
Kapitel 2: Wie erzeugen wir aus Tweets Stimmungen und wo speichern wir Daten ab?
Apache Spark als Framework für maschinelles Lernen
Im vorangegangenen Beitrag sind wir darauf eingegangen, wie Apache Kafka in Microsoft Azure aufgesetzt und konfiguriert wird. Im folgenden Abschnitt geht es ergänzend hierzu um die Konfiguration von Apache Spark und Apache Hadoop.
Während sich ein Team mit der Umsetzung von Apache Kafka und mit der Erstellung des zugehörigen Notebooks beschäftigte, arbeitete ein zweites Team an dem Machine Learning in Apache Spark und ein drittes Team beschäftigte sich mit dem DWH Offloading mittels Hadoop.
Zur Nutzung der Spark ML Komponente wurde erneut auf ein Azure HDInsight Cluster zugegriffen, welches eine vorkonfigurierte Version von Apache Spark bereitstellt. Microsoft empfiehlt für die Steuerung der Cluster die Nutzung von Jupyter Notebooks.
Somit wurde ein Jupyter Notebook angelegt, um ein Modell zu erstellen, während ein zweites Jupyter Notebook dazu dient, den Stream zu analysieren und dabei die entsprechende Stimmung (1= positiv, 0=negativ) zu den Tweets zu ergänzen. Theoretisch betrachtet, wurden aus jedem Tweet nur die relevanten Worte isoliert und in einzelne Bestandteile (Tokens) zerlegt. In diesem Kontext ist es wichtig, dass nicht nur das einzelne Wort, sondern auch der Zusammenhang zwischen dem vorangestellten und dem nachfolgenden Wort erkannt wird, um ein negiertes positives Wort erkennen zu können. Jedes Wort erhält anschließend einen Wert und wird mittels logistischer Regression einem Wert angenähert. Falls der Wert höher als 0,5 ist, so ist dieser positiv, andernfalls ist der Wert negativ. Für das Training des Modells wurden 1,6 Millionen Datensätze verwendet, die jeweils einen Tweet und eine entsprechende Stimmung beinhalten. Diese Datensätze wurden durch sentiment140.com bereits zuvor ausgewertet.
Im Folgenden ist sichtbar wie der Beispieltweet: „Das Wetter ist heute aber schön. Super Sache“ ausgewertet wird:
„Das“ -> Neutral -> 0
„Wetter“ -> Neutral -> 0
„ist“ -> Neutral -> 0
„heute“ -> Neutral -> 0
„aber“ -> Neutral -> 0
„schön“ -> Positiv -> +1
„Super“ -> Positiv -> +1
„Sache“ -> Neutral -> 0
Damit ist der Wert +2. Dieser Wert (+2) wird in die Formel eingesetzt, welche in der unten stehenden Abbildung dargestellt ist. Es ergibt sich ein Wert von ca. 0,88. Damit ist die Stimmung des Tweets positiv!
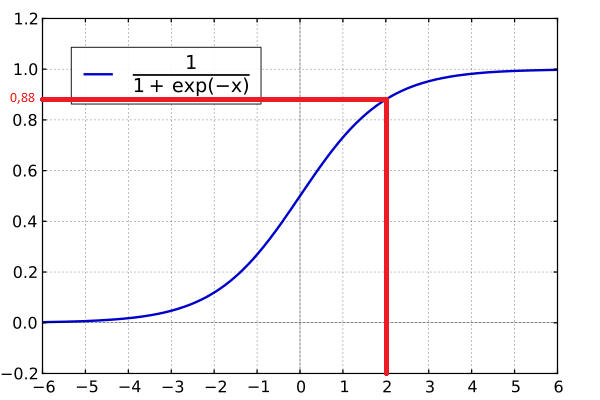
Das erzeugt Modell und die gestreamten Tweets werden in einem erstellten Azure Data Lake abgelegt. Zur einfachen Navigation durch die Dateien empfiehlt sich die Nutzung des Azure Storage Explorers.
Umsetzung eines DWH-Offloading mittels Hadoop und Sqoop
Während der Umsetzung des Machine Learnings, wurde das DWH Offloading umgesetzt, welches das Importieren von Daten aus einem DWH in einen kostengünstigeren Speicher ermöglichen sollte. Da sich keine geeigneten Daten finden ließen, wurde die Funktionalität mittels Beispieldaten getestet.
In einem ersten Schritt wurde eine SQL-Datenbank als Ressource in Azure angelegt, um die Beispieldaten in dieser Datenbank abzuspeichern. Azure bietet auch hier eine vorkonfigurierte Ressource an, die in wenigen Schritten aufgesetzt ist. Anschließend wurde ein Hadoop-Cluster aufgesetzt, welches der Speicherung der importierten Daten dient. In diesem Zusammenhang empfiehlt sich die Nutzung eines Azure HD-Insight Clusters, welches einen kompletten Hadoop Stack vorkonfiguriert hat (Hive, Sqoop, HDFS).
Zur Vereinfachung der Kommunikation zwischen Datenbank und Hadoop-Cluster wurden beide Ressourcen im gleichen Netzwerk angelegt, wie es auch schon bei Apache Kafka und Apache Spark durchgeführt wurde. Microsoft empfiehlt für Azure die Zuweisung eines virtuellen Netzwerks bei der Erzeugung eines Clusters.
Zur Übertragung der Daten wurde Apache Sqoop verwendet. Hierzu müssen Jobs angelegt werden, die eine Übertragung der Daten von der relationalen Datenbank zu Hadoop anstoßen. Ein Beispiel für einen Sqoop-Job ist im Folgenden dargestellt:
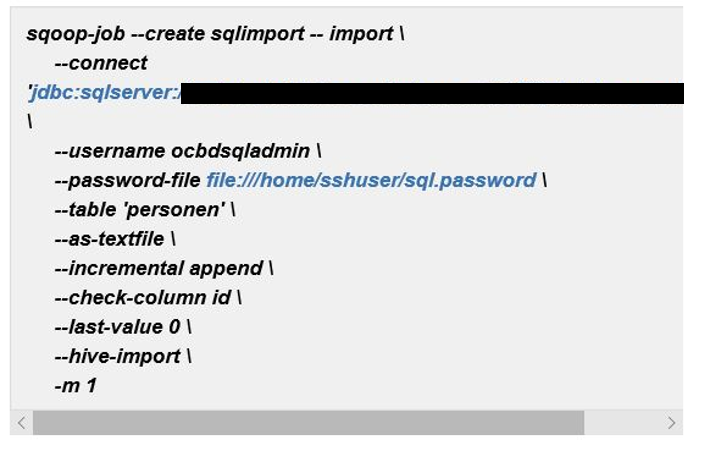
Dieser Job wurde allerdings in einer inkrementellen, manuellen Form angelegt, sodass er jedes Mal einzeln hätte angestoßen werden müssen. Daher wurde ein CronTab angelegt, der dazu dient, den Sqoop-Job minütlich auszuführen.
Im abschließenden Beitrag werden wir zeigen, wie wir die Visualisierung der Tweets aufgebaut haben. Ergänzend hierzu möchten wir auf die Lessons Learned eingehen, die sich in diesem Azure Projekt ergeben haben.



