

Wer mehr weiß, kommt schneller voran. Deshalb sind Informationen so wichtig für Unternehmen und Organisationen. Ob technologisch, wirtschaftlich oder organisatorisch: Die Daten, die einem Unternehmen helfen, besser zu werden, gibt es heute in großen Mengen. Sie sind verschiedenartig und stammen aus den unterschiedlichsten Quellen. Diese Datenmengen zu beherrschen, ist also keine leichte Aufgabe.
Neben den Produkten großer Anbieter kommerzieller Softwarelösungen haben sich im Laufe der letzten Jahre einige neue Initiativen gegründet, die qualitativ hochwertige Softwarelösungen als Open Source der Öffentlichkeit zur Verfügung stellen. Damit lässt sich die Abhängigkeit von kommerziellen Lösungen deutlich reduzieren. Kommerzielle Software kann entweder vollständig ersetzt werden oder deutlich reduziert werden, z. B. bei der Migration von einem Anbieter zu einem anderen. Denn die Open-Source-Konkurrenz stärkt die Position der Anwendenden, wenn es um Lizenzkosten geht.
Open Source bietet die Vorteile, zunächst ohne Lizenzen auskommen zu können und in der Regel die Unterstützung sachkundiger Nutzer der Software in Anspruch nehmen zu können. Allerdings verweisen kommerzielle Anbieter nicht zu Unrecht darauf, mit ihren Lösungen wohldefinierte Services (sowohl in Form von „service level agreements“ („SLAs“) mit zugesicherten Antwortzeiten und Eskalationspfaden als auch in Form von geplanter Produktweiterentwicklung) und somit einen Werterhalt ihrer Softwarelösung anzubieten. Trotzdem weist Open Source BI Software (OSBI) einen Reifegrad auf, der eine intensivere Betrachtung dieser Softwarelösungen rechtfertigt.
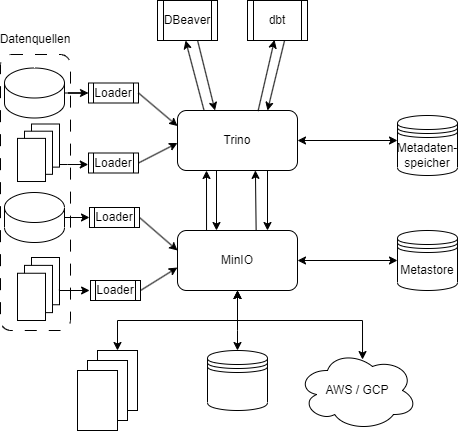
Ein Data Lake im Open-Source-Biotop
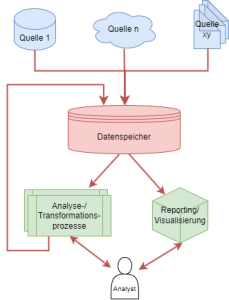
Aus Sicht des Datenanalysten ist es unerheblich, wo und wie genau die Daten gespeichert werden. Entscheidend ist, dass die Daten schnell zur Verfügung stehen, die Daten sollen vor unberechtigtem Zugriff geschützt und vor Verlust gesichert werden. Gleichzeitig sollen – aus betriebswirtschaftlicher Sicht – die Kosten für die Datenspeicherung so gering wie möglich gehalten werden. Daher werden eher teure Speicher verwendet, um häufig abgefragte Datenbestände schnell bereitstellen zu können.
Seltener genutzte Teile des Gesamtdatenbestandes werden in kostengünstigere Speicher mit eher langsamen Zugriffen ausgelagert. Gleichzeitig hat sich in den letzten Jahren ein Trend zu diversen Datenformaten etabliert: Waren vor 10 Jahren noch alle Datenquellen wohl strukturiert, ist es in modernen Umgebungen erforderlich, auch semi- und unstruktuierte Daten in Analysen einbeziehen zu können. Zudem hat nicht die Expansion der zu behandelnden Datenvolumina dazu geführt, dass Daten sukzessiv weniger in lokalen Server(-farmen) gehalten sondern eher in Cloud-Umgebungen ausgelagert werden.
Um die technische Umsetzung der Datenspeicherung von der logischen Datenmodellierung zu separieren, wird durch die Kapselung die physikalische Architektur der Speichermedien und -netze sowie die konkreten Speicherformate (als CSV- oder Parquetdateien oder in relationalen Datenbanken) verborgen. Für den Analysten sollten alle Entitäten gleich aussehen. Deshalb wird idealerweise die physische Datenmodellierung schon auf Geschäftsentitäten abgebildet.
Kapselung der physikalischen Speicherarchitektur mit MinIO
MinIO ist ein Open-Source-Produkt zur Kapselung der physikalischen Speicherarchitektur und Automatisierung von Speicherprozessen. Es wird die Speicherung on Objekten auf lokalen Festplatten ebenso unterstützt wie auf den Cloudplattform von AWS (S3), Google Cloud (Google Cloud Storage) und Microsoft (Azure Blob Storage). Ebenso werden S3-kompatible Speicher unterstützt. Daten auf unterschiedlichen Plattformen zu speichern bietet auch die Möglichkeit, dass Daten automatisiert und für den Benutzer transparent repliziert werden können. Das schützt sie gegen Datenverlust, verbessert die Verfügbarkeit und verringert die Abhängigkeit von einem Cloudservice – Anbieter.
Mehr Transparenz für den Anwendenden entsteht dadurch, dass es einen Serverprozess gibt, der die Verbindungen zu den diversen Speichern unterhält und in einem Metadatenspeicher die Lokalisation der einzelnen Objekte hinterlegt hat. Dieser zentrale Knoten ist es letztendlich auch, der die Replikation der Daten über die Grenzen des jeweiligen Speichers hinweg regelt, Daten verschlüsselt, Zugriffe auf die Objekte steuert und die Last auf die verschiedenen Speichersystem verteilt.
Zur Verschlüsselung der Daten können sowohl interne als auch externe Schlüssel verwendet werden. In jedem Fall ist es ratsam, einen auch extern bekannten Schlüssel zu verwenden, um im Störfall (sollte MinIO nicht verfügbar sein) immer noch der Zugriff auf die verschlüsselten Daten zu gewährleisten.
Datenabfrage mit Trino
Zur Abfrage der Daten bietet sich die Query Engine Trino an. Trino ist die Open-Source-Variante des kommerziellen Pakets „Starburst“, bietet eine weitgehende Integration in die MinIO-interne Query Engine und ermöglicht via spezifischer Adapter und/oder JDBC eine Anbindung an praktisch alle anderen Datenbanken und Werkzeuge.
Transformation und Analyse geladener Daten mit DBT und DBeaver
Eines der aktuell favorisierten OSBI-Werkzeuge zur Datentransformation ist DBT. Dieses sowohl als Cloud- als auch On-Premise-Variante verfügbare Tool erlaubt die Transformation von Daten in SQL.
Um mit einem SQL-Editor auf die Datenbasis zuzugreifen, bieten sich für interaktive Tätigkeiten SQL-Editoren wie der DBeaver an, der in seiner Community – Version ebenfalls als Open Source – Variante verfügbar ist.
Die Werkzeuge genauer betrachtet
Um es vorweg zu nehmen: Die unter Open-Source-Lizenzen verfügbaren Werkzeuge bieten oft gute Lösungen für spezifische Aspekte des Gesamtkonstrukts „Data Warehouse“ – aber keine umfassende Lösung. Entscheidend ist daher weniger das einzelne Werkzeug, sondern viel mehr die Interoperabilität der verwendeten Werkzeuge. Von daher ist auch ein detaillierter Blick auf die Werkzeuge sowie deren Konfiguration für ein gutes Zusammenwirken sinnvoll.
Installation und Konfiguration von MinIO
Die Anwendung MinIO besteht aus einem Server- und einem Clientprozess sowie einem SDK. Das SDK wird insbesondere zur Implementierung der Beladungsprozesse erforderlich werden, auf die ich in diesem Post nicht näher eingehe.
Der Clientprozess ist eine Kommandozeilenschnittstelle (CLI) und erweist sich für den Regelbetrieb als etwas zu unhandlich, im Störungsfall kann er aber sehr nützlich sein.
Das Herz der Anwendung ist jedoch der Serverprozess. Dieser ist für das Prozessmanagement zuständig, regelt die Datenzugriffe und nimmt die Anfragen entgegen.
Installation des Serverprozesses
Alle zur Installation erforderlichen Dateien sind auf der Homepage des Projekts verfügbar. Voraussetzung für die Installation ist ein 64-bit Betriebssystem, wahlweise Windows, Linux oder macOS. Darüber hinaus stehen auch Container für Docker oder Kubernetes zum Download bereit. Beispielhaft wird hier die Installation unter RHEL 9.1 beschrieben.
Für die Installation unter RHEL 9.1 bietet sich der Weg über rpm/yum an. Hierbei ist jedoch zu beachten, dass die Installation selbst unter dem Administrator-Account stattfindet. Entsprechend werden die ausführbaren Dateien auch unter /usr/local/bin installiert. Für die reguläre Arbeit sind die Administratorprivilegien jedoch nicht erforderlich.
#Installation des RPM-Pakets yum -y install https://dl.min.io/server/minio/release/linux-amd64/minio-20230322063624.0.0.x86_64.rpm #Umgebungsvariablen export MINIO_ROOT_USER=admin export MINIO_ROOT_PASSWORD=password #Start des Serverprozesses minio server <MinIO Pfad> --console-address ":<port>"
Der „MinIO Pfad“ ist ein Verzeichnis auf dem lokalen Filesystem. Der Benutzer, unter dem MinIO gestartet wird, benötigt auf diesem Pfad Schreib- und Leserechte. In diesem Verzeichnis werden (ggf. temporär) Daten sowie Log-Dateien gesichert. Der im Grunde frei zu definierende Port darf lediglich nicht von einem anderen Prozess belegt sein.
Nach dem Start des Serverprozesses ist die Administrationskonsole im Browser zu öffnen. In diesem Beispiel wurde der Serverprozess auf dem Port 9090 gestartet:
Sobald der Serverprozess läuft kann mit der Konfiguration begonnen werden, die den späteren Datenzugriff ermöglicht.
Konfiguration von MinIO für den Zugriff durch Trino
Damit MinIO Daten speichern kann, muss der jeweilige Speicherort definiert werden. Zudem ist es empfehlenswert, einen Benutzer zu definieren, mit dem Trino auf das System zugreift. Diese Schritte werden im folgenden Abschnitt demonstriert.
Anlegen eines Benutzers
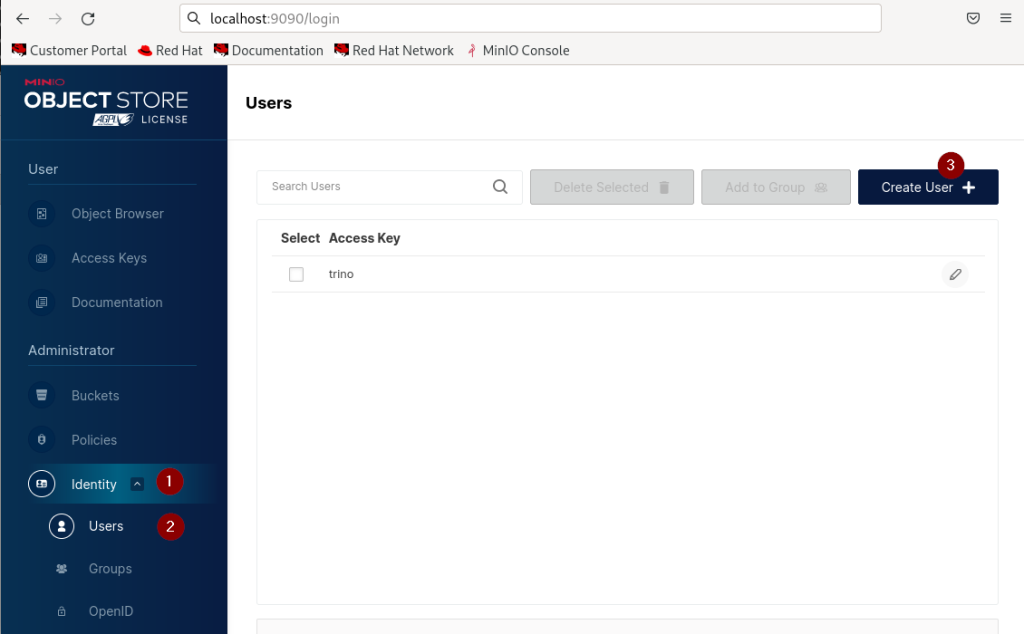
Nach dem Öffnen der Administrationskonsole wird nach Auswahl von „Identity“ (1) -> „Users“(2) eine Eingabemaske eingeblendet, die zunächst die Liste vorhandener User anzeigt. Durch Anklicken von „Create User“ (3) wird dieser Liste ein neuer Anwender hinzugefügt.
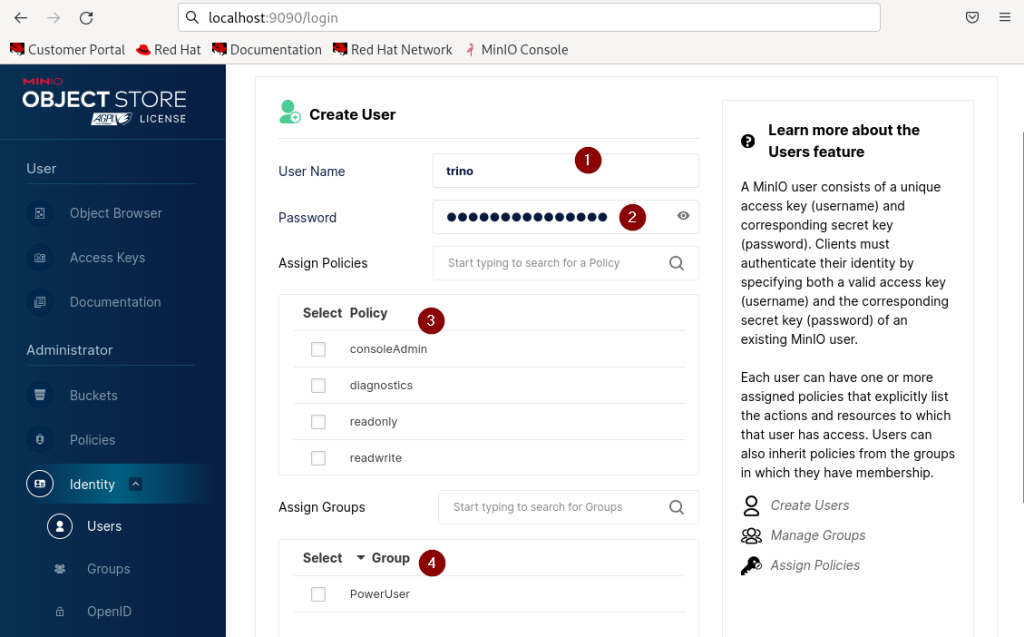
Hierzu wird eine weitere Eingabemaske aufgeblendet, welche die Parameter des neuen Benutzers abfragt. Nach Eingabe des Benutzernamens (1) und des Passwortes (2) sind noch die Berechtigungen („policies“) hinzuzufügen. Dieses geschieht entweder durch direkte Zuordnung der Policies durch Auswahl der entsprechenden Auswahlboxen (3) oder indirekt durch Zuordnung des Benutzers zu den entsprechenden Gruppen (4).
Bei der indirekter Zuordnung erhält der User die Policies, die der Gruppe zugeordnet wurden. Darüber hinaus ist eine Mischform der Zuordnung möglich: Der Benutzer kann einer Gruppe zugeordnet werden und zusätzliche Policies direkt zugeordnet bekommen. Hierbei kann es zu der Situation kommen, dass zugeordnete Policies einander widersprechen. In diesen Situationen gilt, dass
- direkt zugeordnete Policies Vorrang (Priorität) gegenüber indirekt zugeordneten Policies erhalten
- bei gleichen Prioritäten gilt die restriktivere Policy.
Konfiguration der Zugriffsschlüssel
Insbesondere im Cloud-Kontext erfolgt die Authentifizierung nicht mit Benutzername und Passwort sondern über Zugriffsschlüssel. Auch diese Verfahren werden von MinIO unterstützt. Hierbei werden personifizierte Zugriffsschlüssel (also solche, die einem Benutzer zugeordnet sind) und nicht-personifizierte Zugriffsschlüssel unterschieden.
Zur Anlage von personifizierten Zugriffsschlüsseln ist nach der Anlage des entsprechenden Benutzers dieser durch Anklicken des stilisierten Bleistifts zur Modifikation geöffnet. Es erscheint die Eingabemaske
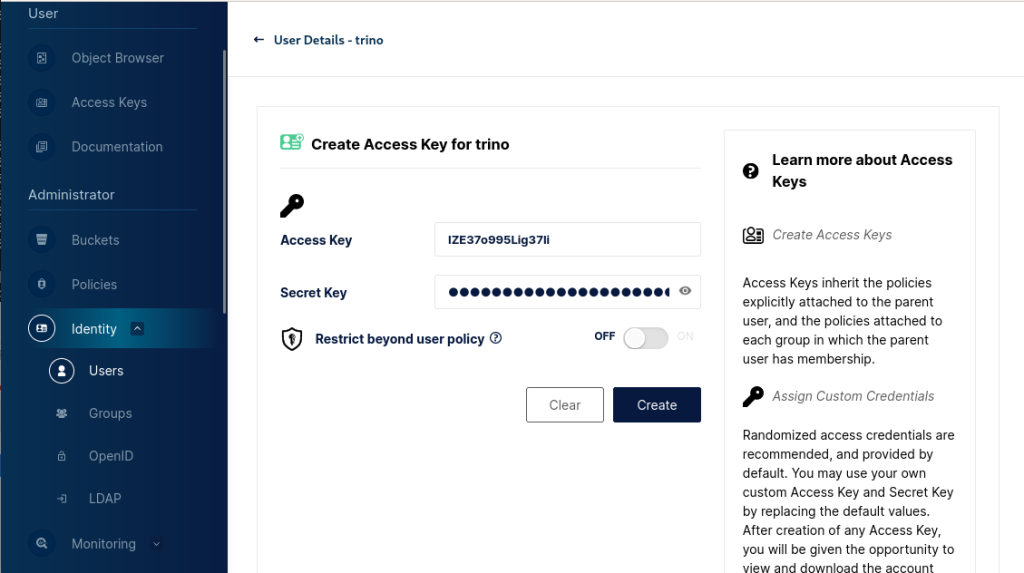
Durch Anklicken von „Create“ wird der Access Key angelegt. Allerdings sollte nicht versäumt werden, den Secret Key zu sichern – dieser kann später nicht mehr angezeigt werden. Per default „erbt“ dieser Access Key aller Policies, die dem Account zugeordnet sind. Durch Anklicken des Access Keys lässt sich ein Editorfenster öffnen, in dem die Policies explizit definiert werden können. Nähere Infos hierzu sind der Dokumentation zu entnehmen.
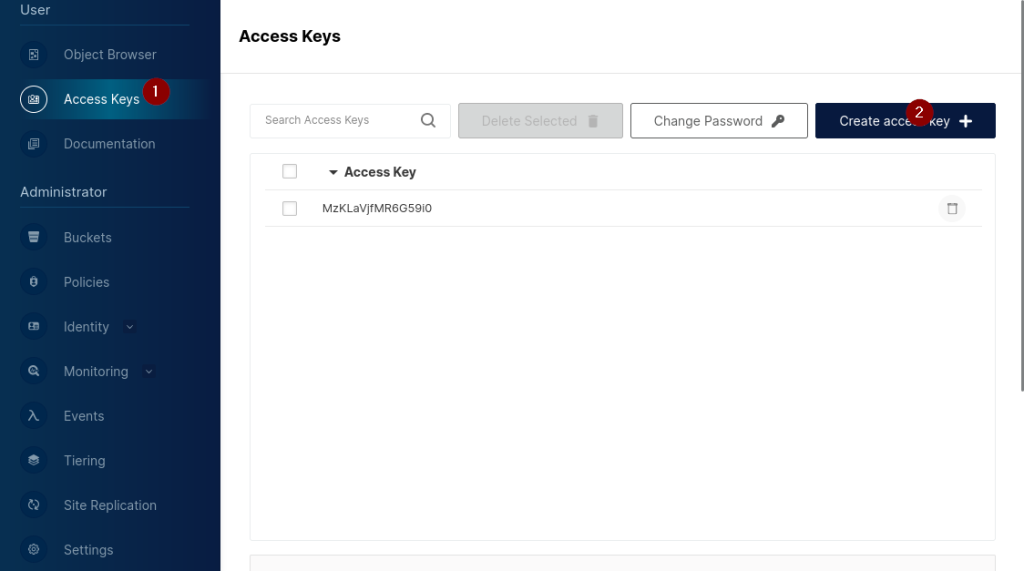
Zur Definition von nicht-personifizierten Zugriffschlüsseln ist unter der dem Menüpunkt „User“ der Unterpunkt „Access Key“ (1) auszuwählen. Wie bei den Benutzern erscheint auch hier zunächst die Liste bereits angelegter Zugriffsschlüssel sowie die Buttons zur Verwaltung dieser Liste. Hier können die vorhandenen Zugriffsschlüssel sowohl gelöscht oder verändert, aber auch neue Schlüssel angelegt werden. Zur Anlage neuer Schlüssel ist der Button „Create Access key“ (3) anzuklicken.
Eine Anmerkung: Zwar könnte unter „Change Password“ der „Secret Key“ verändert werden, da es allerdings keine Liste gibt, an Hand derer nachvollziehbar wird, an welchen Stellen dieser Secret Key verwendet wird, sollte diese Änderung nur im Notfall geschehen. Denn eine Änderung kann zur Folge haben, dass vorhandene Skripte/Programme keine Verbindung zu MinIO aufbauen können.
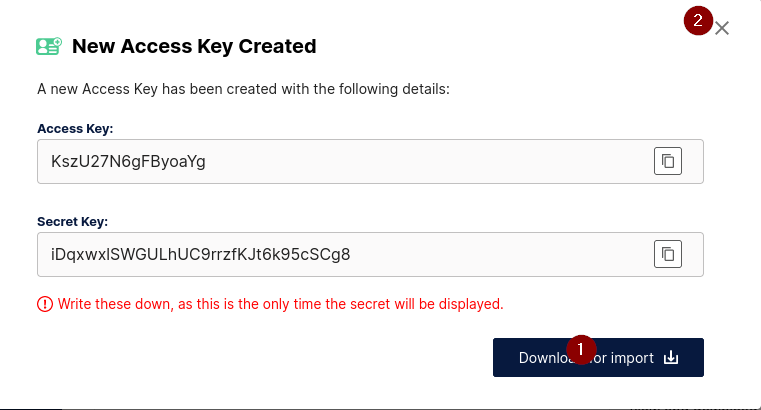
Nach Anklicken von „Create Access Key“ erscheint eine weitere Eingabemaske, mit der die generierten Keys überschrieben werden können. Vor dem Speichern sollte man jedoch unbedingt den Secret Key notieren und das Key-Paar (Access Key und Secret Key) lokal sichern. Insbesondere der Secret Key kann zu einem späteren Zeitpunkt nicht mehr eingesehen werden. Dieses Fenster ist anschließend durch Anklicken des Kreuzes in der rechten, oberen Ecke zu schließen.
Anlegen eines Datenspeichers
Die Datenspeicher sind in Buckets (analog zu den Verzeichnissen) organisiert. Jeder Bucket wird einem physikalischen Speicher zugeordnet. Dieser kann im lokalen Filesystem liegen aber genauso gut auch in einer Cloud, wahlweise in der Google Cloud, AWS Cloud oder einem Azure Blob Store.
Zum Anlegen eines Buckets wird der Menüpunkt „Buckets“ (1) ausgewählt. Auch hier erscheint wieder die Liste der bereits definierten Buckets.
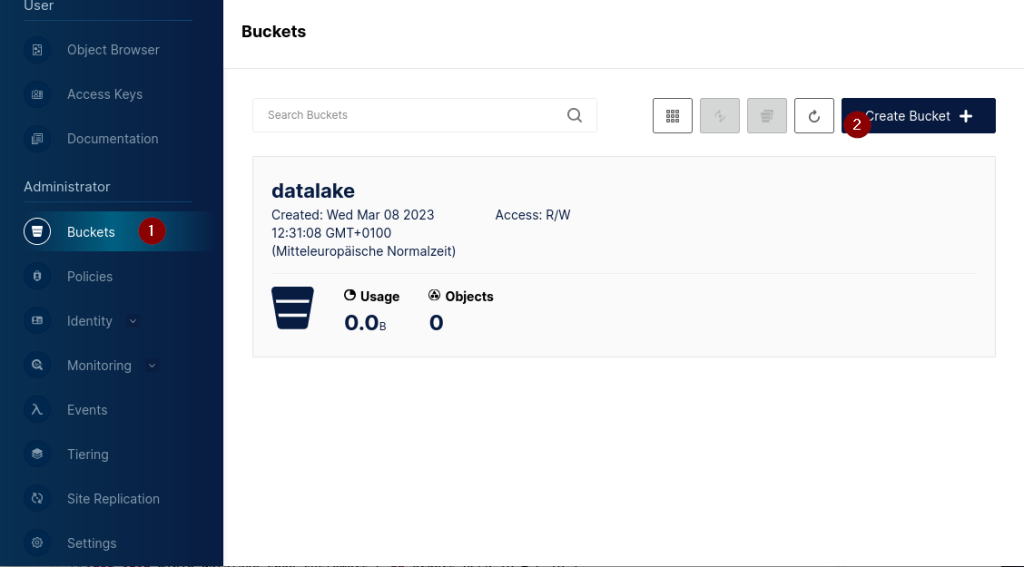
Durch Anklicken von „Create Bucket“ (2) wird eine Eingabemaske dargestellt, mit der die Eigenschaften des Buckets definiert werden:
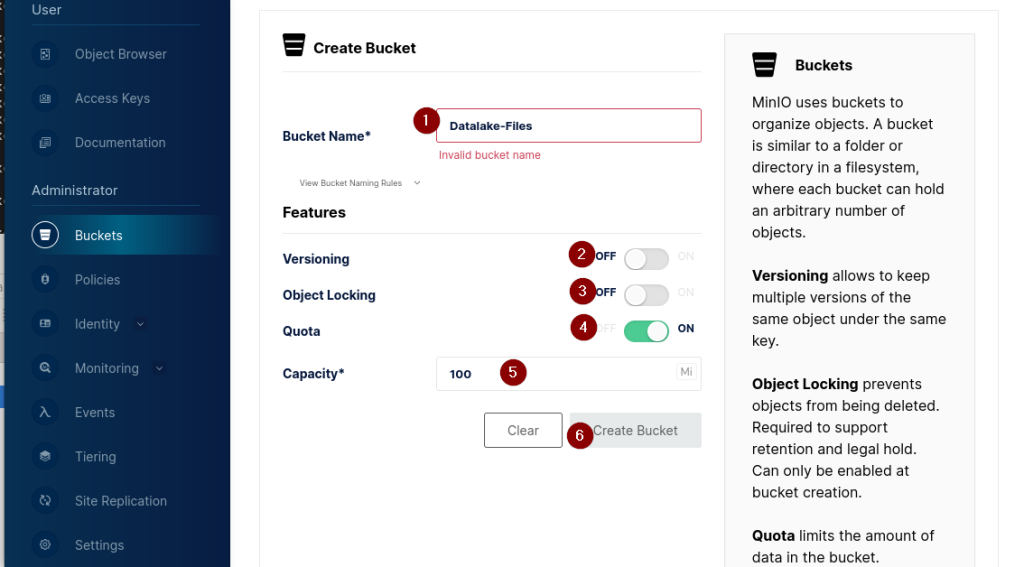
Hierzu ist zunächst der Name des Buckets anzugeben. Darüber hinaus können weitere Optionen definiert werden. So kann bei „Versioning“ (2) mehrere Versionen eines Objekts gespeichert werden. „Object Locking“ (3) gewährleistet, dass ein gespeichertes Objekt nicht überschrieben werden kann. Zudem kann mit „Quota“ (4) die maximale Größe des im Bucket vorhandenen Speichers beschränkt werden.
Wird diese Option aktiviert, ist konsequenterweise auch die Größe des Speichers (5) zu definieren. Durch Klicken von „Create Bucket“ (6) wird der Bucket mit diesen Optionen angelegt. Last but not least ist dem Bucket noch der physikalische Speicherort zuzuordnen. Hierzu ist der Menüpunkt „Object Browser“ anzuklicken und in der dargestellten Liste der gesuchte Bucket auszuwählen. Mit dem Button „Create New Path“ ist der Speicherort zu definieren. Anschließend können Daten in diesen Bucket geladen werden.
Einschränkungen in MinIO
Für die Serverprozesse von MinIO sind nur die Objekte existent, die im Metastore vorhanden sind – also nur die auch über den MinIO – Server in den Datenspeicher gelangen. Werden Dateien direkt in den Datenspeicher geschrieben, so sind diese außerhalb des MinIO-Scopes und werden somit nicht durch MinIO – Prozesse erfasst.
Trino als Query Engine
Installation und Konfiguration von Trino
Trino hat eine Prozessarchitektur, die zwischen Coordinator and Worker unterscheiden. Jeder Cluster besteht aus einem Coordinator-Prozess und mindestens einem Worker-Prozess. Der Coordinator nimmt die Anfragen entgegen und steuert die Aktivität der Worker und die Worker beabeiten die eingegangenen Abfragen und liefern die Ergebnismengen an den anfragenden Prozess. Zur Verbesserung der Performance sollte eine Serverarchitektur mit dedizierter Hardware für Coordinator- und Workerprozesse angestrebt werden.
Ähnlich wie MinIO ist Trino über den Download-Link auf der Trino-Homepage herunterzuladen. Hier gibt es entweder das Installationspaket als Tar-Ball oder als RPM-Paket für eine Serverinstallation oder die Container für Docker oder Kubernetes. Zur Serverinstallation habe ich den Tar-Ball heruntergeladen und entpackt. Bevor der Server gestartet werden kann, sind jedoch einige Konfigurationen erforderlich:
- Anpassung des Betriebssystems
Voraussetzung ist ein 64-Bit-Linuxsystem, wobei neuere Versionen des Betriebssystems zu bevorzugen sind. Zudem ist eine JRE von JAVA 17 erforderlich, mindestens in der Version 17.0.3, wobei die Java-Versionen 18 und 19 aktuell noch nicht unterstützt werden. Zudem ist noch die Installation von Python in einer der Versionen 2.6.x, 2.7.x oder 3.x notwendig.
Darüber hinaus sind Anpassungen in der Datei /etc/security/limits.conf erforderlich, zu verhindern, dass die Anzahl gleichzeitig offener Dateien durch das Betriebssystem beschränkt wird:trino soft nofile 131072 trino hard nofile 131072
Nach Entpacken des Tar-Balls findet sich in dem Verzeichnis, in das der Tar-Ball entpackt worden ist, ein weiteres Verzeichnis „etc“ und dort das Unterverzeichnis „catalog“. In diesem Verzeichnis sind folgende Dateien anzulegen:
- etc/node.properties
Ein Knoten („node“) ist eine Installationsinstanz von Trino auf einem Server. Dieser wird durch die node.id eindeutig identifiziert. Daher muss der Wert dieses Parameters entsprechend angepasst werden. Folgende Parameter sind mindestens anzugeben:node.environment=production node.id=ffffffff-ffff-ffff-ffff-ffffffffffff node.data-dir=/var/trino/data
- etc/jvm.config
Die Ansprüche an die JVM, innerhalb der Trino laufen wird, sind jenseits der Standardeinstellungen. Daher sind folgende Optionen zu spezifizieren:-server -Xmx16G -XX:InitialRAMPercentage=80 -XX:MaxRAMPercentage=80 -XX:G1HeapRegionSize=32M -XX:+ExplicitGCInvokesConcurrent -XX:+ExitOnOutOfMemoryError -XX:+HeapDumpOnOutOfMemoryError -XX:-OmitStackTraceInFastThrow -XX:ReservedCodeCacheSize=512M -XX:PerMethodRecompilationCutoff=10000 -XX:PerBytecodeRecompilationCutoff=10000 -Djdk.attach.allowAttachSelf=true -Djdk.nio.maxCachedBufferSize=2000000 -XX:+UnlockDiagnosticVMOptions -XX:+UseAESCTRIntrinsics # Disable Preventive GC for performance reasons (JDK-8293861) -XX:-G1UsePreventiveGC
- etc/config.properties
Wie oben beschrieben muss für jeden Knoten spezifiziert werden, welche Aufgabe (Coordinator oder Worker) der jeweilige Knoten übernehmen soll. Diese Definition wird in der config.properties getroffen. Für einen Coordinator sind folgende Spezifikationen aufzuführen:coordinator=true node-scheduler.include-coordinator=false http-server.http.port=<port> discovery.uri=http://<server name>:<port>
Für einen Worker sind hingegen mindestens die folgenden Festlegungen zu treffen:
coordinator=false http-server.http.port=<port> discovery.uri=http://<server name>:<port>
Jenseits von Performance-Anforderungen spricht nichts dagegen, einen Knoten so aufzusetzen, dass beide Typen auf einem Knoten laufen:
coordinator=true node-scheduler.include-coordinator=true http-server.http.port=<port> discovery.uri=http://<server name>:<port>
- etc/log.properties
Diese Datei ist optional und dient dazu, den Log-Level festzulegen (und damit den Informationsgehalt der während des Starts und Betriebs entstehenden Log-Dateien). Hier gibt es die vier Level in absteigender Reihenfolge des Informationsflusses: DEBUG, INFO, WARN und ERROR. Die Datei enthält dann:io.trino=INFO
- Catalog-Eigenschaften
Zugriffe auf Daten erfolgen in Trino über Connectors. Jeder Connector ist naturgemäß zu spezifizieren. Der Catalog enthält zunächst initial die Eigenschaften der verfügbaren Verbindungen zu den diversen Datenspeichern, dann aber auch die Metadaten zu den Objekten (Tabellen, Views, …) in den jeweiligen Datenspeichern. Schlussendlich sind es dann diese Daten, die es der Query Engine in Trino ermöglichen, Abfragen über verschiedene Datenquellengrenzen hinweg („Data Federation“) auszuführen und die Ergebnismengen der verschiedenen Unterabfragen miteinander zu verknüpfen.
Der Connector für einen Zugriff auf JMX sieht folgendermaßen aus:connector.name=jmx
Diese Datei muss als jmx.properties unter etc/catalog abgelegt werden. Für den Zugriff auf MinIO ist auch ein Connector zu spezifizieren. Hierbei wird ausgenutzt, dass MinIO wie ein S3-kompatibler Speicher zu behandeln ist. Die hierzu gehörende Property-Datei minio.properties sieht dann so aus:
connector.name=hive hive.metastore=file hive.metastore.catalog.dir=file://<trino dir>/data/minio hive.s3.endpoint=hhtp://<server name>:<port> hive.s3.path-style-access=true hive.s3.aws-ecret-key=<secret key as defined in minio> hive.s3.socket-timeout=1m hive.storage.format=CSV hive.allow-drop-table=true hive.temporary-staging-directory-path=file://<trino dir>/data/tmpq
Mit dieser Konfiguration werden sowohl die Metastore-Daten als auch temporäre Daten als Datei im lokalen Filesystem des Servers gespeichert.
- etc/node.properties
Start des Knotens
Nach Konfiguration des Knotens kann dieser gestartet werden. Hierzu dient das Kommando
<Trino Dir>/bin/launcher start :<port>
wobei <Trino Dir> das Installationsverzeichnis des Trino-Servers ist und <port> ein beliebiger aber unbelegter Port auf dem jeweiligen Knoten. Mit der Kommandooption „start“ wird der Serverprozess als Hintergrundprozess gestartet. Weitere Optionen:
run |
Startet den Serverprozess im Vordergrund (und blockiert damit das Terminal …). Zum Beenden, Ctl+C im entsprechenden Terminal abesetzen oder „launcher stop“ von einer anderen Shell absetzen. |
start |
Startet den Server im Hintergrund und gibt process ID zurück. |
stop |
Beendet den Serverprozess durch das Signal SIGTERM. |
restart |
Beendet einen laufenden Serverprozess (sofern ein Prozess läuft) und startet einen neuen. |
kill |
Beendet evtl. hängende Serverprozesse mit einem SIGKILL – Signal. |
status |
Gibt den Prozessstatus zurück. |
Wurden alle Konfigurationen korrekt durchgeführt startet der Server und das Kommando „launcher start :<port>“ quittiert den erfolgreichen Start des Servers mit der aktuellen Prozess-ID. In diesem Fall ist dann auch das Trino-Dashboard in einem Browser aufrufbar:
Direkter Zugriff auf MinIO – Daten mit DBeaver
Eines der Goodies bei der Verwendung von Trino ist, dass angebundene Objektspeicher wie SQL-Datenbanken abgefragt werden können.
Eines der am weitesten verbreiteten Werkzeuge zur Datenbankabfrage aus dem Open-Source-Segment ist die Community-Edition des DBeaver.
Nach Download und Entpacken der Installationsdatei kann DBeaver gestartet werden. Zur Konfiguration der Verbindung mit Trino sind folgende Schritte erforderlich:
- Auswählen der Option „Neue Verbindung anlegen“
- Aus der Liste möglicher Verbindungen die Option „Trino“ auswählen
- Auf dem Tab „Allgemein“ einen Verbindungsnamen eingeben
- Auf dem Tab „Verbindungseinstellungen“ -> „Allgemein“ und „Host“ den Namen des Trino-Servers (genauer: den Namen des Servers, auf dem der Coordinator läuft) eingeben, unter Port den Port des Coordinator-Prozesses
- Auf dem Tab „Verbindungseinstellungen“ -> „SSH“ die Kenndaten der SSH – Verbindung (Host -> Name des Trino – Coordinator – Servers, Port -> Port des SSH – Protokolls (default: 22), Betriebssystemuser und dessen Passwort) eingeben. Beachte: Es ist ein Verbindungsaufbau zum Server, nicht zu Trino. SSH dient lediglich als Carrier zur gesicherten Datenübermittlung.
Beim ersten Öffnen der Verbindung wird der Metastore gelesen. Alle dortigen Objekte werden in einer Datenbanktabelle angezeigt. Sie können mit SQL-Statements abgefragt werden.
Datentransformation mit DBT
Ein Werkzeug zur Datentransformation, das in der lokal zu installierenden „core – Variante“ unter der Apache 2.0 – Lizenz kostenfrei verfügbar ist, ist DBT.
Mit DBT können Datentransformationen in Form von Transformationsvorschriften erstellt werden, die in einer dem Standard-SQL sehr ähnlichen Sprache verfasst werden. Genauso gut sind Python-Skripte in DBT einfach einzubinden. Anders als ETL/ELT-Werkzeuge werden Daten nicht von einer Datenquelle abgeholt, transformiert und in ein Target-Objekt geschrieben. Vielmehr beschränkt sich DBT „auf das T in ETL“ – der Transformation von Daten. Entsprechend können Daten nur von einer Datenquelle abgeholt und auch in den gleichen Datenspeicher zurückgeschrieben werden. Insofern ist Trino eine gute Ergänzung zu DBT, da hier die genaue Datenherkunft gekapselt werden kann, sodass Trino als die einzige Datenquelle für die Transformationen in DBT erscheint.
Die Anbindung der Datenspeicher an die Transformationsengine von DBT erfolgt mittels Konnektoren. Ein Teil der Konnektoren wird vom Hersteller angeboten, die Mehrzahl wurde jedoch von Mitgliedern der Community erstellt und anderen Anwendenden zur Verfügung gestellt.
So gibt es für den Verbindungsaufbau zwischen Trino und DBT einen dedizierten Connector (dbt-trino), der auf Linux-Servern mittels
pip install dbt-trinoinstalliert werden kann.
Zur Konfiguration dieses Konnektors bedarf es einer Ergänzung der Datei profiles.yml (befinet sich per default im Verzeichnis $HOME/.dbt) um die Verbindungsdaten für Trino. Ein Beispiel hierfür:
shop_test: #Connection name
outputs:
dev: # environemnt
type: trino
method: none #authentication method, might be one of {none|kereros|ldap}
user: trino # in my case, trino is the technical user to connect to trino
password: <password> # only required if method is ldap or kerberos
host: '<trino server name>'
port: <trino port> #port the trino server is looking at
schema: <schema name in trino> # the schema name in trino is identical to the bucket name MinIO
thread: 4 #number of parallel threads to exchange data with trino
http_schema: http
session_properties:
query_max_run_time: 4h # query gets aborted if procesing takes more than 4 hours
exchange_compression: True
Die so definierte Datenquelle kann in der Quelldefinition sources.yml in DBT referenziert werden, sofern sie im Projektpfad abgelegt ist:
version 2:
sources:
- name: shop_test #use connection name as defined in profiles.yml
database: <database name>
schema: <schema name>
tables:
- name: customers
description: customer data for shop XY
columns:
- name: id
description: customer id as the tables primary key
tests:
- unique
- not_null
...
Mit dieser Quelldefinition können die hier definierten Tabellen als Datenquelle in den Transformationen referenziert werden. Die definierten Tests werden automatisch bei der Befüllung der jeweiligen Tabelle für die jeweilige Spalte ausgeführt.
Fazit
Schauen wir auf das Gesamtkonstrukt, dann fungiert Trino als nach außen als „Query Engine“ verschiedener Prozesse: Zum einem wird zumindest ein Zweig der Datenspeicherung, der Zweig über MinIO, nach außen gekapselt, sodass auch Datenquellen an MinIO Daten liefern, die vorher nicht an MinIO angebunden werden konnten. Zum zweiten gibt es aus Sicht der Analysewerkzeuge keinen zwingenden Grund, MinIO als einzigen Datenspeicher zu nutzen: Parallel zu MinIO können auch andere Datenspeicher an Trino angebunden und ebenfalls ausgewertet werden, die dann nicht über MinIO repliziert oder abgefragt werden können.
Insgesamt ist die Erstellung eines Data Lakes mit Open Source-Mitteln jedoch eine interessante Option. Ein paar Fußangeln auf dem Weg sind nicht unlösbar und eine sehr rege Community bietet ihre Unterstützung an. Klar ist aber auch, dass jedes Open-Source-Tool für sich seine Aufgabe erledigt – mal etwas hemdsärmelig über Kommandozeilenschnittstellen und mal auch recht elegant. Hier muss von Fall zu Fall unter Beachtung der jeweiligen Randbedingungen entschieden werden. Die eigentliche Kraft von Open-Source-Tools ergibt sich aber aus dem Zusammenwirken der verschiedenen Komponenten mit den Erfahrungen von der Anwendenden.


