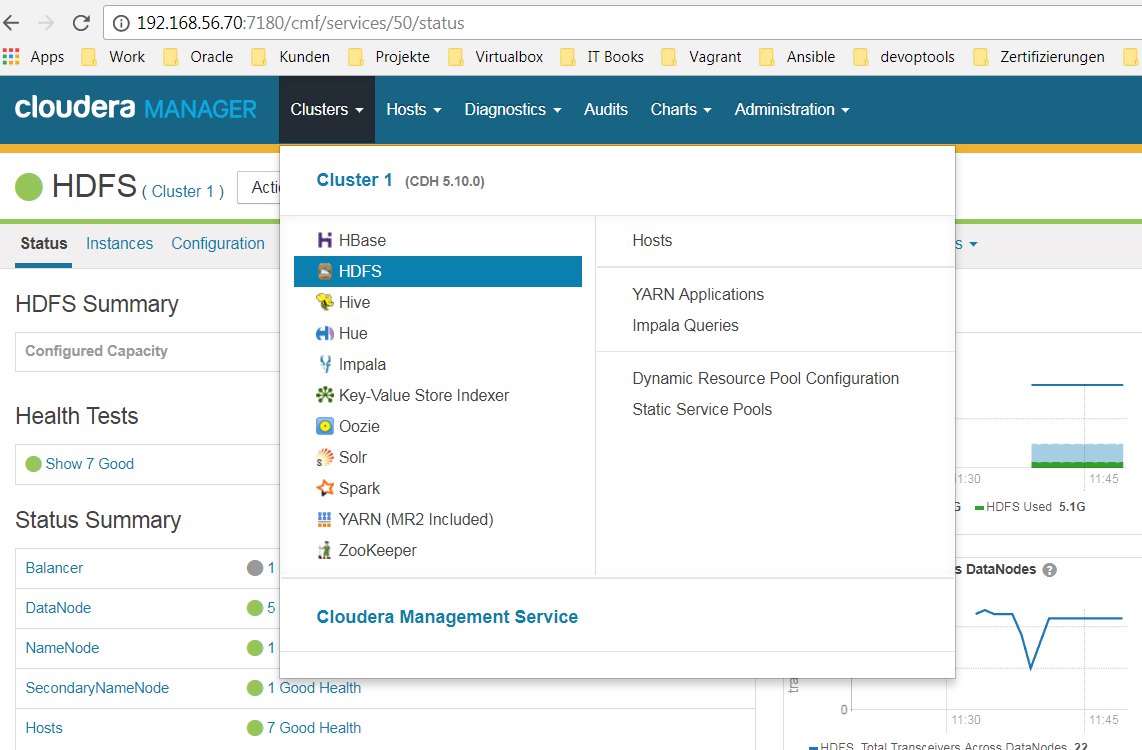
-
Aus dem Menüpunkt Action –> Enable High Availibility auswählen
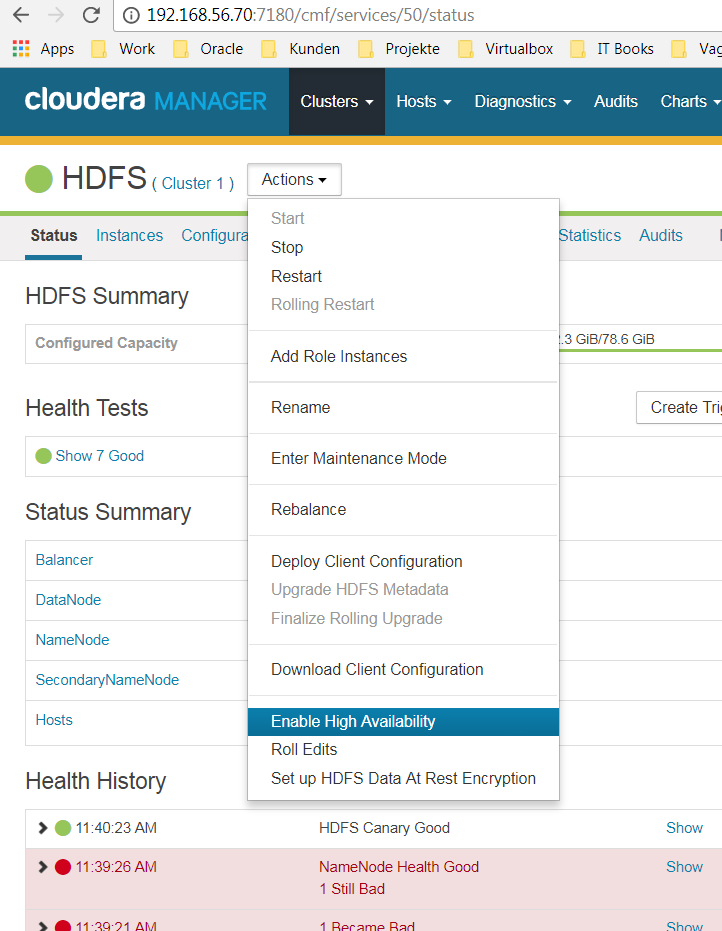
-
Nameservice benennen –> namerservice1
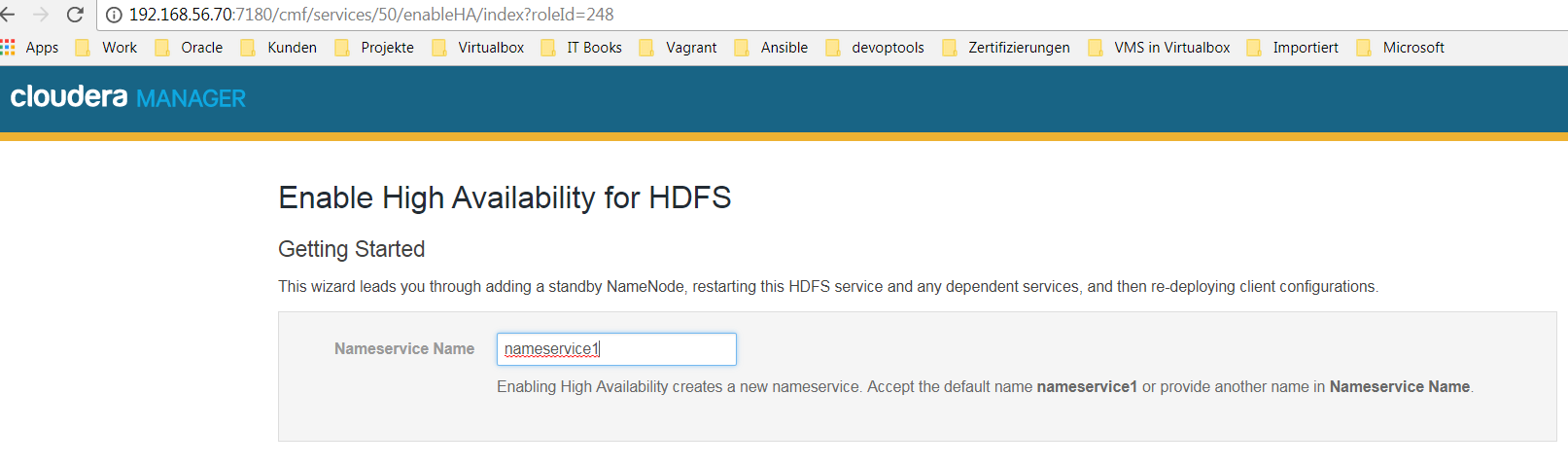
-
Rollen zuordnen
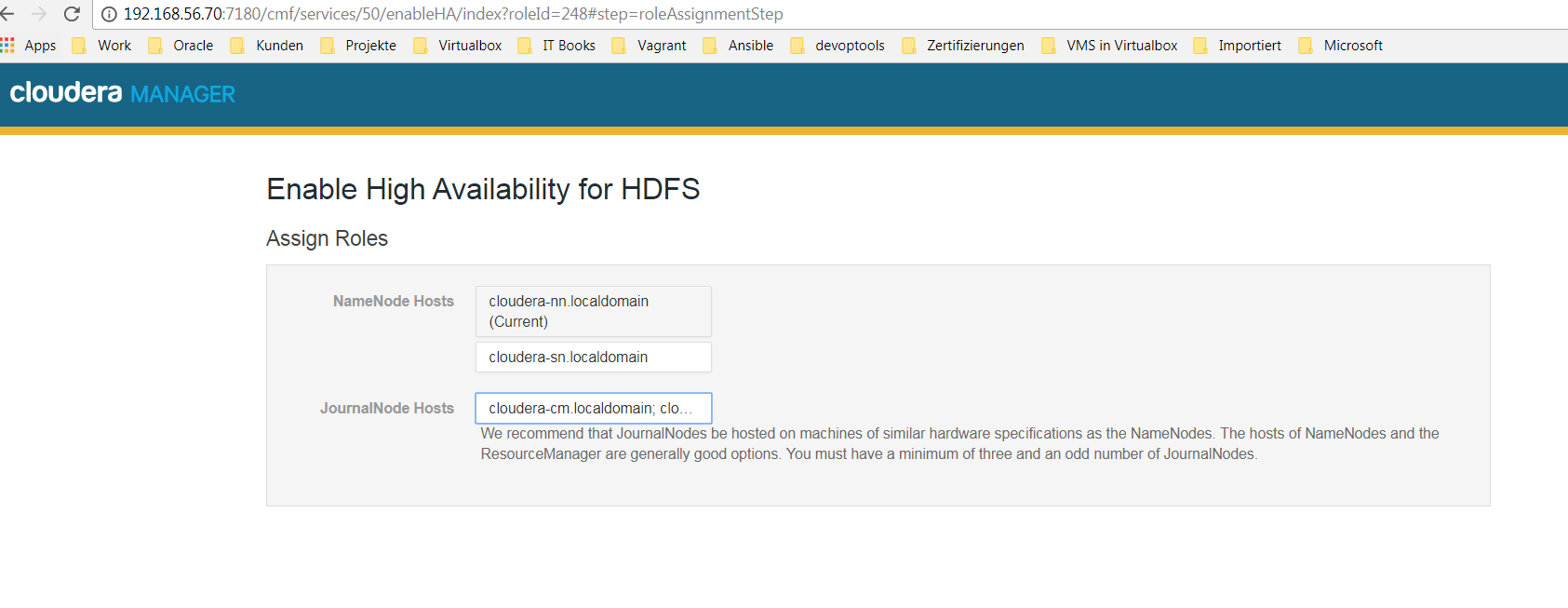
-
Ü„nderungen überprüfen und gegebenenfalls überschreiben
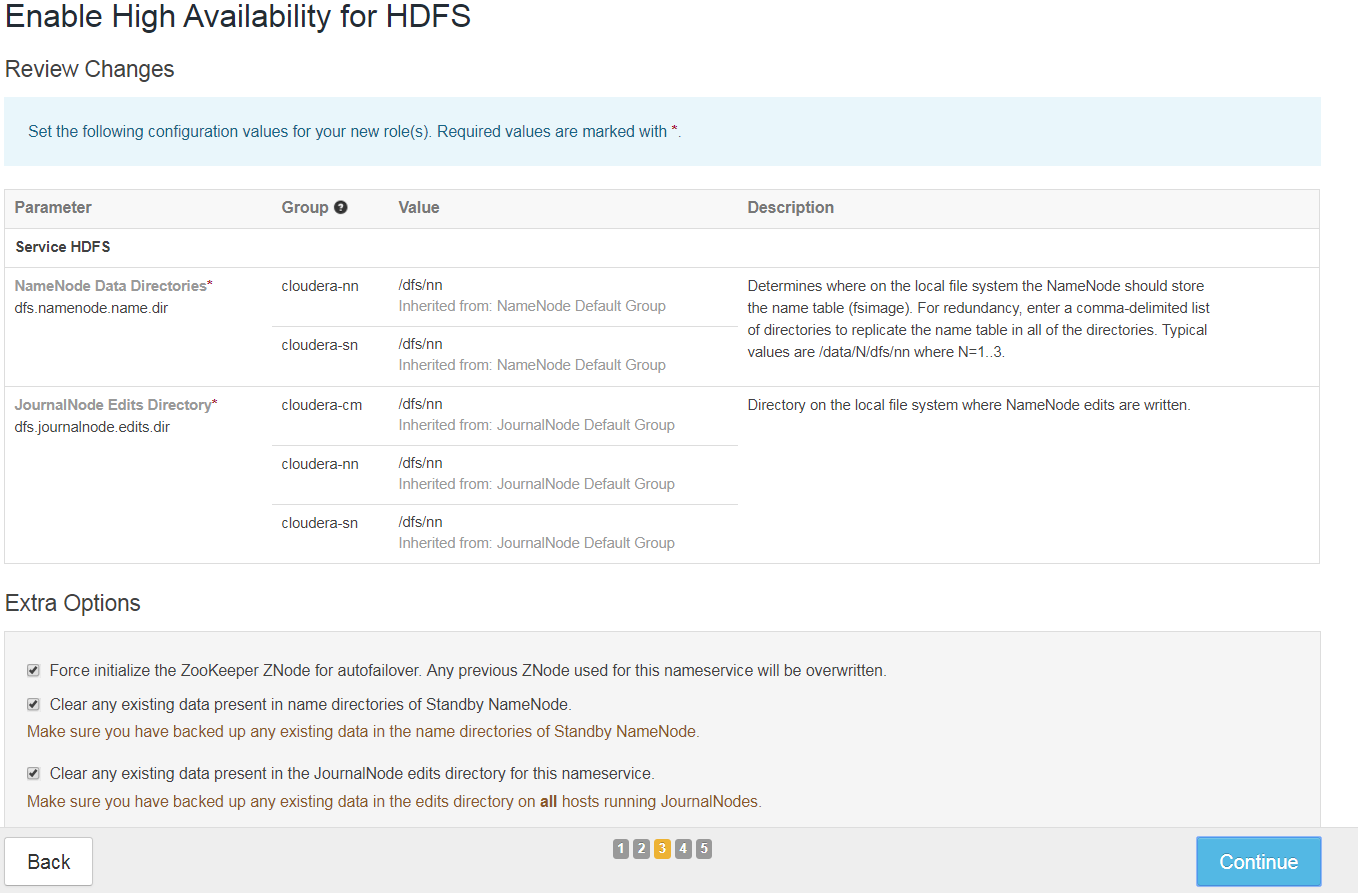
-
Ausführen
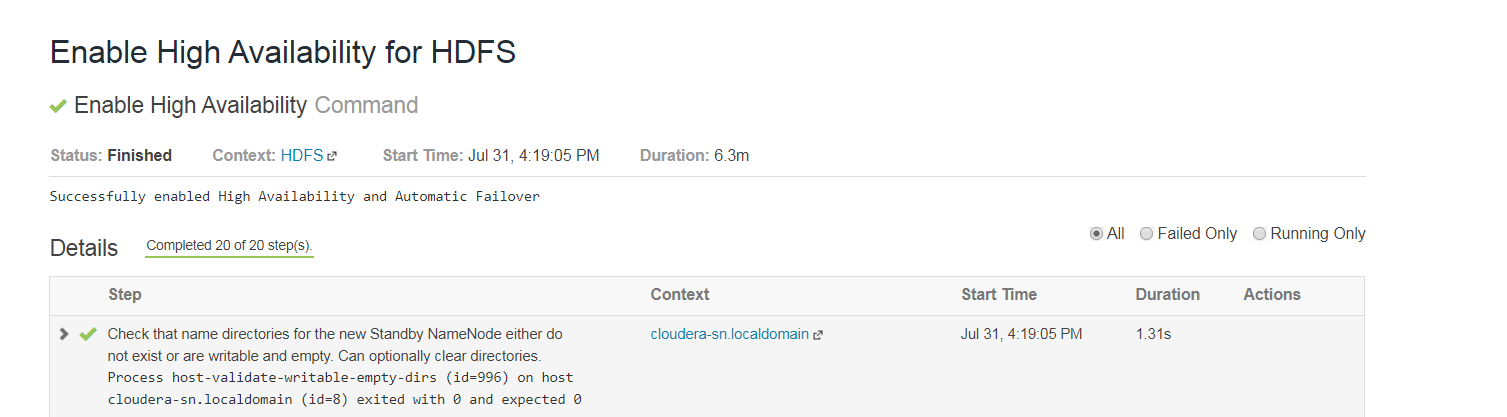
-
Gratulation
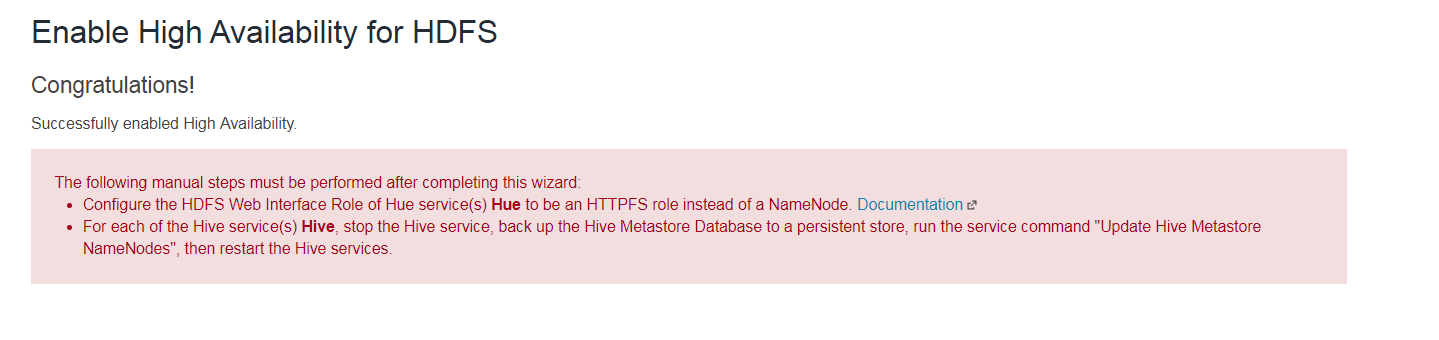
Nachdem für HDFS High Availability eingeschaltet ist, müssen noch Hue und Hive entsprechend des Dokumentationslinks angepasst werden.
Durch einen Test, bei dem der NameNode im laufenden Betrieb hart ausgeschaltet wird, wird überprüft, ob der Zookeeper sich um den automatischen Failover kümmert, in dem der Standby NameNode zum aktiven NameNode gemacht wird.
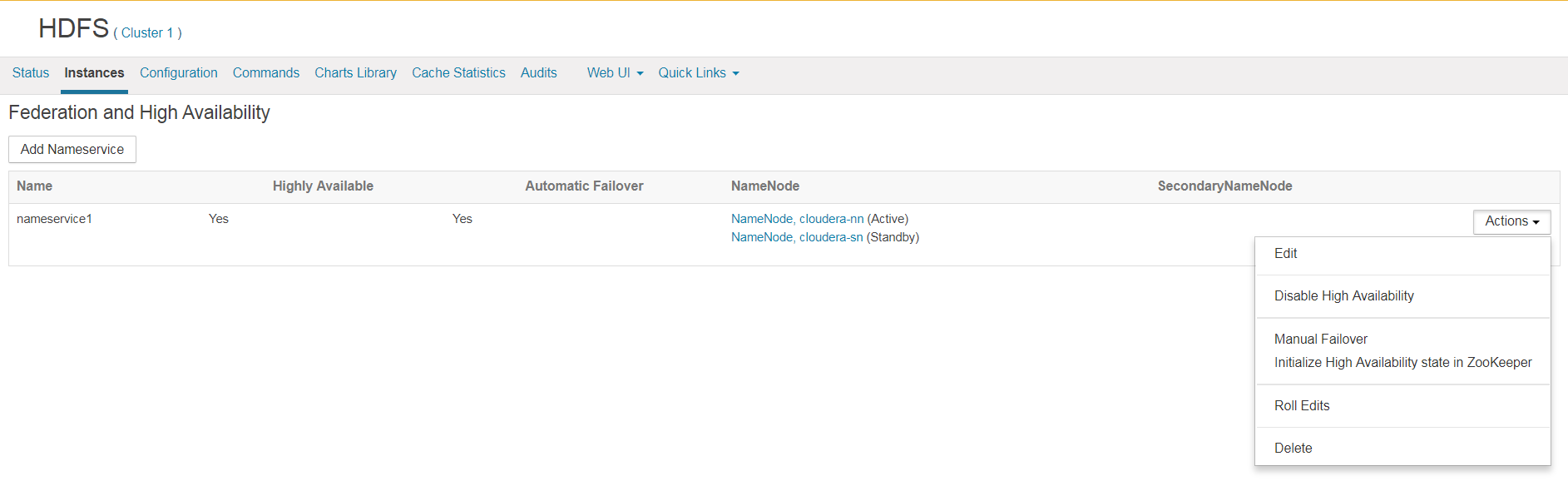
Nach simuliertem Systemausfall von Namenode und einer kurzen Downtime werden die Rollen automatisch getauscht und HDFS stellt den Dateizugriff sicher.

Es gilt zu beachten, dass jeder einzelne Dienst hochverfügbar konfiguriert und getestet wird.
Weiterführende Konfiguration von Hochverfügbarkeit kann der offiziellen Cloudera Dokumentation entnommen werden.
Links:
https://www.cloudera.com/documentation/enterprise/5-11-x/topics/cdh_hag_hdfs_ha_enabling.html
Kontakt:
Simon Hahn
simon.hahn@opitz-consulting.de



