

In den ersten beiden Teilen dieser Artikelserie habe ich dir die Konfiguration von Airbyte über die Weboberfläche und das Command-Line-Tool Octavia-cli vorgestellt.
Schnell stellte sich für mich die Frage, was da eigentlich hinter den Kulissen von Airbyte passiert. Also habe ich tiefer gegraben und werde dir im abschließenden dritten Teil zeigen, wie Airbyte im Inneren funktioniert.
Abbildung 1 weiter unten zeigt, wie der Prozess abläuft, wenn Airbyte Daten von einer Quelle in ein Ziel synchronisiert:
- Zunächst werden in Airbyte Daten aus einem einzelnen Datensatz der Quelle (SOURCE DATA) extrahiert
- und als JSON-Format an die Destination gesendet.
- Das JSON-Format wird dort erst einmal unverändert als Rohdatensatz (RAW DATA) in einer Spalte vom Format Binary Large Object (BLOB) gespeichert. Dies ist wichtig, denn es gilt der zentrale Grundsatz der ELT-Philosophie: keine Änderung der Daten durch die E- und L-Prozesse!
- Wenn es sich beim Ziel um eine relationale Datenbank handelt, dann kann das JSON-Format in eine relationale Tabelle (NORMALIZED DATA) umgewandelt werden.
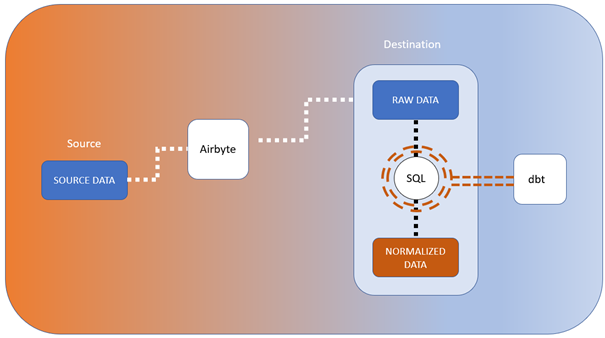
Intern nutzt Airbyte übrigens dbt, um SQL-Statements zu erstellen und die Daten zu transformieren. Kurz zur Erklärung: dbt oder „data build tool“ ist ein Open-Source-Datenintegrationstool, mit dem sich über SQL Select Statements sogenannte Data Models definieren lassen. Nähere Details zu dbt findest du auf https://www.getdbt.com.
Wenn die SQL Statements per dbt run zur Ausführung gebracht werden, werden Views oder Tabellen erstellt, je nach Konfiguration. Du möchtest mehr über dbt erfahren? In den nächsten Monaten ist eine eigene, ausführliche Blogserie zu diesem Thema geplant. Schau also gerne wieder in den CattleCrew Blog rein.
Jetzt aber weiter zu den einzelnen Schritten im Airbyte Prozess:
Schritt 1: von SOURCE DATA zu RAW DATA
Ist das Ziel eine Datenbank, dann hat Airbyte dort Tabellen angelegt, in denen die JSON-Formate aus den Source-Datensätzen gespeichert werden: _airbyte_raw_<streamname>. Nehmen wir an, wir möchten ganz simple Kundendaten mit den Attributen id und name extrahieren. In diesem Fall könnten wir den Streamnamen „customer“ verwenden. Es gäbe also in der Zieldatenbank die Tabelle _airbyte_raw_customer mit folgendem Format:
- _airbyte_ab_id: eindeutige Hash-ID, die vom System generiert wird
- _airbyte_data: JSON-Format der Datensätze
- _airbyte_emitted_at: Datum und Zeitstempel, an dem die Daten an die Destination gesendet wurden.
Zwischenschritt: Temporäres Speichern
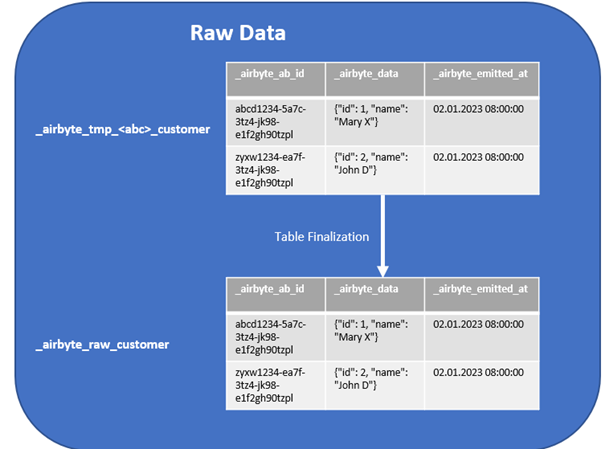
Während die Datensynchronisation zwischen Source und Destination läuft, werden die Daten noch nicht direkt in die Tabelle _airbyte_raw_customer geschrieben, sondern zunächst in einer temporären Tabelle gesammelt: _airbyte_tmp_<abc>_customer. <abc> steht hierbei für ein dreistelliges Buchstabenkürzel, das sich bei jedem Lauf ändert, damit der Name der temporären Tabelle eindeutig ist.
Über die temporären Tabellen wird sichergestellt, dass kein inkonsistenter Datenbestand in der _airbyte_raw-Tabelle landet, wenn der Prozess während des Lesens aus der Quelle plötzlich abbrechen sollte. Sobald alle Daten aus der Quelle gelesen wurden, wird der Inhalt der temporären Tabellen in die _airbyte_raw-Tabelle übertragen.
Dies passiert mit folgendem simplen Statement:
INSERT INTO _airbyte_raw_customer SELECT * FROM _airbyte_tmp_<abc>_customer
Anschließend wird die temporäre Tabelle wieder gelöscht. Dieser Schritt wird in Airbyte als „Table Finalization“ bezeichnet.
Schritt 2: von RAW DATA zu NORMALIZED DATA
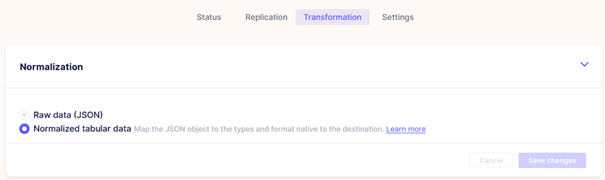
Wenn in der Airbyte-Konfiguration die Funktion „Normalization“ aktiviert ist, wie in diesem Screenshot (Abbildung 3) …
… dann wird das JSON-Format aus _airbyte_raw_customer._airbyte_data per dbt in eine relationale Datenbanktabelle überführt (siehe Abbildung 4).
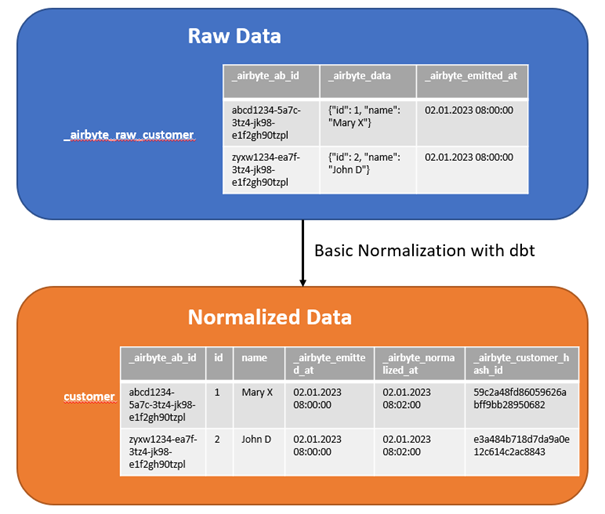
Wie du siehst, wird zu jedem JSON-Key eine Spalte angelegt, in die der entsprechende JSON-Wert übernommen wird. _airbyte_normalized_at ist eine Metadatenspalte, die Datum und Zeitstempel der Normalisierung enthält. Über die konkatenierten Attribute id und name wird ein Hashwert gebildet, der in der Spalte _airbyte_customer_hash_id gespeichert wird und als Unique Key verwendet werden kann. Die Hashwertbildung über alle konkatenierten Attribute zur Erzeugung eines eindeutigen Schlüssels ist ein übliches Vorgehen im Data Warehousing.
Basic Normalization in drei Schritten
Bevor wir uns die Basic Normalization, die in drei Schritten abläuft, genauer ansehen, braucht es wieder einen kleinen Exkurs in das data build tool (dbt):
Wie oben erwähnt, ist dbt in Airbyte integriert und wird bei der Basic Normalization genutzt. Dazu diese Hinweise:
- Die dbt-Modelle, die in allen drei Schritten der Basic Normalization definiert werden, sind vom Typ „emphemeral“, d. h. es werden weder Views noch Tabellen auf der Datenbank erzeugt, sondern die Common Table Expressions existieren nur zur Laufzeit.
- Die Zieltabelle, in unserem Beispiel customer, ist als inkrementelles Modell (Typ „incremental“) angelegt. Das bedeutet, dass diese Tabelle fortgeschrieben und nicht bei jedem Lauf neu angelegt wird. Die Daten aus dem Normalisierungsvorgang werden also zunächst in eine temporäre Zwischentabelle geschrieben und anschließend per Delete/Insert-Strategie in die Zieltabelle übertragen. Die SQL-Statements sehen wir uns im nächsten Absatz an.
Doch nun zu den Schritten der Normalisierung:
1. Parsing (Model-Suffix _ab1):
- Extraktion der Spalten aus dem JSON-Format
- Verschachtelte JSON-Formate werden wieder als JSON-Format in einer eigenen Spalte abgeleg
2. Casting (Model-Suffix _ab2):
- Cast der Spalten in das richtige Format
3. Hashing (Model-Suffix _ab3):
- Erzeugen eines Hashwerts über alle konkatenierten Attribute
- Dieser Hashwert kann als Unique Key verwendet werden
Welche SQL-Statements brauchst du?
Je nach eingesetzter Zieldatenbank (PostgreSQL, Snowflake, MSSQL, Oracle usw.) können die Statements variieren. Unser Beispiel bezieht sich auf PostgreSQL, weil ich diese Datenbank im Kundenprojekt eingesetzt habe. Das Statement sieht in der für dbt typischen Jinja-Schreibweise für die temporäre Tabelle so aus:
create temporary table "customer__dbt_tmp121704956331"
as (
with __dbt__cte__customer_ab1 as (
-- Parsing
select
_airbyte_ab_id,
_airbyte_emitted_at,
jsonb_extract_path_text(_airbyte_data, 'id') as "id",
jsonb_extract_path_text(_airbyte_data, 'name') as "name"
from my_db_name.my_schema._airbyte_raw_customer') }}
),
__dbt__cte__customer_ab2 as (
-- Casting
select
_airbyte_ab_id,
_airbyte_emitted_at,
cast(id as {{ dbt_utils.type_integer() }}) as id,
cast(name as {{ dbt_utils.type_text() }}) as name
-- Referenzierung (ref) auf das erste emphemeral Model
from {{ ref('__dbt__cte__customer_ab1') }}
),
__dbt__cte__customer_ab3 as (
-- Hashing
select a.*,
-- dbt-Utility zur Erzeugung eines Hashwertes
{{ dbt_utils.surrogate_key([
id,
name]) }} as _airbyte_customer_hashid,
now() _airbyte_normalized_at
-- Referenzierung (ref) auf das zweite emphemeral Model
from {{ ref('__dbt__cte__customer_ab2') }} a
)
select *
-- Referenzierung (ref) auf das dritte emphemeral Model
from {{ ref('__dbt__cte__customer_ab3') }}
Dies wäre das Statement zur Beladung von customer:
-- Delete-Insert-Stragegie bei incremeantal Models
delete from "my_db_name"."my_schema"."customer"
where (_airbyte_ab_id) in (
select (_airbyte_ab_id)
from "my_db_name"."my_schema"."customer__dbt_tmp121704956331"
);
insert into "my_db_name"."my_schema"."customer"
("_airbyte_ab_id", "id", "name", "_airbyte_emitted_at",
"_airbyte_normalized_at", "_airbyte_customer_hash_id")
select "_airbyte_ab_id", "id", "name", "_airbyte_emitted_at",
"_airbyte_normalized_at", "_airbyte_customer_hash_id"
from "my_db_name"."my_schema"."customer__dbt_tmp121704956331";
… und was passiert mit verschachtelten JSON-Formaten?
Wahrscheinlich fragst du dich jetzt, wie die Normalisierung funktioniert, wenn im JSON-Format verschachtelte JSON-Formate enthalten sind. Schauen wir uns hierzu folgendes Beispiel an:
JSON-Format in _airbyte_raw_cars._airbyte_data:
{
"make": "alfa romeo",
"model": "4C coupe",
"powertrain_specs": { "horsepower": 247, "transmission": "6-speed" }
}
Die erste normalisierte Tabelle cars (siehe Abbildung 5) resultiert aus der Normalisierung von _airbyte_raw_cars. Sie enthält die Attribute make, model und powertrain_spec (JSON-Format), sowie den Hashwert (_airbyte_cars_hash_id) der konkatenierten Attribute.
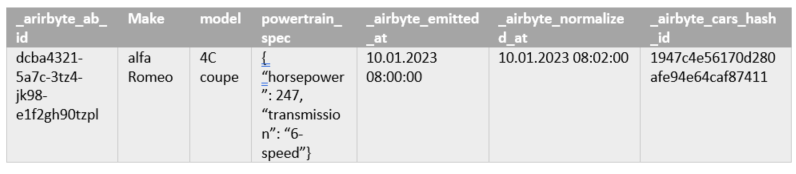
Um das JSON-Format powertrain_specs zu normalisieren, wird die Tabelle cars als Input für einen weiteren Normalisierungsschritt verwendet. Das Resultat ist die Tabelle powertrain_specs (s. Abbildung 6) mit den Attributen horsepower und transmission, sowie dem Hashwert (_airbyte_powertrain_specs_hash_id) über diese konkatenierten Attribute. Ferner hat powertrain_specs eine Foreign-Key-Beziehung zu cars über die _airbyte_cars_foreign_hash_id.

Mir ist keine Begrenzung der JSON-Verschachtelung bzw. des Normalisierungslevels bekannt. D.h. wenn es n-fach-verschachtelte JSON-Formate in der airbyte-raw-Tabelle gibt, finden n Normalisierungen statt. Daraus entsteht eine Tabellenhierarchie mit Foreign-Key-Beziehungen.
Die verschiedenen Synchronisierungsmodi
Jetzt kommen wir noch zu den Synchronisierungsmodi, kurz Sync-Modes, die ich in erwähnt habe, als es um die Konfiguration der Verbindungen ging.
Die Sync Modes setzen sich aus zwei Teilen zusammen. Der erste Teil bezieht sich auf das Verhalten in der Quelle (wie wird gelesen?) und der zweite auf das Verhalten im Ziel (wie wird gespeichert?).
Verhalten in der Quelle
Full Refresh: Alles aus der Source wird gelesen
Incrementa:
- Nur das Delta seit der letzten Synchronisation wird gelesen
- Setzt ein Datumsfeld voraus, an dem der Zeitpunkt der letzten Synchronisation erkennbar ist – z. B. modified_date
- Verwendung des modified_date als Cursor-Field in der Connection-Konfiguration
Du fragst dich, was das Cursor-Field modified_date bewirkt?
Ein Maximalwert des modified_date wird am Ende der Synchronisation ermittelt. Dieses Datum wird für jede Connection in der Airbyte Metadatentabelle state gespeichert. Bei der nächsten Synchronisation einer Connection braucht dann nur das modified_date aus der Metadatentabelle state ausgelesen zu werden, und schon kennen wir den Aufsetzpunkt für die neue Synchronisation. Voilà!
Verhalten im Ziel
Overwrite: Alles wird überschrieben
Append:
- Neue Daten werden eingefügt, ohne alte zu löschen
- IDs sind nicht eindeutig, wenn Änderungshistorien existieren
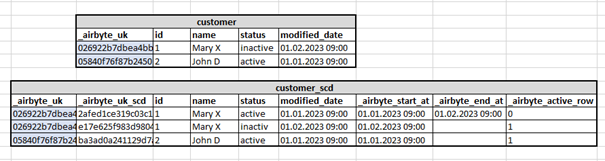
Dedup History:
- Insert oder Update in der Zieltabelle, so dass die IDs eindeutig sind
- Änderungshistorie wird in einer zusätzlichen Tabelle mit dem Suffix _scd gespeichert
- _scd-Tabelle ist vom Typ Slowly Changing Dimension 2 (SCD2)
- Setzt voraus, dass ein Primary Key definiert ist, über den zwischen der Zieltabelle und _scd-Tabelle eine Foreign Key Beziehung hergestellt werden kann
- Zusätzliche Spalten in der Zieltabelle:
_airbyte_unique_key = Hashwert über Primary Key Feld - Zusätzliche Spalten in der _scd-Tabelle:
_airbyte_unique_key = Foreign Key zur Zieltabelle
_airbyte_unique_key_scd = eindeutiger Schlüssel der _scd-Tabelle
_airbyte_start_at = Beginn der Zeitscheibe
_airbyte_end_at = Ende der Zeitscheibe
_airbyte_active_row = Flag, ob aktuell (1) oder Historie (0)
Abbildung 7 zeigt, wie das Resultat von Dedup History für die Tabelle customer aussehen könnte:
Kombinationsmöglichkeiten der Synchronisierungsmodi
Folgende Kombinationsmöglichkeiten aus Verhalten in der Quelle und Verhalten im Ziel sind in Airbyte als Sync Modes verfügbar:
- Full Refresh | Overwrite
- Full Refresh | Append
- Incremental | Append
- Incremental | Dedup History
Full Refresh bietet sich für Tabellen mit geringem Datenvolumen an, weil keine Performanceprobleme zu erwarten sind. Die Entscheidung, ob Full Refresh mit Overwrite oder Append kombiniert wird, hängt davon ab, ob im Zielsystem die Änderungshistorie benötigt wird. Falls im Quellsystem immer nur der aktuelle Stand ohne Änderungshistorie verfügbar ist und im Zielsystem der aktuelle Stand ausreicht, solltest du die Kombination Full Refresh | Overwrite verwenden.
Incremental hat für Tabellen mit großem Datenvolumen beim Lesen aus der Quelle einen Performancevorteil gegenüber Full Refresh. Denn es wird immer nur die Deltamenge gelesen. Werden die Sync Modes Append und Dedup History im Zielsystem verwendet, bläht sich das Datenvolumen hingegen sehr auf. Insbesondere, wenn sich die Daten im Quellsystem häufig ändern.
Mir persönlich fehlt die Sync Mode Kombination Incremental | Overwrite. Diese böte einen echten Vorteil für Tabellen mit großem Datenvolumen und häufigen Änderungen, wenn ich im Zielsystem nur den aktuellen Stand benötige.
Wenn du Daten zurücksetzen musst
Für den Fall, dass in einem Airbyte Stream die Daten aus dem Quellsystem komplett neu geladen werden müssen, gibt es den Reset-your-data-Button (siehe Abbildung 8)

Das passiert, wenn du auf den Button „Reset your data“ klickst:
- Alle Daten in den Ziel-Tabellen werden gelöscht (_airbyte_raw, normalisierte Zieltabelle)
- Die Ziel-Tabellen werden aber nicht gedroppt
- Im Falle von Incremental in der Metadatentabelle state wird die Information zur letzten Synchronisation zurückgesetzt, so dass wieder von Anfang an gelesen wird.
Fazit
Die Normalisierung im Data-Ingestion-Prozess erleichtert uns die Arbeit ungemein, weil die relationalen Rohdaten für das DWH schon entsprechend aufbereitet werden.
Etwas nachteilig finde ich, dass bei der Data Ingestion immer alle Felder aus der Quelltabelle verarbeitet werden. Denn es ist aktuell leider nicht möglich, bei der Konfiguration der Airbyte Connection nur bestimmte Felder auszuwählen. Gerade vor dem Hintergrund der Datenschutz Grundverordnung (DSGVO) wäre das aber sehr wichtig. Da dieses Thema verstärkt bei Airbyte angefragt wurde, wurde dieses Feature schon für spätere Releases in Aussicht gestellt. Wir dürfen also gespannt sein, wann es so weit ist.
Die Incremental-Sync-Modes bieten insbesondere bei der Extraktion Performancevorteile. Das Laden per Append oder Dedup History macht meiner Meinung nach aber nur Sinn, wenn die Änderungshistorie auch tatsächlich benötigt wird. Andernfalls bläht sich das Datenvolumen unnötig auf. Und bitte nicht vergessen, dass auch das Datenvolumen der _airbyte_raw-Tabellen bei Append und Dedup History stetig wächst, weil der Inhalt dieser Tabellen vor der nächsten Synchronisation nicht gelöscht, sondern fortgeschrieben wird!
In meinem Kundenprojekt habe ich die Erfahrung gemacht, dass man die _airbyte_raw-Tabellen nach erfolgreicher Normalisierung mit dem truncate-Befehl leeren kann, ohne Gefahr zu laufen bei der nächsten Synchronisation Daten zu verlieren. Den truncate-Befehl musste ich allerdings selbst in den ELT-Prozess implementieren, da Airbyte ein Truncate der _airbyte_raw-Tabellen nicht vorsieht.
Damit wäre ich auch schon am Ende des letzten Teils der Airbyte Trilogie angekommen. Ich hoffe, dass ich dir Airbyte etwas näherbringen konnte. Wenn dir diese Serie gefallen hat, dann bleib gerne dabei: Weitere interessante Blogbeiträge zum Thema Modern Data Stack sind schon in Arbeit 🙂
Teil 1: Daten integrieren mit Airbyte – Teil 1: Einführung & Installation


