

„Ein Bild sagt mehr als tausend Worte.” Dieses Sprichwort besagt, dass Bilder schneller und unmittelbarer Informationen übermitteln können als Text oder Zahlen. Dass bei geschäftlichen Anliegen häufig auf Graphen und Dashboards zurückgegriffen wird, ist nichts Neues, nur haben sich mit den wachsenden Möglichkeiten auch die Anforderungen verschoben:
- Dashboards und datengetriebene Prozesse sind heute eine Selbstverständlichkeit.
- Reproduzierbarkeit und schnelle Verfügbarkeit von Daten sind unverzichtbar.
- Datenbestände in Pipelines werden zunehmend programmatisch integriert
- Self-Service verlangt nach Einfachheit im ganzen Daten-Workflow.
- Darstellung von Ergebnissen muss schnell, einfach, klar und ansprechend sein.
Nun sind die großen Business Intelligence-Plattformen, die sich rund um diese Anforderungen ihren Platz erobert haben, nicht mehr allein: sie bekommen Konkurrenz von Open Source, beispielsweise im Kontext der Open-Source-Programmiersprache Python durch Bibliotheken, die die Aufgaben der Datenaufbereitung und Datenvisualisierung einfacher machen. Wie ihre großen Geschwistern liefern sie Plots, Dashboarding, Grafiken für Web-Publishing bis hin zur Daten-Applikation. Was es damit auf sich hat, erfährst du in diesem Artikel.
Was erwartet dich in dieser Blogserie?
In dieser Blogserie beleuchten wir eine Familie von Tools, die bei der Erstellung interaktiver Visualisierungen und hochwertiger Grafiken helfen. Im ersten Teil der Serie stellen wir die Bibliothek Plotly vor und bauen Visualisierung eines Tableau-Tutorials nach, zum Mitmachen. In den nächsten Teilen zeigen wir, wie solche Grafiken in vollwertige, interaktive Dashboards integriert werden.
Wohin geht Visualisierungstechnologie heute?
Elegante und aussagekräftige Berichterstellung ist nach wie vor unerlässlich für die Gewinnung von Insights aus Daten. Mit ein paar Spreadsheets und statischen Graphiken ist es nicht getan. Während kommerzielle BI-Tools seit einigen Jahren ein immer breiteres Funktionalitätsspektrum über die graphische Darstellung hinaus anbieten, von der Entwicklungsumgebung, Datenabfrage, Datenexploration, Datentransformation, Datenmodellierung bis zum Dashboard inklusive Data Governance, haben sich Lösungen im Open-Source-Bereich ebenfalls einen Weg gebahnt.
Dies zeigt sich in der Entstehung einer Vielzahl von leistungsfähigen Bibliotheken wie etwa Matplotlib, Bokeh, Plotly, Seaborn oder Streamlit u.a. für die Datenvisualisierung. Dieses lebendige Ökosystem ermöglicht es, über die Integration und Berechnung von numerischen Daten hinaus, Ergebnisse in Graphiken umzusetzen, zu aktualisieren, mit formatiertem Text zu kommentieren, und ist somit der Kern für multimediales Storytelling.
Können Open-Source-Bibliotheken auch im Businesskontext genutzt werden?
Eine wichtige Frage stellt sich unweigerlich: Können sich Python-Bibliotheken mit kommerziellen BI-Tools auch im Businesskontext messen? Die Antwort ist grundsätzlich: Ja. Statische Grafiken, die man aus wissenschaftlichen Publikationen kennt – die Wiege dieser Entwicklung sind ggplot oder matplotlib – sind längst passé. Mit ein paar Zeilen Code kann man visuell ansprechende Darstellungen erzeugen, mit Styling anpassen, exportieren und sogar live teilen. Vorteile auf dem Gebiet des Self-Service BI kommen dazu: durch nützliche Funktionen wie Zoomen und Filtern sind Daten stets in Interaktion mit den Anwendenden. Auf der Ebene der Anpassungsmöglichkeiten, Performance und bei der Anzahl der Standardvisuals können die Open-Source-Bibliotheken ebenfalls mit den großen Geschwistern Power BI, Qlik oder Tableau mithalten.
Man muss allerdings im Auge behalten, dass Python eine Programmierumgebung darstellt. Ob Businessanwendende weiterhin vorwiegend über graphische Benutzerschnittstellen arbeiten, oder ob sie den Schritt Richtung Datenprogrammierung wagen und sich auf Code einlassen, ist also ein wichtiges Entscheidungskriterium. Aber so groß, wie es früher schien, ist der Schritt zur programmierten Datenvisualisierung gar nicht. Es gehört Vertrauen in die Benutzung einer Programmiersprache dazu und man sollte sich mit den Open-Source-Bibliotheken ein wenig vertraut machen. Dass dies nicht zu schwer ist, wird zunächst mit Plotly gezeigt, und in weiteren Folgen der Serie auch mit weiteren Bibliotheken.
Voilá: Plotly
Warum haben wir uns dafür entschieden, das Tool Plotly näher vorzustellen? Zunächst hat das Tool einige wichtige Vorteile:
- Plotly ist eine Open-Source-Bibliothek und auch im kommerziellen Einsatz kostenfrei.
- Plotly setzt auf plotly.js auf, einer JavaScript Graphik–Bibliothek. Man muss also kein Webentwickler sein.
- Plotly kann sowohl in Python als auch in R genutzt werden, ist also vielseitig.
- Plotly unterstützt standardmäßig über 40 Typen von Charts.
- Plotly kann sogenannte Plots produzieren: anstelle von statischen Einzelgraphiken werden interaktive Graphiken erzeugt. Plots können in Webseiten oder Notebooks integriert werden.
- Plotly unterstützt Funktionen wie Zoomen oder Mouse-Over mit zusätzlichen Informationen oder der Anpassung der Achsen.
Wie werden die Daten angebunden?
Der Datenimport für die Nutzung von Plotly erfolgt über Python-Code. Die Beispiele in diesen Blogeintrag verwenden eine Excel Beispieldatei mit Daten aus einem fiktiven Online-Shop. Diese Datei wird auch im Tableau-Tutorial genutzt.
Wir stellen hier eine Möglichkeit vor, Daten über einen zweidimensionalen Pandas DataFrame an Plotly zu übergeben. Dafür ist es gut, im Hinterkopf zu behalten, dass DataFrames aus verschiedenen Dateitypen und Datenbanken befüllt werden können.
#import pandas and load data
import pandas as pd
Orders_df = pd.read_excel(r'’Sample – Superstore.xls’, sheet_name=’Orders’)
#adjust dataframe
Orders_df.drop("Row ID", axis = 1, inplace=True)
Orders_df.head()
Im folgenden Beispiel werden Bestellsummen aggregiert und auf der Ebene des Bestelldatums als DataFrame bereitgestellt. Während Tools wie Tableau automatisch Aggregationen auf verschiedenen Ebenen anbieten, ist dies bei der Nutzung von Plotly oder anderen Python Libraries nicht der Fall. Jede Ebene muss eigens im DataFrame bereitgestellt werden. Diese Vorgehensweise erfordert deutlich mehr Programmieraufwand als in Tableau, wo Dimensionen und Kennzahlen per Drag & Drop einer Grafik zusammengeführt werden und die benötigte Aggregation automatisch erstellt wird.
#aggregate Orders dataframe
df_line_plot_year = Orders_df.groupby(pd.Grouper(key='Order Date', axis=0,
freq='Y')).agg({'Sales':'sum'}).reset_index()
df_line_plot_year['year']= pd.DatetimeIndex(df_line_plot_year['Order Date']).year
df_bar_plot_segment = Orders_df.groupby([pd.Grouper(key='Order Date', axis=0,
freq='Y'), 'Category' ]).agg({'Sales':'sum'}).reset_index()
df_bar_plot_segment['year']= pd.DatetimeIndex(df_bar_plot_segment['Order Date']).year
Schritt 1: Für den ersten Plot line_plot_year wird mit dem Input der Bestellungen aus der Excel Datei Orders_df ein DataFrame erstellt. Dieser DataFrame wird gruppiert über die Spalte Order Date nach dem Jahr des Bestelldatums. Die Spalte Sales wird als Summe aggregiert.
Schritt 2: Im zweiten Schritt wird eine neue Spalte mit dem Jahr des Bestelldatums als Zahl hinzugefügt. Für weitere Plots werden die DataFrames um Spalten erweitert, die in den Grafiken angezeigt werden sollen wie z.B. die Produkategorie. Es ist übrigens nicht zwingend notwendig, für jede einzelne Grafik einen DataFrame zu erstellen. Die Aggregation eines vorhandenen DataFrames kann auch direkt im Plotly Express-Aufruf erfolgen.
Geht es auch einfach? – Plotly und Plotly Express
Plotly Visualisierungen basieren auf plotly.graph_objects.Figure-Objekten im JSON Format. Mit diesen Objekten werden plotly.js gefüttert und Grafiken gerendert.
Ein Barplot aus der Plotly Doku mit Daten über ein Obstwettessen sieht beispielsweise so aus:
Figure({
'data': [{'hovertemplate': 'Contestant=Alex Fruit=%{x} Number Eaten=%{y}',
'name': 'Alex','type': 'bar',
'x': array(['Apples', 'Oranges', 'Bananas'], dtype=object),
'y': array([2, 1, 3], dtype=int64)},
{'hovertemplate': 'Contestant=Jordan Fruit=%{x} Number Eaten=%{y}',
'name': 'Jordan','type': 'bar',
'x': array(['Apples', 'Oranges', 'Bananas'], dtype=object),
'y': array([1, 3, 2], dtype=int64)}],
'layout': {'legend': {'title': {'text': 'Contestant'}},
'template': '...','xaxis': {'title': {'text': 'Fruit'}},
'yaxis': {'title': {'text': 'Number Eaten'}}}
})
Du kannst die Top-Level Attribute data und layout mit dazugehörigen Attributen manuell erstellen und befüllen, um ein Graph Object zu generieren. Dabei arbeitest du direkt mit dem Modul plotly.graph_objects. Der Vorteil ist, dass du den Plot von Grund auf erstellst und so von Anfang an alle Gestaltungsmöglichkeiten in der Hand hast.
Dennoch empfiehlt es sich, die Plotly-Dokumentation als Startpunkt bei der Visualisierung das Modul ‚plotly.express‘ zu nutzen. Dabei werden für einen gewählten Plottyp (Barchart, Histogram etc.) und den Dateninput bestimmte Attribute des Graph Objects vorbefüllt. So brauchst du deutlich weniger Code, um eine Standardvisualisierung zu erstellen.
Hier ein Vergleich der zwei Herangehensweisen für den Beispielplot:
1. Verwendung von Plotly Express:
import plotly.express as px fig = px.bar(df, x="Fruit", y="Number Eaten", color="Contestant", barmode="group") fig.show()
2. Verwendung von Graph Objects:
import plotly.graph_objects as go
fig = go.Figure()
for contestant, group in df.groupby("Contestant"):
fig.add_trace(go.Bar(x=group["Fruit"], y=group["Number Eaten"], name=contestant,
hovertemplate="Contestant=%s
Fruit=%%{x}
Number Eaten=%%{y}"% contestant))
fig.update_layout(legend_title_text = "Contestant")
fig.update_xaxes(title_text="Fruit")
fig.update_yaxes(title_text="Number Eaten")
fig.show()
Die Resultate sind die gleichen, wie diese Abbildung zeigt.
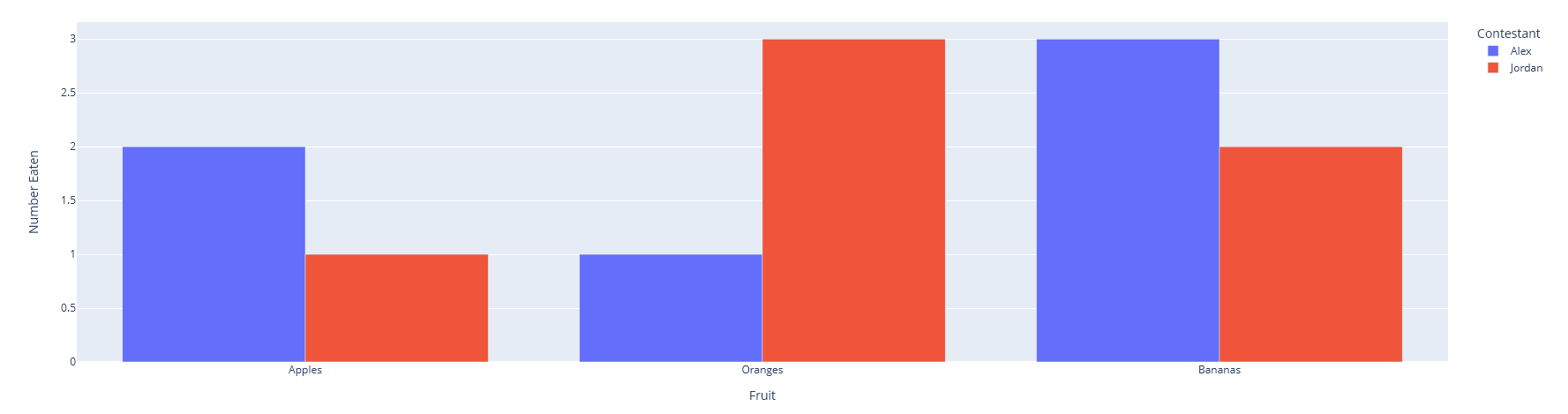
Empfehlung: Plotly Express als Ausgangspunkt, Anpassungen später
Ob Plotly oder Plotly Express – die Visualisierung sieht am Ende identisch aus. Der Weg mit Plotly Express ist jedoch deutlich einfacher. Das Modul versucht, sinnvolle Standards für Attribute zu definieren und erstellt so zum Beispiel passende Achsen-Labels oder automatische Hover-Informationen. Wenn die automatisch generierten Plots nicht passen, gibt es verschiedene Parameter für das Styling, die du direkt anpassen kannst, wenn du Plotly Express aufrufst. So z. B. Titel, Farbe oder Breite der Grafik.
Wenn das nicht ausreicht, kann auch das Graph Object mit bestimmten Methoden verändert werden. Z. B. mit ‚update_layout()‘ oder ‚add_trace()‘. Dies ist insbesondere relevant, wenn Filtermöglichkeiten für interaktive Grafiken oder komplexe Visualisierungen mit verschiedenen Sub-Plots erstellt werden sollen.
Kurzum: Der Workflow mit Plotly Express als Startpunkt ist intuitiv und wird mit einer umfangreichen und nützlichen Doku unterstützt, die zu den einzelnen Plot-Typen verschiedene Gestaltungsmöglichkeiten aufzeigt.
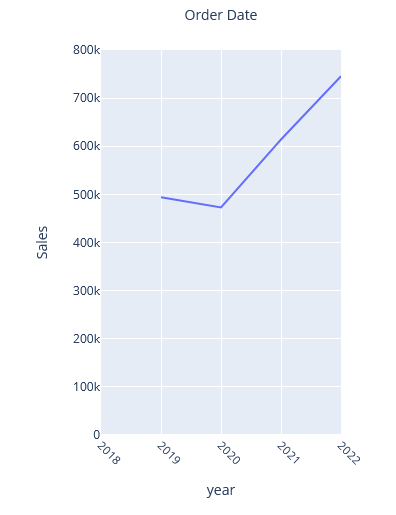
Beispiel 1: Lineplot für Verkaufssummen
Für unser erstes Beispiel haben wir den ersten Plot aus dem Tableau-Tutorial nachgebaut. Es ist ein Lineplot mit Verkaufssummen, aggregiert auf einzelne Jahre.
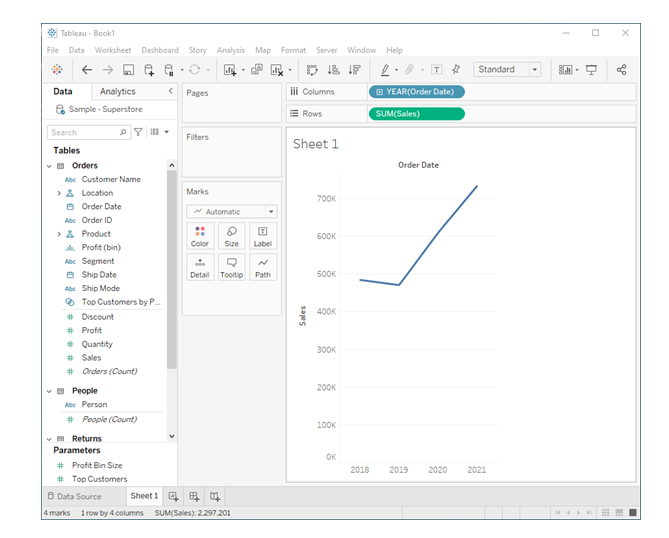
Der erste Aufruf definiert ein Graph Object fig_year mit dem bereits generierten Daten-Input df_line_plot_year und Attribute für die X- und Y-Achsen.
fig_year = plx.line(df_line_plot_year, x='year', y="Sales") fig_year.show()
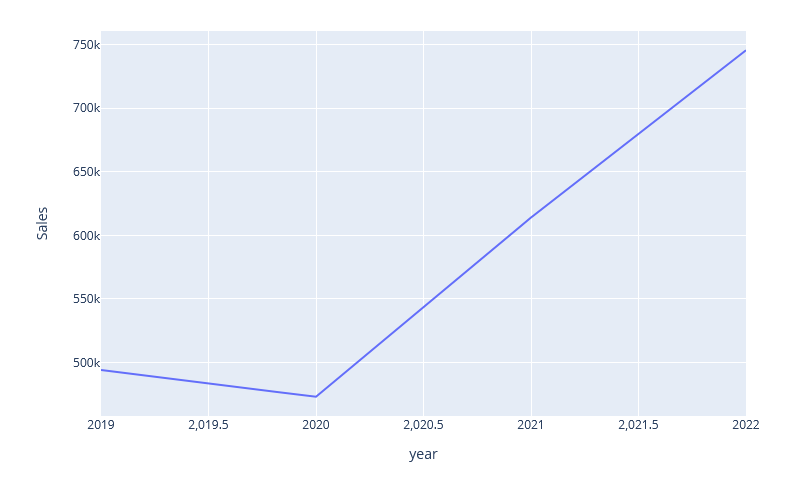
Weil der daraus resultierende Plot zu breit ist und wenig sinnvolle Bezeichnungen für die X-Achsen produziert, legen wir eine geeignete Breite selber fest. Das Label der X-Achse soll wie bei Tableau oberhalb des Plots zu sehen sein. Dazu werden die Labels der X-Achse zunächst als leerer String definiert
fig_year = plx.line(df_line_plot_year, x='year', y="Sales",
width= 400, labels={'x':'', 'y':'Sales'})
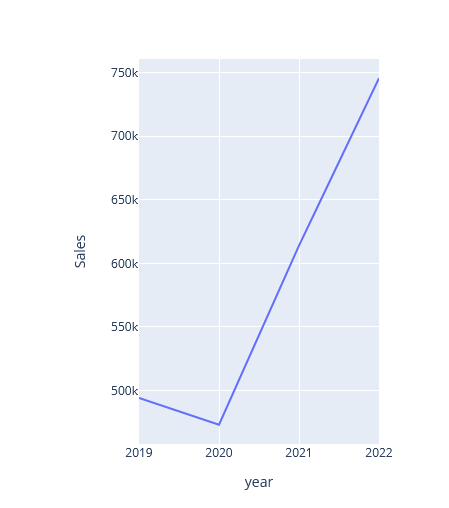
Das Zwischenergebnis ist schon ansehnlicher, aber noch deutlich von der Tableau-Vorlage entfernt. Für weitere Anpassungen werden Methoden des Graph Objects genutzt.
- Mit .update_xaxes und .update_yaxes werden die Achsen entsprechend definiert.
- Über .update_layout wird die Bezeichnung der X-Achse mit Order Date als Titel mittig über dem Plot platziert. Damit kommt das Resultat der Vorlage jetzt recht nahe.
fig_year.update_yaxes(range=[0, 800000]) fig_year.update_xaxes(range=[2018, 2022] , nticks=5, tickangle=45) fig_year.update_layout(xaxis=dict(tickformat="%Y"), title_text='Order Date', title_x=0.5, title_font_size=14)
Beispiel 2: Barplot mit Verkaufssummen verschiedener Produktkategorien
Für das nächste Beispiel haben wir einen Barplot mit den Verkaufssummen von Produktkategorien für verschiedene Jahre nachgebaut.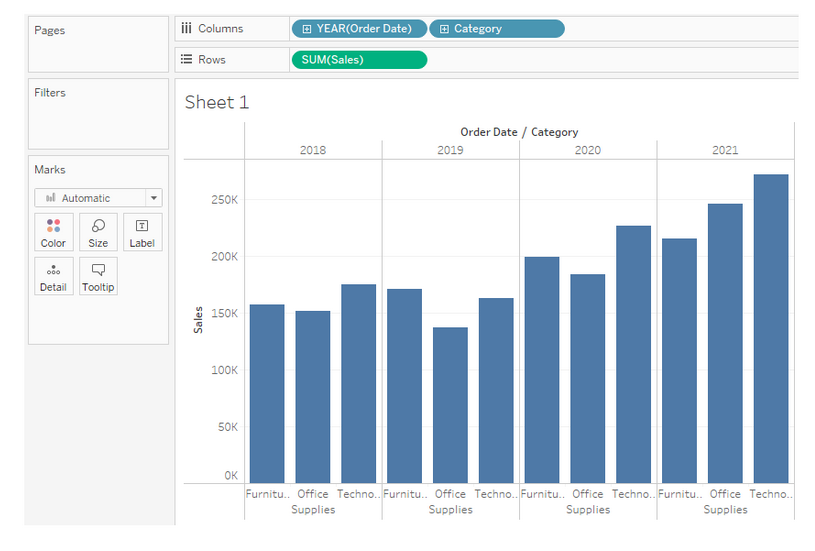
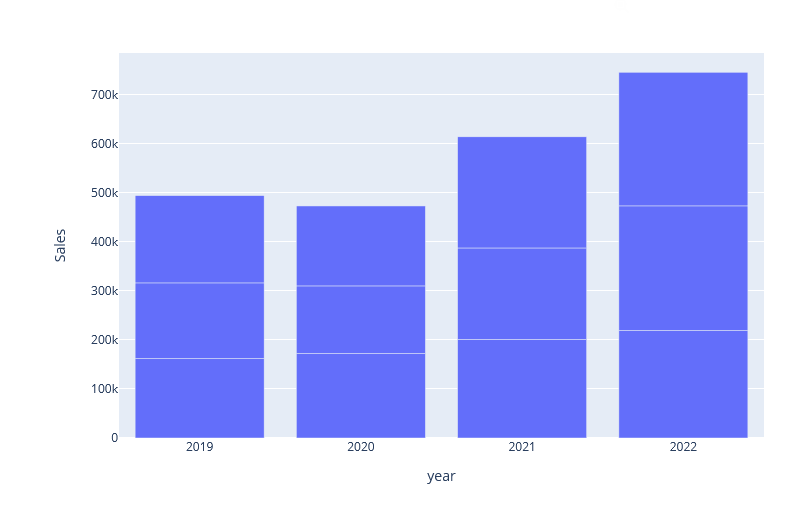 Dabei sind wir auf kleine Hindernisse gestoßen: In Tableau ist es sehr einfach, eine kategorische X-Achse mit zwei Attributen zu erstellen (hier: Bestelldatum und Produktkategorie). In Plotly dagegen war das deutlich komplizierter. Mit Plotly Express gar nicht machbar. Bei einem Plot mit den Attributen year und sales siehst du zwar die einzelnen horizontalen Balken, welche die Produktkategorie repräsentieren. Du kannst diese aber nicht identifizieren.
Dabei sind wir auf kleine Hindernisse gestoßen: In Tableau ist es sehr einfach, eine kategorische X-Achse mit zwei Attributen zu erstellen (hier: Bestelldatum und Produktkategorie). In Plotly dagegen war das deutlich komplizierter. Mit Plotly Express gar nicht machbar. Bei einem Plot mit den Attributen year und sales siehst du zwar die einzelnen horizontalen Balken, welche die Produktkategorie repräsentieren. Du kannst diese aber nicht identifizieren.
fig_month = plx.bar(df_bar_plot_segment, x='year', y="Sales",) fig_month.update_xaxes(nticks=6)
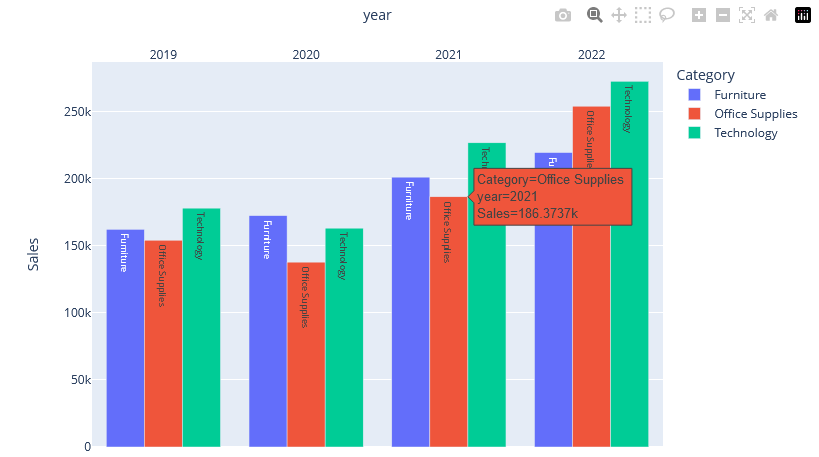
Als Workaround bietet es sich an, einen gruppierten Barplot zu erstellen, der als X-Achse die Jahre des Bestelldatums verwendet. Die Y-Achse sind die aggregierten Verkaufssummen. Über das Argument color kann dann die Produktkategorie in den Plot gebracht werden.
Aus den horizontalen anonymen Balken werden so vertikale, farbliche Balken, die über text auch den Namen der jeweiligen Produktkategorie bekommen. Dazu wird automatisch eine Legende zu den Farben erstellt. Die Layouts der einzelnen Positionen werden über update_layout und update_traces angepasst. Wie bereits erwähnt, erstellt Plotly automatisch interaktive Grafiken. D. h. wenn du über einen Balken hoverst, werden relevante Informationen angezeigt, u. a. der genaue Wert der Sales-Kennzahl. Über die Leiste am rechten oberen Rand des Plots sind weitere Funktionen wie Zoomen oder Exportieren des Plots verfügbar.
fig_month_color = plx.bar(df_bar_plot_segment, x='year', y="Sales", color='Category', barmode= 'group', text = 'Category')
fig_month_color.update_layout(xaxis=dict({'side' : 'top'},tickformat="%Y", nticks=5))
fig_month_color.update_traces(textposition='auto', textfont_size = 9)
Beispiel 3: Erweiterung des Barplots
Für das nächste Beispiel haben wir aus dem Tableau-Tutorial einen Barplot um Unterkategorien der Produkte erweitert:
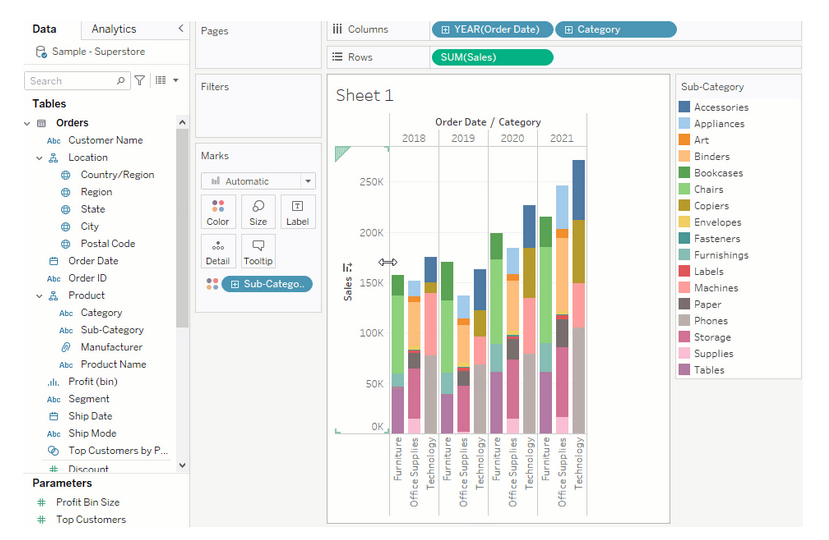
Dabei ergibt sich im Plotly Nachbau wieder ein Problem, das wir schon kennen: Da die Sub-Kategorie in den Plot integriert wird, kann die Kategorie nicht mehr über das Color-Argument abgebildet werden. Es gibt nun vier Dateninputs für die Grafik. Die Lösung für einen ähnlichen Plot wie Tableau ist ein Stacked Bar Plot mit sogenannten Facet Columns.
Tableau zeigt alle Bestelljahre in einem Plot an. Mit der Übergabe von year in facet_col werden in diesem Fall vier Einzelplots zu den jeweiligen Jahren gebaut, ohne, dass das Jahr Bestandteil einer Achse ist.
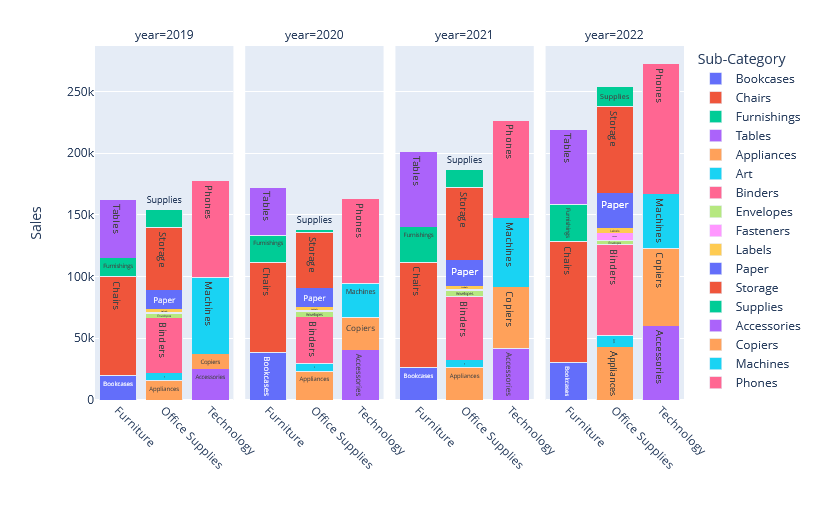
Dadurch kann Category die X-Achse normal befüllen und Sub-Category wird an das Color-Argument übergeben. Mit der Option barmode = stack werden die Subkategorien in einem Balken übereinander dargestellt. Das Ergebnis weicht optisch von der Vorlage ab, enthält inhaltlich aber die gleichen Informationen.
Diese Art von Workaround bietet sich bei Plotly öfter an, um zu einem Zielbild zu kommen. Für sehr kleine Balken, die schlecht sichtbar sind, kann neben Hovern die Zoom-Funktion genutzt werden, um alle Informationen anzeigen zu lassen.
fig_month = plx.bar(df_bar_plot_sub_segment, x='Category', y="Sales", color='Sub-Category', barmode= 'stack',text = 'Sub-Category', facet_col=df_bar_plot_sub_segment['year'], labels={'Category':''})
fig_month.update_traces(textposition='auto', textfont_size = 10, width=0.8)
fig_month.update_xaxes(tickangle=45)
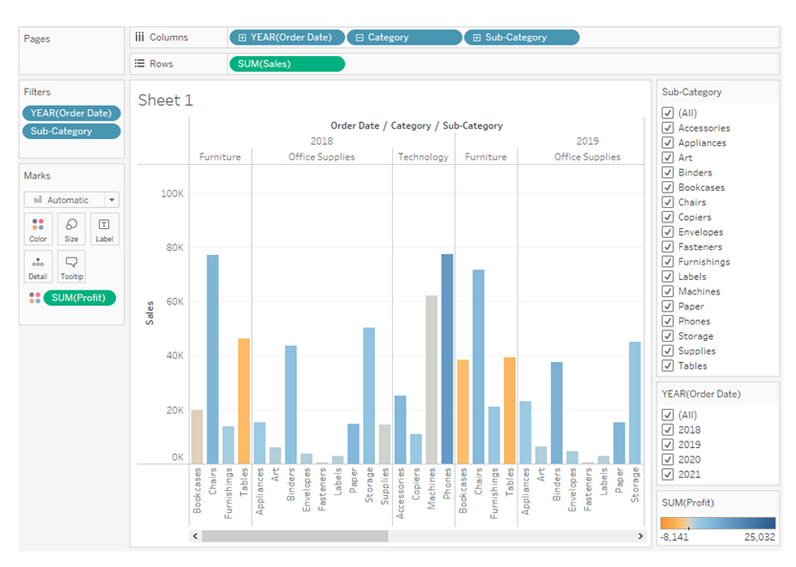
Beispiel 4: Einfärbung in der Darstellung
Im nächsten Beispiel wird der Tableau Barplot um eine Einfärbung erweitert, die den Gewinn der einzelnen Subkategorien sichtbar macht.
Dafür erweiterst du den DataFrame um die Spalte ‚Profit‘ und passt den Plotly-Aufruf der Visualisierung an. Dabei wird das text-Argument der Balken auf Sub-Category gesetzt und Profit über Color abgebildet. Im Ergebnis erhältst du eine abweichende Art der Darstellung, die aber inhaltlich nicht schlechter ist.
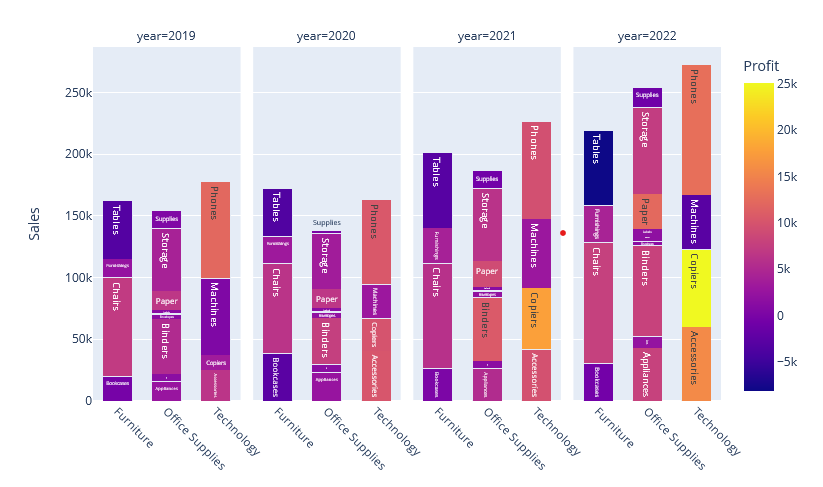
df_bar_plot_profit = Orders_df.groupby([pd.Grouper(key='Order Date', axis=0,freq='Y'), pd.Grouper(key='Category') ,
pd.Grouper(key='Sub-Category')]).agg({'Sales':'sum', 'Profit':'sum'}).reset_index()
df_bar_plot_profit['year']= pd.DatetimeIndex(df_bar_plot_profit['Order Date']).year
fig_month = plx.bar(df_bar_plot_profit, x='Category', y="Sales", color='Profit', text='Sub-Category', barmode= 'stack', facet_col=df_bar_plot_profit['year'] ,labels={'Category':''})
fig_month.update_traces(textposition='auto', textfont_size = 10, width=0.6)
fig_month.update_xaxes(tickangle=45)
Beispiel 5: Geografische Zuordnung
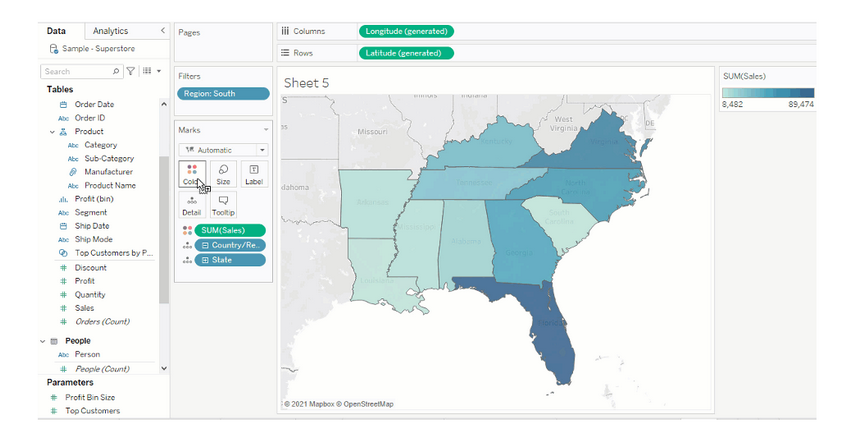
Gerade im Hinblick auf Verkaufsszahlen ist das Visualisieren auf geographischer Ebene interessant. Tools wie Tableau unterstützen die Datenanzeige auf Karten. Anhand der Spalte State/Province aus dem Beispieldatensatz kann Tableau eine automatische geographische Zuordnung vornehmen. Die Darstellung der Verkaufsszahlen für einzelne Bundesstaaten (hier in der Region ‚South‘) sieht dann wie folgt aus:
Auch Plotly unterstützt das Visualisieren von Daten auf Karten. Das Verarbeiten von Geodaten kann in unterschiedlichen Formen erfolgen. Du kannst z. B. Geopanda, Iso-Codes oder das Geo-JSON Format nutzen, um die Input-Daten auf eine Karte zu mappen. Auch die Anbindung von kommerziellen Anbietern wie Mapbox wird unterstützt. Der Umsetzung sind damit eigentlich keine Grenzen gesetzt und es kann im gewünschten Detailgrad auf Karten visualisiert werden.
In diesem Beispiel haben wir die Plotly Express Chloropleth Map genutzt. In diese Karte wurden schon Geodaten für Länder weltweit und US-Staaten integriert. Tableau erstellt automatisch eine Geo-Hierachie und ordnet z. B. der Region South die entsprechenden Bundesstaaten zu.
Das Nutzen von Hierarchien ist grundsätzlich ein großer Vorteil von Visualisierungstools. In Plotly muss die Liste der Staaten für die Ansicht der Region South händisch eingerichtet werden. Dafür filterst du zunächst den DataFrame auf das Land United States und schränkst ihn auf die Region South ein. Mit diesem DataFrame wird der Befehl plx.chloropleth ausgeführt.
df_state_sales = Orders_df[(Orders_df['Country/Region']== 'United States')& (Orders_df['Region']== 'South')].groupby(pd.Grouper(key='State/Province', axis=0,
)).agg({'Sales':'sum', 'Order ID': 'nunique'}).reset_index()
fig_state_sales = plx.choropleth(df_state_sales, locations='State/Province',locationmode="USA-states",
scope="usa",
color='Sales',color_continuous_scale="Viridis_r",)
fig_state_sales.show()
Der Code produziert eine US-Karte mit zugehöriger Legende, die Karte ist allerdings noch leer. Das liegt daran, dass die Zuordnung der State/Province-Spalte aus dem DataFrame zur Karte fehlt. Die Staaten liegen im falschen Format vor. Das locations-Argument der Choropleth Map benötigt die US-Staaten in einem Zwei-Buchstaben Format. Dafür muss ein Mapping angelegt und eine Spalte im DataFrame mit dem Staatenkürzel generiert werden. Diese Art von manueller Anpassung des Dateninputs ist ein ständiger Bestandteil des Arbeiten mit Plotly.
us_state_to_abbrev = {
"Alabama": "AL",
"Alaska": "AK",
"Arizona": "AZ",
"Arkansas": "AR",
"California": "CA",
"Colorado": "CO",
......
}
df_state_sales['State_Code'] = df_state_sales['State/Province'].map(us_state_to_abbrev)
df_state_sales['State_Code'].head()
Nun erfolgt der erneute Aufruf der plx-Funktion mit der korrekten Location-Spalte. Beim Hovern soll neben der genauen Verkaufssumme nun auch die Anzahl der Bestellungen pro Staat angezeigt werden. Dafür passen wir die Hover-Informationen bzw. -Labels an und ersetzen den automatisch festgelegten State_Code mit dem Voll-Namen State/Province. Zusätzlich soll die Ausgabe der Sales-Kennzahl in Dollar erfolgen. Ein Titel und eine angepasste Legende werden wieder mit update_layout umgesetzt. Das Resultat ist vergleichbar mit der Tableau Vorlage.
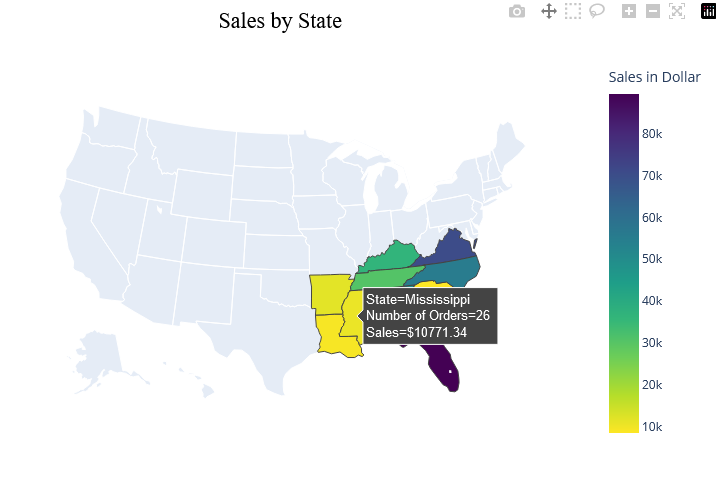
fig_state_sales = plx.choropleth(df_state_sales,locations='State_Code', locationmode="USA-states",scope="usa",color='Sales',
color_continuous_scale="Viridis_r",
hover_data={'State/Province':True,'Order ID': True,
'State_Code':False,'Sales':':$.2f'} ,
labels={'State/Province': 'State', 'Order ID':'Number of Orders', 'Sales':'Sales'})
fig_state_sales.update_layout(
title_text = 'Sales by State',
title_font_family="Times New Roman",
title_font_size = 22,
title_font_color="black",
title_x=0.45,
coloraxis_colorbar_title_text = 'Sales in Dollar'
)
Fazit
Welche wichtigen Erkenntnisse können wir am Ende dieses Selbstversuchs festhalten?
- Der Workflow von Plotly unterscheidet sich grundsätzlich stark von BI-Tools wie Tableau: Das Erstellen von Visualisierungen erfordert grundlegende Programmierkenntnisse und spricht deshalb eine andere Zielgruppe an. So würden wir z. B. nicht empfehlen, Plotly als BI Self-Service Tool auf weniger technik-affine Menschen loszulassen.
- Das Neuerstellen bzw. Nachbauen von Grafiken ist im Vergleich zu Standard-BI-Tools mit deutlich mehr Aufwand verbunden. Dies gilt sowohl für die Datenaggregation als auch für das Anpassen der Visualisierungen. Das Endergebnis in unseren Beispielen war aber in Form und Funktionalität vergleichbar.
- Plotly bietet durch das direkte Anpassen von Grafikobjekten über Code weitreichende Möglichkeiten zum Customizing, die so in den meisten Standard-BI-Tools nicht gegeben sind. Durch den damit verbundenen Aufwand ist Plotly aber wahrscheinlich eher für Anwendungsfälle geeignet, wo es darum geht eine begrenzte Anzahl von Visualisierungen umzusetzen, die sich weniger häufig ändern.
Das hier gezeigte Nachbauen von Grafiken aus dem Tableau-Tutorial ist nur der erste Schritt zur Nutzung von Open-Source-Visualisierungstools im Businesskontext. In den nächsten Teilen dieser Blog-Serie kannst du dabei sein, wenn mithilfe der Tools Plotly Dash und Streamlit aus einzelnen Grafiken ein interaktives Dashboard mit Inputmöglichkeiten für Nutzer entsteht. Stay tuned!


