
Ansible hat sich in den letzten Jahren zu einem einsteigerfreundlichen und wichtigen Tool der Automatisierung entwickelt. Durch die Einfachheit können tägliche, sich wiederholende Arbeiten simpel automatisiert werden. Durch die zunehmende Digitalisierung rückt auch Big Data immer mehr in den Vordergrund. Das Datenwachstum nimmt exponentiell zu. Traditionelle Datenbanklösungen reichen oft nicht mehr aus und neuere „Open Source“-Technologien drängen in den Markt. Big-Data-Distributionen vereinen diese verschiedenen Technologien und Services und stellen diese dem Kunden in einer übersichtlichen Administrationsoberfläche zur Verfügung.
Dieser Blogeintrag handelt von einer Installation eines Big Data Clusters mit Hilfe von Ansible, welches das Grundgerüst darstellt. Playbooks werden zur Vorbereitung einer manuellen Cluster-Installation via Cloudera Manager auf die Nodes ausgerollt. Es stellt sicher, dass die Nodes im Verbund mit gleichem OS, Packages, Parametern usw. aufgebaut werden. Weiterführende Informationen gibt es zum Beispiel im DOAG Artikel – : http://www.opitz-consulting.com/fileadmin/user_upload/Collaterals/Artikel/red-stack-magazin-2016-05_Warum-Ansible-fuer-DevOps-eine-gute-Wahl-ist_Simon-Hahn_sicher.pdf
In einem Cloudera Cluster übernimmt jeder Node unterschiedliche Rollen.
Unterteilt wird in NameNode, StandbyNode, DataNode, EdgeNode, Cloudera-ManagerNode (Siehe Abbildung).
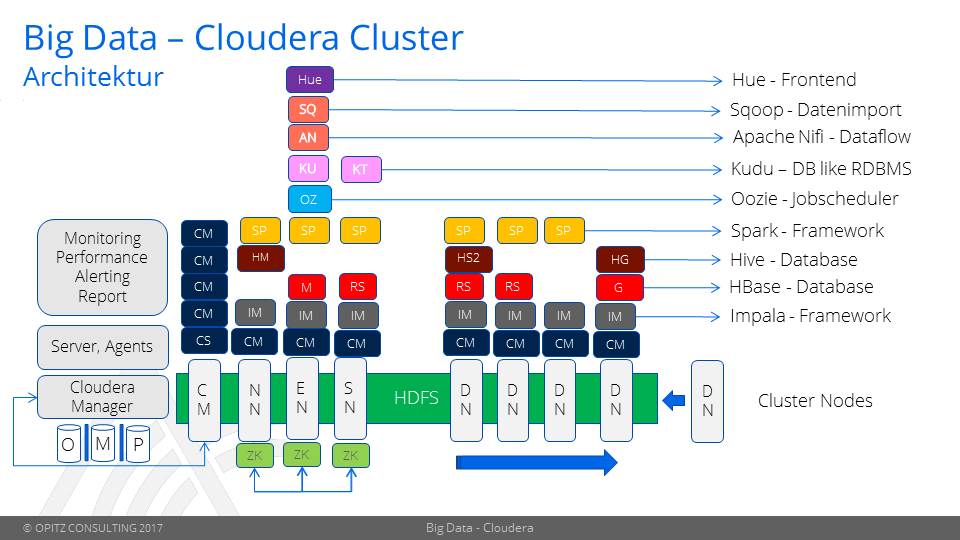
NN: Der NameNode ist die zentrale Master-Komponente und verwaltet die Metadaten für alle gespeicherten Daten auf allen DataNodes. Dazu unterhält er eine Liste mit den aktuellen Speicherorten der Blöcke von Verzeichnissen und Dateien sowie ein Journal-File mit den aktuellen Dateioperationen. Auf Basis dieser beiden Dateien kann er Anfragen nach Dateien jederzeit beantworten, speichert aber selbst keine Daten.
SN: Der StandbyNode übernimmt die Aufgabe des NameNode im Falle eines Ausfalls.
CM: Cloudera Manager stellt die Oberfläche zur Installation, Verwaltung und Administration des Clusters.
EN: Der EdgeNode gilt als Interface zwischen äußerem Netzwerk und internem Cluster. Auf ihm werden oftmals Datenintegrationstools wie Scoop und andere Applikationstools installiert.
DN: DataNodes sind die Slave-Komponenten der Architektur, die lediglich für die Datenspeicherung zuständig sind. Sie sind „einfach“ gestrickte Elemente, über die die Skalierung des Clusters erreicht wird.
O|M|P = Cloudera Manager benötigt eine Oracle oder MySQL oder Postgres.
Der Clusterunterbau läuft auf dem javabasierten, verteilten Dateisystem Hadoop, bzw. HDFS. Über dieses werden die Daten blockweise in einzelnen DataNodes gespeichert.
Ansible 2.1.0 als Hilfe
In meinem Git verwaltetem Ansible Cloudera Projekt werden die einzelnen Nodes in der „hosts“-Datei von Ansible definiert.
hosts:
[cloudera_manager]
cloudera-cm
[cloudera_edgenodes]
cloudera-en
[cloudera_namenodes]
cloudera-nn
cloudera-sn
[cloudera_nodes]
cloudera-dn1
cloudera-dn2
cloudera-dn3
cloudera-dn4
In den einzelnen „yml“-Dateien (cloudera-cm.yml) im „host_vars“-Verzeichnis werden explizit spezielle Parameter gesetzt.
Beispiel: cloudera-cm.yml
—
# SYSTEM Parameter
hostname: cloudera-cm
ip_address_public: 192.168.56.70
domain: localdomain
common_root_password: XXXXX
# Kernelparameter
kernelparameter:
– { name: ‚vm.swappiness‘, value: ’10‘ }
# MYSQL Parameter for cloudera_cm
# https://github.com/geerlingguy/ansible-role-mysql
overwrite_global_mycnf: yes
mysql_user_home: /root
mysql_user_name: root
mysql_user_password: nicht_wichtig J
mysql_root_password_update: yes
mysql_enabled_on_startup: yes
mysql_port: „3306“
mysql_bind_address: ‚0.0.0.0‘
mysql_datadir: /var/lib/mysql
# RECOMMENDED CLOUDERA MANAGER MYSQL PARAMETER
mysql_transaction_isolation: READ-COMMITTED
mysql_key_buffer_size: 32M
mysql_max_allowed_packet: 32M
mysql_thread_stack: 256k
mysql_thread_cache_size: 64
mysql_query_cache_limit: 8M
mysql_query_cache_size: 64M
mysql_query_cache_type: 1
mysql_max_connections: 550
mysql_binlog_format: mixed
mysql_read_buffer_size: 2M
mysql_read_rnd_buffer_size: 16M
mysql_sort_buffer_size: 8M
mysql_join_buffer_size: 8M
mysql_innodb_file_per_table: 1
mysql_innodb_flush_log_at_trx_commit: 2
mysql_innodb_log_buffer_size: 64M
mysql_innodb_buffer_pool_size: 4G # angepasst auf 4 GB, da VM nur 8GB hat
mysql_innodb_thread_concurrency: 8
mysql_innodb_flush_method: O_DIRECT
mysql_innodb_log_file_size: 512M
mysql_sql_mode: STRICT_ALL_TABLES
mysql_databases:
– name: amon
encoding: utf8
– name: rman
encoding: utf8
– name: metastore
encoding: utf8
– name: sentry
encoding: utf8
– name: nav
encoding: utf8
– name: navms
encoding: utf8
– name: cmf
encoding: utf8
– name: oozie
encoding: utf8
– name: hue
encoding: utf8
– name: hive
encoding: utf8
mysql_users:
– name: amon
host: „%“
password: XXXXX
priv: „amon.*:ALL“
– name: rman
host: „%“
password: XXXXX
priv: „rman.*:ALL“
– name: metastore
host: „%“
password: metastore
priv: „metastore.*:ALL“
– name: sentry
host: „%“
password: XXXXX
priv: „sentry.*:ALL“
– name: nav
host: „%“
password: nav
priv: „nav.*:ALL“
– name: navms
host: „%“
password: XXXXX
priv: „navms.*:ALL“
– name: cmf
host: „%“
password: cmf
priv: „cmf.*:ALL“
– name: oozie
host: „%“
password: oozie
priv: „oozie.*:ALL“
– name: hue
host: „%“
password: XXXXX
priv: „hue.*:ALL
– name: hive
host: „%“
password: XXXXX
priv: „hive.*:ALL“
Beispiel: cloudera-dn1.yml
# SYSTEM Parameter
hostname: cloudera-dn1
ip_address_public: 192.168.56.61
domain: localdomain
common_root_password: xxxxxxx
kernelparameter:
– { name: ‚vm.swappiness‘, value: ’10‘ }
Mit weiteren Rollen, wie „cloudera_manager“, „cloudera_manager_agent“ und „cloudera_prereqs“, die zuvor erstellt wurden, wird angegeben, was und welche Parameter auf dem jeweiligen Linux Host installiert werden.
Als Betriebssystem dient Centos 7.1, das zuvor für jeden Host installiert wurde. Weiterführende Anpassungen werden nun per Ansible Playbook deployed, welches jede oben genannte Rolle auf den Servern ausführt. Als grundlegende Datenbank für den Cloudera Manager wurde per frei erhältlichem „ansible-role-mysql“ eine MySQL-Datenbank auf den Cloudera Manager Host (CM) mit entsprechenden Benutzern ausgerollt und installiert. Diese wird für die manuelle Installation des Cloudera Clusters benötigt.
Weitere Rollen sind nur teilweise aufgelistet. Sie beinhalten grundlegende Schritte wie Installation von Paketen, Grundvoraussetzungen für eine optimierte Installation.
Siehe Link: https://www.cloudera.com/documentation/enterprise/release-notes/topics/rn_consolidated_pcm.html
Beispiel: cloudera_manager.yml
—
# cloudera_manager and cloudera_manager_agent installation via ansible
# dnsmasq
– name: Install dnsmasq
yum: pkg=dnsmasq state=present
tags: packages
ignore_errors: yes
# dnsmaq einschalten
– name: Ensure dnsmasq is enabled on boot.
service: „name=dnsmasq.service state=started enabled=yes“
register: dnsmasq_service_configuration
tags: dnsmasq_service_configuration
# copy dnsmasq.conf
– name: copy template dnsmasq.conf
template: src=dnsmasq.conf.j2 dest=/etc/dnsmasq.conf mode=0644 owner=root group=root
tags: copy_dnsmasq_config
– name: add cloudera-cdh5 Repo
yum_repository:
name: cloudera-cdh5
description: Packages for Cloudera’s Distribution for Hadoop, Version 5, on RedHat or CentOS 7 x86_64
baseurl: https://archive.cloudera.com/cdh5/redhat/7/x86_64/cdh/5/
gpgkey: https://archive.cloudera.com/cdh5/redhat/7/x86_64/cdh/RPM-GPG-KEY-cloudera
gpgcheck: yes
– name: add cloudera-manager Repo for RedHat 7
yum_repository:
name: cloudera-manager
description: Packages for Cloudera’s Distribution for Hadoop, Version 5, on RedHat or CentOS 7 x86_64
baseurl: https://archive.cloudera.com/cm5/redhat/7/x86_64/cm/5/
gpgkey: https://archive.cloudera.com/cm5/redhat/7/x86_64/cm/RPM-GPG-KEY-cloudera
gpgcheck: yes
tags: cloudera_installation
when: ansible_os_family == „RedHat“ and ansible_distribution_major_version == „7“
– name: add cloudera-manager Repo for RedHat 6
yum_repository:
name: cloudera-manager
description: Packages for Cloudera’s Distribution for Hadoop, Version 5, on RedHat or CentOS 7 x86_64
baseurl: https://archive.cloudera.com/cm5/redhat/6/x86_64/cm/5/
gpgkey: https://archive.cloudera.com/cm5/redhat/6/x86_64/cm/RPM-GPG-KEY-cloudera
gpgcheck: yes
tags: cloudera_installation
when: ansible_os_family == „RedHat“ and ansible_distribution_major_version == „6“
– name: add cloudera-manager Repo for Redhat 5
yum_repository:
name: cloudera-manager
description: Packages for Cloudera’s Distribution for Hadoop, Version 5, on RedHat or CentOS 7 x86_64
baseurl: https://archive.cloudera.com/cm5/redhat/5/x86_64/cm/5/
gpgkey: https://archive.cloudera.com/cm5/redhat/5/x86_64/cm/RPM-GPG-KEY-cloudera
gpgcheck: yes
tags: cloudera_installation
when: ansible_os_family == „RedHat“ and ansible_distribution_major_version == „5“
# Install Cloudera Manager Server
– name: Install cloudera-manager-daemons
yum: pkg=cloudera-manager-daemons state=present
tags: cloudera_installation
ignore_errors: yes
– name: Install cloudera-manager-server
yum: pkg=cloudera-manager-server state=present
tags: cloudera_installation
ignore_errors: yes
– name: Overwriting db.properties
template: src=db.properties.j2 dest=/etc/cloudera-scm-server/db.properties owner=cloudera-scm group=cloudera-scm mode=0644
ignore_errors: yes
tags: copy_templates
# test
– name: Ensure Cloudera is started and enabled on boot.
service: „name=cloudera-scm-server state=stopped enabled=yes“
register: cloudera_service_configuration
tags: cloudera_service_configuration
– name: Ensure Cloudera is started and enabled on boot.
service: „name=cloudera-scm-server state=started enabled=yes“
register: cloudera_service_configuration
tags: cloudera_service_configuration
Sobald die einzelnen DataNodes per „Ansible Playbook“ vorbereitet und ausgerollt wurden, wird automatisch der „Cloudera Manager Server Service“ und der „Cloudera Manager Agent Service“ auf den entsprechenden Nodes gestartet und die manuelle grafische Installation der Cloudera Distribution kann per Browser beginnen.
Software Installation
Basierend auf möglichst gleich vorkonfigurierten Systemen, wird über den Cloudera Manager die weitere Clustereinrichtung getätigt. Durch Starten des „cloudera-scm-servers“ kann über die Weboberfläche der Cluster konfiguriert werden. Standardport ist 7180.
http://cloudera-cm:7180
Clusterkonfiguration
Step 1 – Auswahl der zu installierenden Dienste
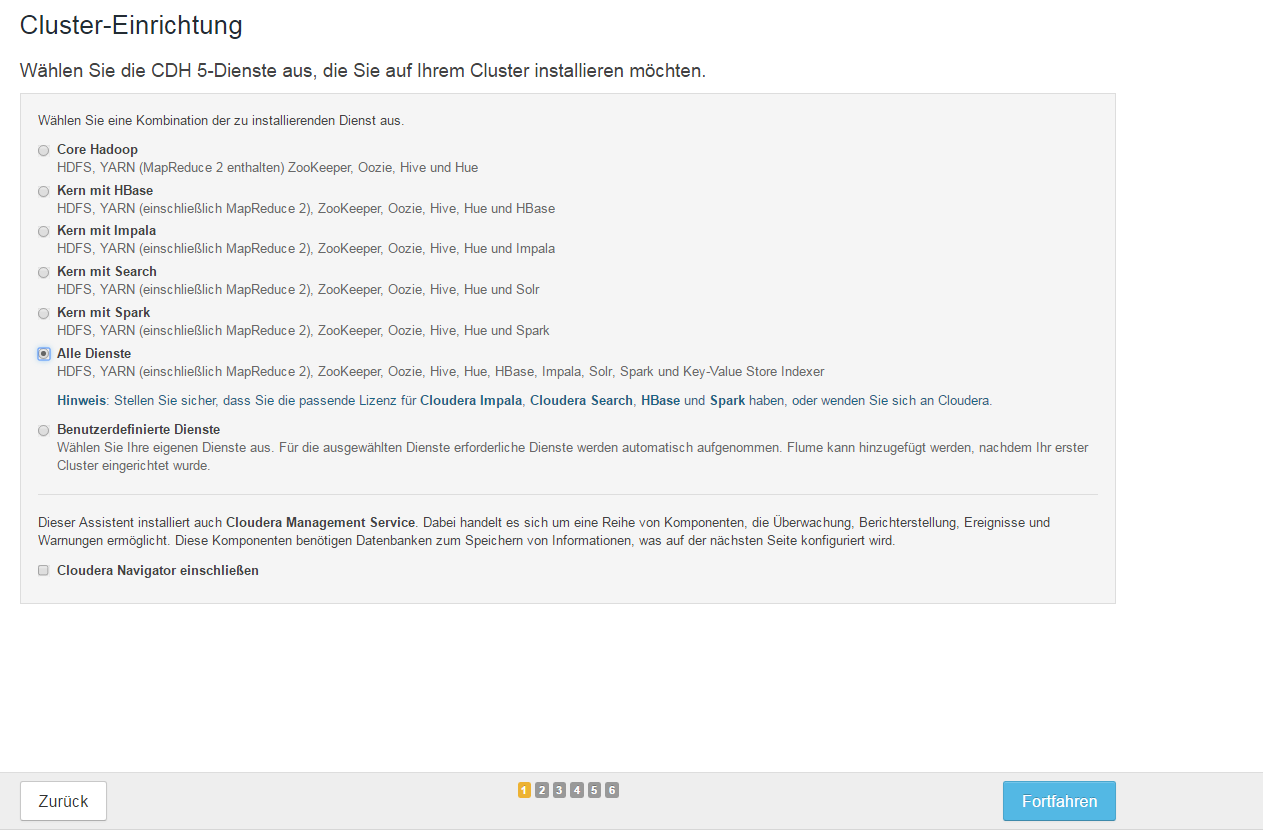
Auswahl der Pakete, die entsprechend installiert werden müssen.
Step 2 „“ Rollenzuweisungen
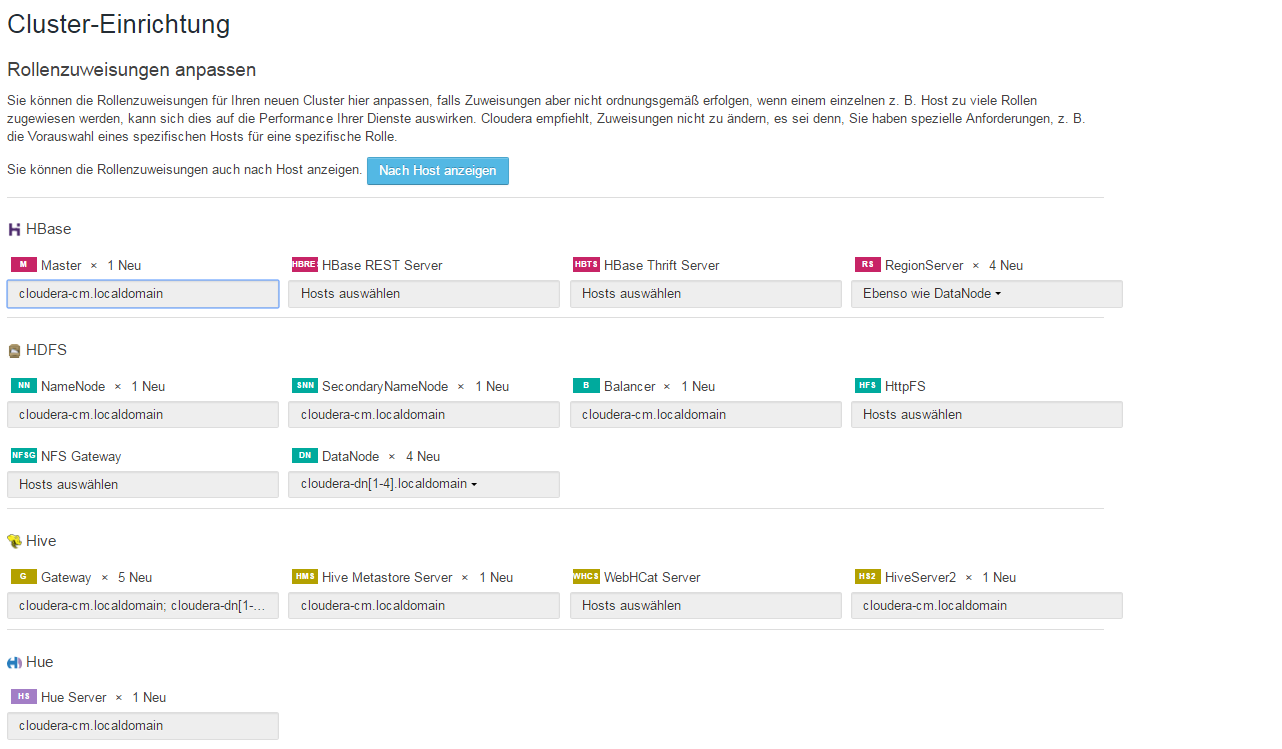
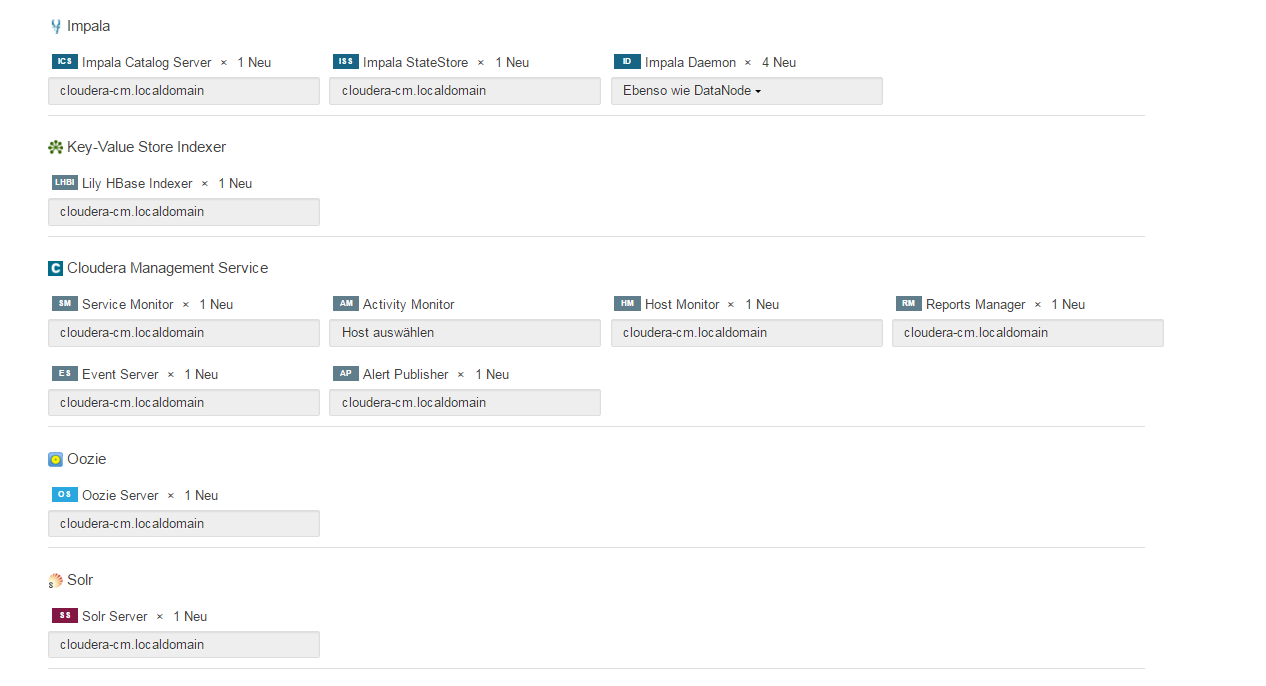
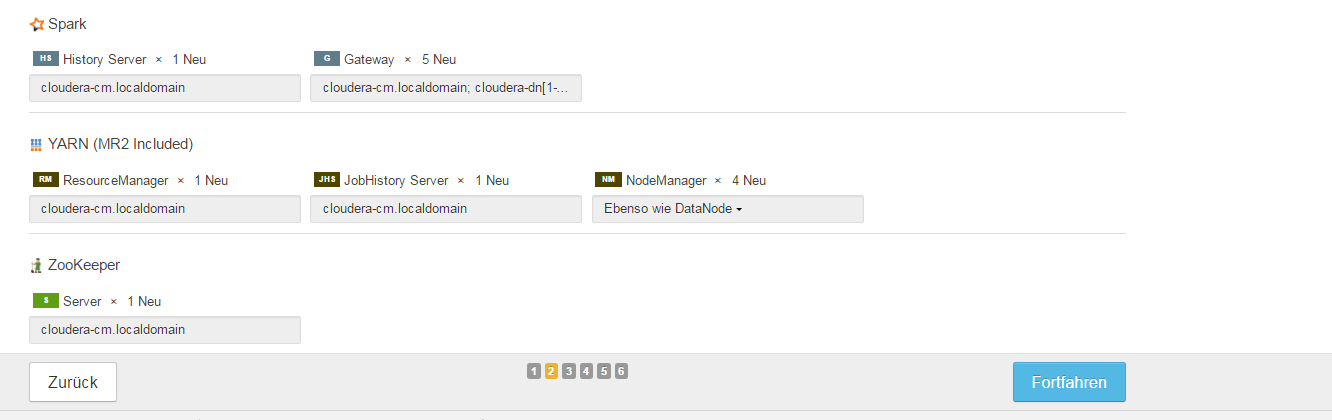
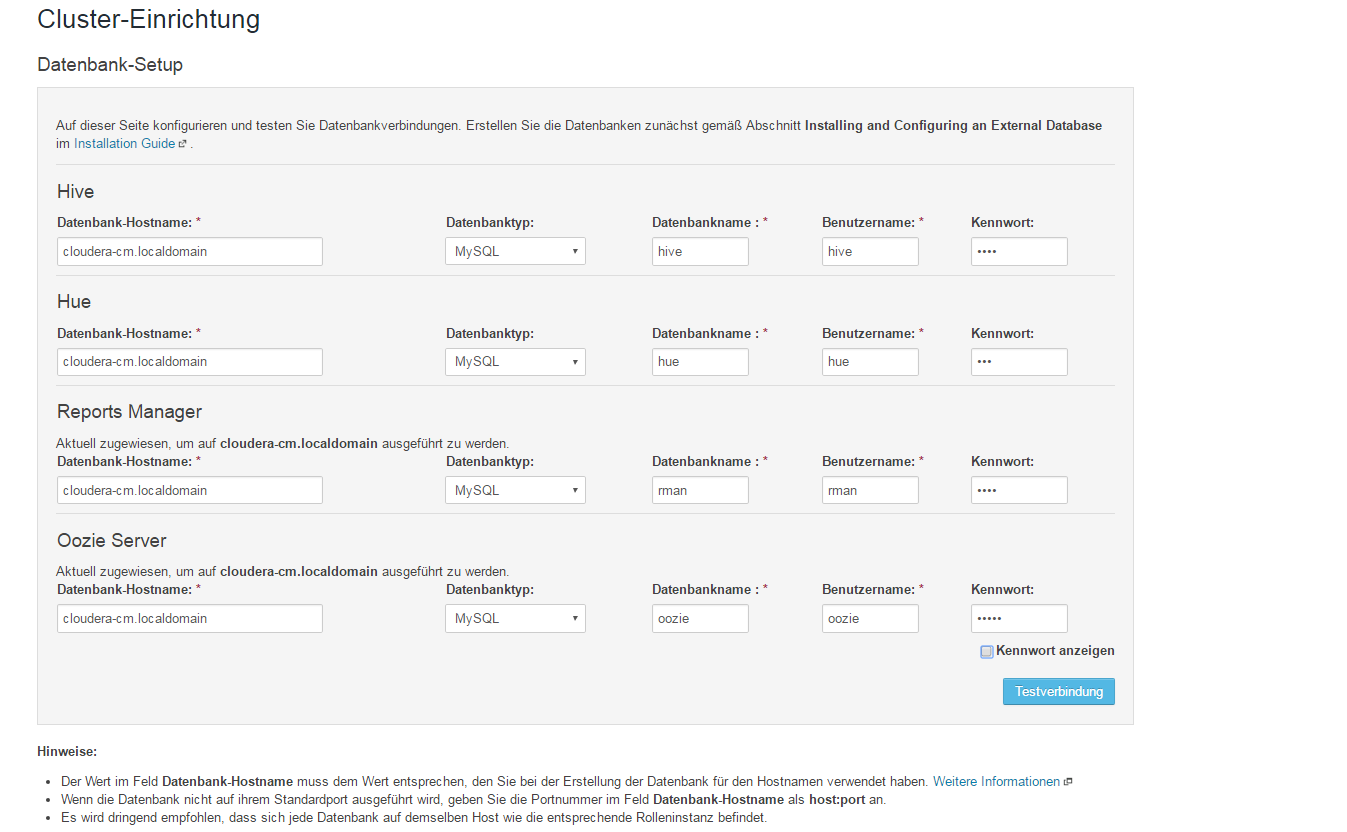
Step 3 „“ Datenbank-Setup
MySQL-Zugangsdaten werden hier manuell eingetragen. Diese stimmen mit den Ansible MySQL-Passwörtern überein.
Step 4 – Clusteränderungen
Gegebenenfalls anpassen.
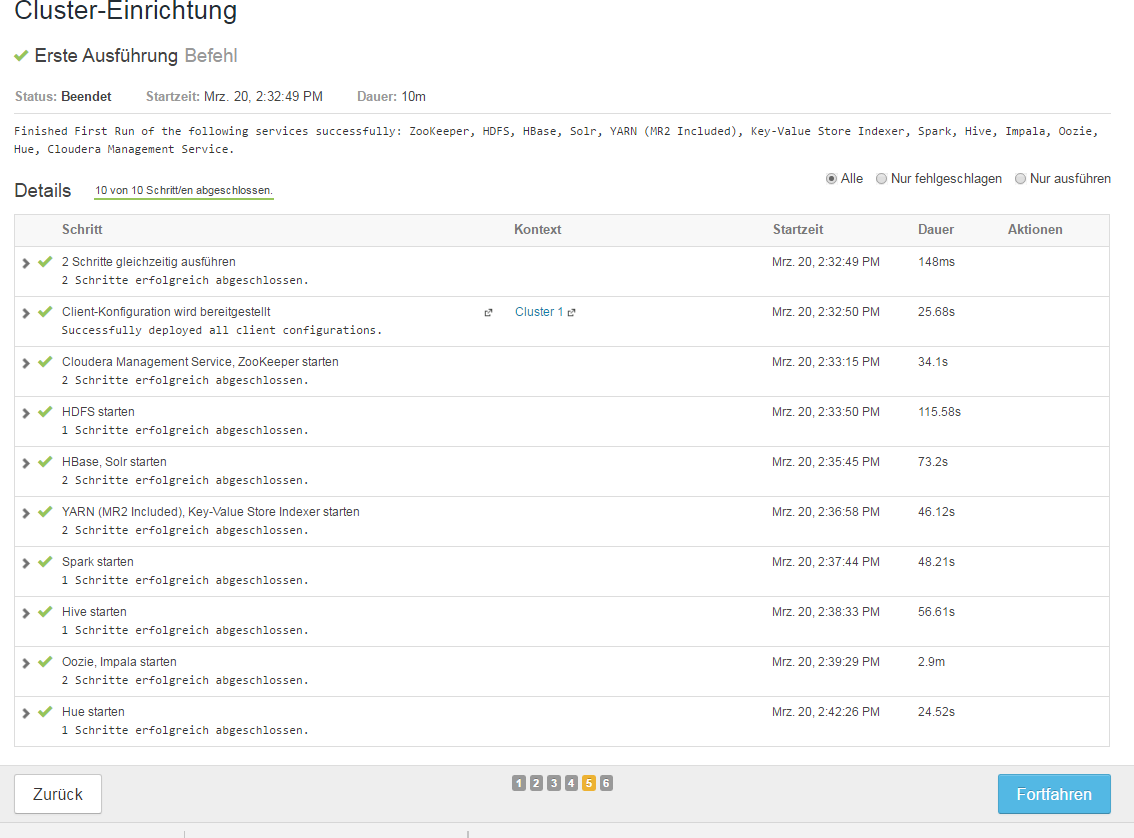
Step 5 „“ Cluster-Konfigurationsausführung
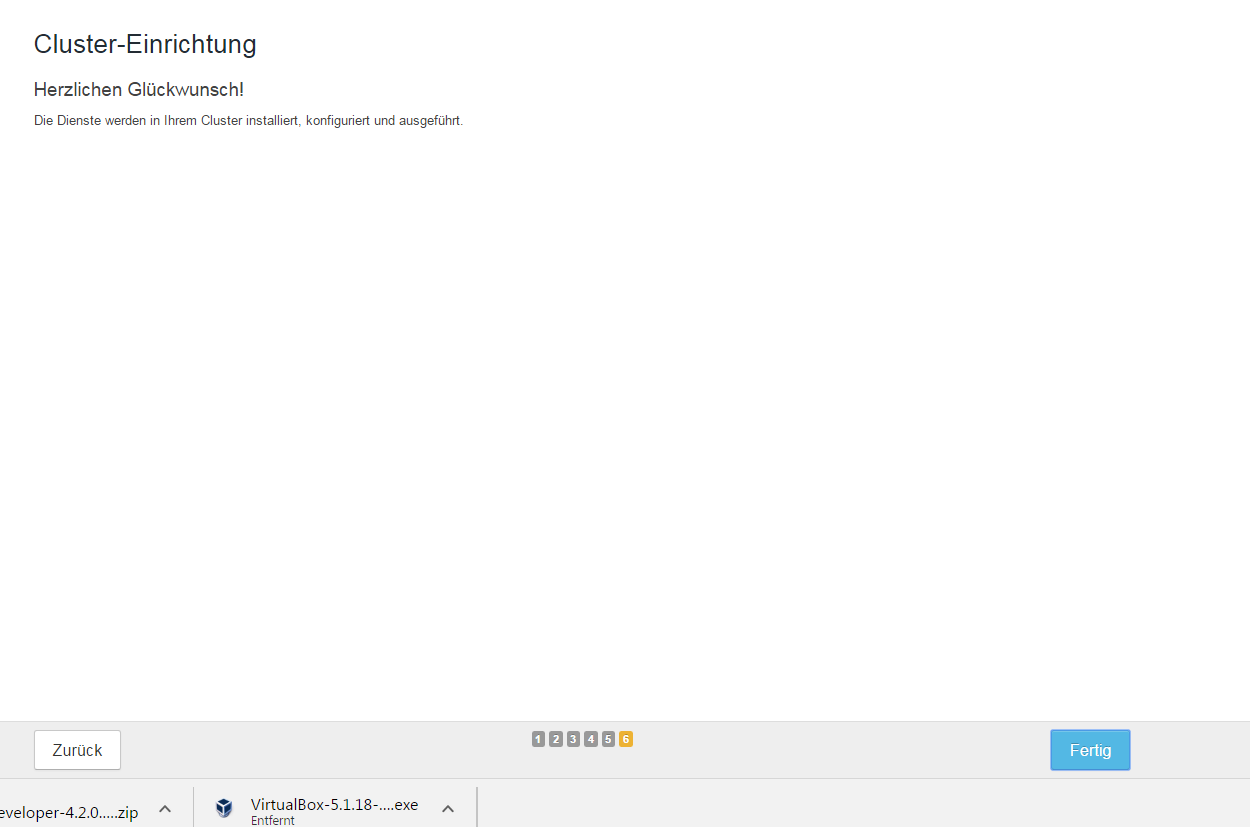
Step 6 – Cloudera wurde erfolgreich installiert
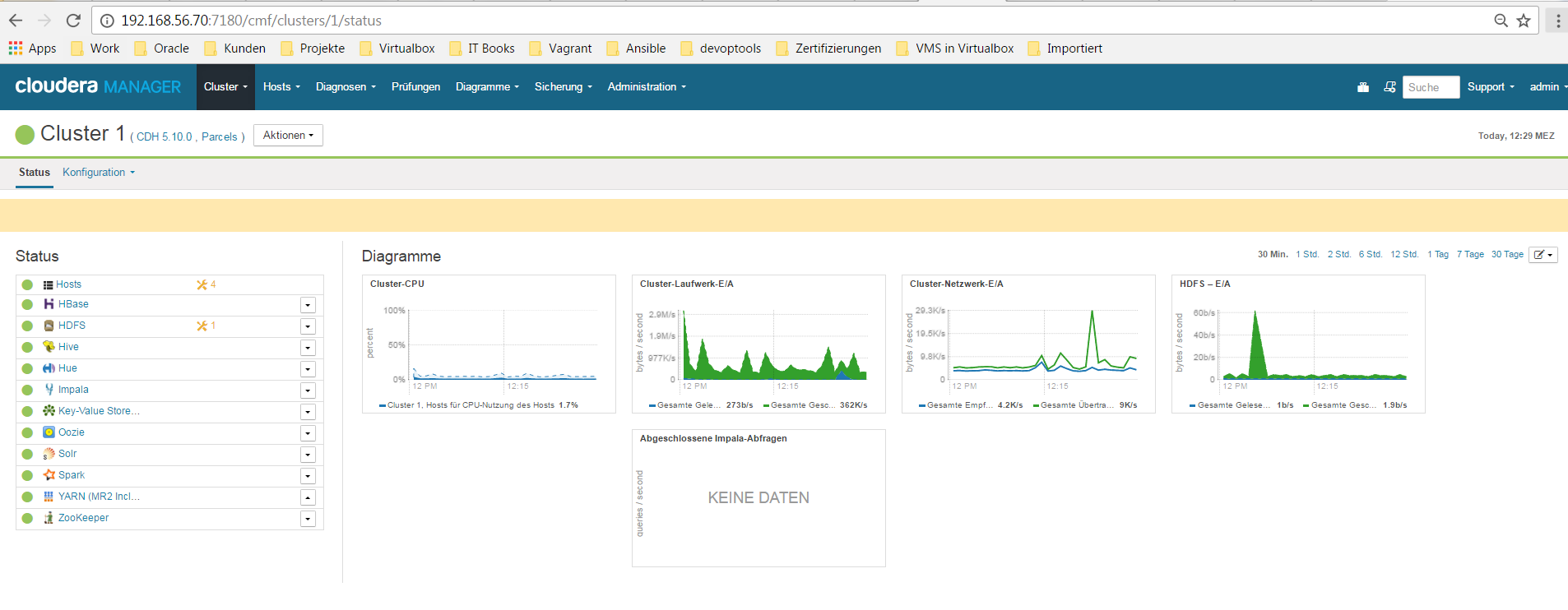
Step 7 – Übersicht der Cloudera Standardseite
Links für Oracle DBAs
- https://www.cloudera.com/documentation/enterprise/release-notes/topics/rn_consolidated_pcm.html
- http://www.opitz-consulting.com/fileadmin/user_upload/Collaterals/Artikel/red-stack-magazin-2016-05_Warum-Ansible-fuer-DevOps-eine-gute-Wahl-ist_Simon-Hahn_sicher.pdf
- https://blog.codecentric.de/2013/08/einfuhrung-in-hadoop-die-wichtigsten-komponenten-von-hadoop-teil-3-von-5/
Kontakt:
Simon Hahn
simon.hahn@opitz-consulting.com



