
Kapitel 3: Wie lässt sich eine Stream-Analytics-Visualisierung durchführen?
Visualisierung der Daten mittels ELK-Stack:
In den vorangegangenen Beiträgen haben wir gezeigt, wie Apache Kafka, Apache Spark und Apache Hadoop aufgesetzt und für den Showcase miteinander verbunden wurden. Nun fehlt allerdings noch die Visualisierung der Daten, welche in diesem Beitrag vorgestellt wird.
Nachdem Apache Kafka erfolgreich aufgesetzt und getestet wurde, das Machine Learning allerdings noch etwas Zeit benötigte, wurde die Implementierung des ELK-Stack gestartet, da dieser eine Sortierung und Visualisierung der Daten ermöglicht. Es wurde eine virtuelle Maschine in Azure erstellt, welche die Komponenten des ELK beinhalten sollte. Darüber hinaus wurde darauf geachtet, dass sich die virtuelle Maschine und das Kafka-Cluster im gleichen Netz befinden, da Logstash andernfalls Probleme beim Zugriff auf Kafka gehabt hätte.
Auf die virtuelle Maschine konnte daraufhin mittels SSH zugegriffen werden, um einerseits die aktuelle Java-Version und andererseits Elasticsearch, Logstash und Kibana zu installieren. Empfehlenswert ist in diesem Zusammenhang die Nutzung der Azure Shells, welche bereits in der Azure-Oberfläche integriert sind. Es besteht die Auswahl zwischen einer einfachen Bash-Console und einer Powershell, welche weitreichende Ü„nderungen ermöglicht (z.B. das Ü–ffnen von Ports).
Nach der Installation konnten die Komponenten gestartet werden, allerdings musste darauf geachtet werden, dass die Konfigurationen von Elasticsearch (elasticsearch.yml) und Kibana (kibana.yml) derart geändert werden, dass die Weboberfläche von außen erreichbar ist. Die zugehörigen Ports müssen ebenfalls geöffnet sein.
Die Tweets werden mittels des entsprechenden Kafka-Plugin in Logstash gesammelt. Hierzu wird Logstash auf Basis einer Konfigurationsdatei gestartet, welche Informationen zu Input und Output beinhaltet und zusätzlich die Ortsinformationen eines Tweets in ein „“ für Kibana verständliches „“ Format bringt. Dieser Aspekt ist besonders wichtig, da Kibana einen geoPoint benötigt, um eine Visualisierung in Form einer Landkarte vornehmen zu können.

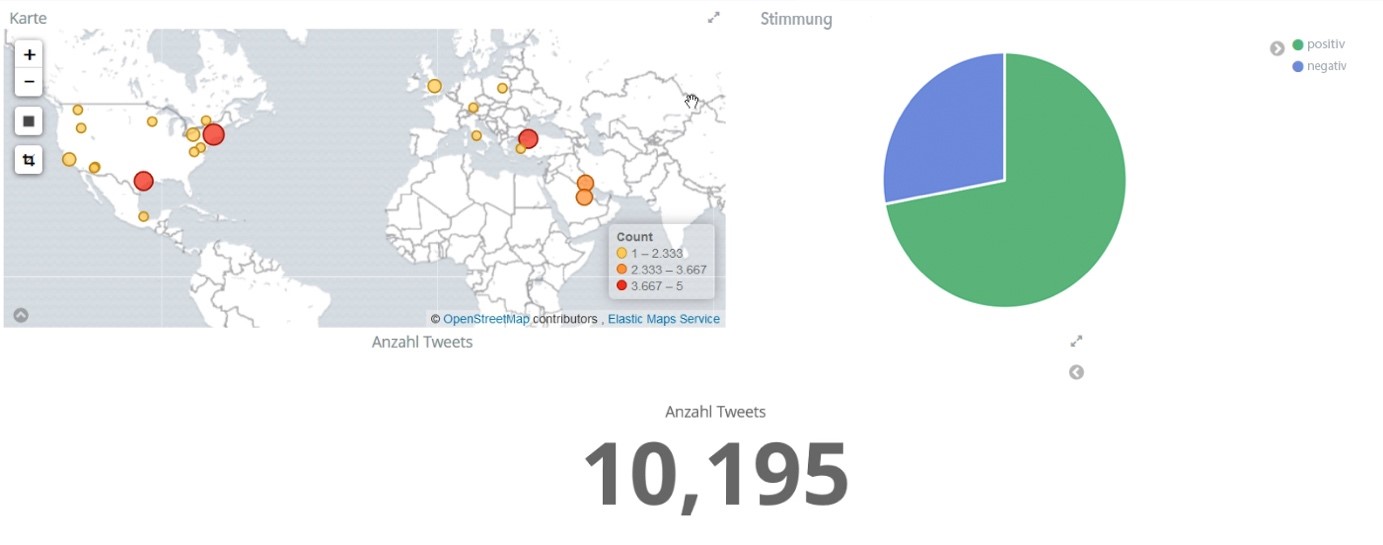
Schließlich konnte die Visualisierung in Kibana konfiguriert werden, sodass der Ort, an dem die Tweets geäußert wurden, in Form einer Kartendarstellung abgebildet wurde. Die Stimmung der Tweets wurde in einem anschließenden Schritt ergänzt, sodass das folgende Dashboard erzeugt werden konnte. Interessanterweise zeigte sich, dass in nur ca. 50 von 10000 Tweets die Ortsangabe aktiviert war, sodass auch nur diese dargestellt werden konnten.
Lessons Learned:
Abschließend kann zusammengefasst werden, dass mittels einfach zu bedienender Software eine Big Data-Architektur umgesetzt werden kann. Diese Architektur beinhaltete insbesondere Open Source Software, welche keine Lizenzkosten verursachten (bspw. Apache Kafka, Apache Spark oder Apache Hadoop). Microsoft Azure bietet in diesem Zusammenhang eine Cloud Plattform, welche einfach zu bedienen ist und dabei Cluster zur Verfügung stellt, die bereits zahlreiche konfigurierte Komponenten zum Aufbau einer Big Data Architektur enthalten. Die Kosten werden stündlich abgerechnet, dabei ist die Anzahl der Cores allerdings begrenzt und kann nur durch den entsprechenden Admin erhöht werden. Hierdurch lässt sich eine Kostenexplosion durch unsachgemäße Nutzung des Accounts vermeiden. Wichtig bleibt in diesem Kontext auch die entsprechende Löschung der Cluster, um die Kosten für die Nutzung gering zu halten. Ein Ausschalten der Cluster hilft hier leider nicht weiter, da die Kosten für die Cluster unabhängig davon entstehen, ob diese genutzt werden.
Darüber hinaus stehen zum aktuellen Zeitpunkt bereits viele Guidelines und Informationen für die Nutzung der Microsoft Azure Komponenten zur Verfügung, sodass der Einstieg insgesamt einfach fällt



