
Wollten Sie nicht immer schon mal wissen, was im Hintergrund einer Suchmaschine abläuft. Warum sind Search Engines so schnell? Wie lautet der Such-Algorithmus von Google?
Vielleicht können wir wenigstens eine dieser beiden Fragen klären. Google hütet sein Geheimnis gut, aber wer z. B. auch alternative Suchmaschinen wie DuckDuckGo kennt, der kann hier einmal hinter die Kulissen schauen. Denn DuckDuckGo funktioniert mit der Suchmaschinen-API Lucene.
Apache Lucene ist eine hochperformante Suchmaschinen-Bibliothek, die komplett in Java geschrieben ist. Wer direkt in die Tiefen der API eintauchen will, kann sich das Projekt von der Homepage runterladen und in den Quellcode reinschnuppern: Apache Lucene.
Wer aber nur ein grobes Verständnis über die Technologie dahinter erhalten möchte, kann sich den Einstieg auch mit diesem Artikel erleichtern:
Abgrenzung zu Solr und Elastic Search
Bekannte Suchmaschinen im Bereich Big Data oder Software Engineering sind Elastic Search und Solr. Wie passt hier Lucene rein? Nun, Lucene ist einfach formuliert die Basis für das, was unter der Haube passiert. Sowohl Elastic Search als auch Solr bauen auf Lucene auf und bieten dem Anwender einen einfachen Zugang zu einer Bibliothek, in Form von Webschnittstellen und fertigen Implementierungen verschiedener Anwendungsfälle.
Lucene wird für das Erstellen und Verwalten des Such-Indexes verwendet, der erst einmal nicht mehr ist als ein Dokumentenspeicher. Für eine erfolgreiche Volltextsuche braucht es aber doch noch etwas mehr. Schauen wir uns dazu einmal die grundlegenden Probleme bei einer Volltextsuche anhand von relationalen Datenbanken an:
Was ist ein Index?
Jeder hat vermutlich schon einmal den Satz gehört: „Die Datenbank ist etwas langsam, wir sollten Indizes verwenden“. Was steckt denn eigentlich hinter diesen Indizes?
Die Antwort ist einfach: Sie machen die Suche auf der Datenbank schneller. Interessant ist aber das Warum.
Werfen wir einen Blick in eine ganz normale Datenbanktabelle einer relationalen Datenbank wie der Oracle DB:
| ID | SURNAME | NAME | ADDRESS | TEL_NUMBER |
|---|---|---|---|---|
| 1 | Smith | John | Groove Street | 5551 |
| 2 | Gardner | Hellen | Any Town | 5552 |
| 3 | Lambert | Zachariah | First Street | 5553 |
Hier sehen wir erst einmal nichts Besonderes. Wir führen ein klassisches Select-Statement aus: SELECT * FROM TABLE WHERE NAME=’John‘. Was jetzt intern passiert, ist, dass die Datenbank die Spalte NAME durchsucht und uns alle Treffer in einem Result Set zurückgibt. Da die Datenbank selbst aber nicht weiß, wie viele Johns es in der Tabelle gibt, muss sie wohl oder übel alle Einträge überprüfen. Denn selbst wenn sie, wie in unserem Fall, direkt im ersten Eintrag schon einen Treffer hat, gibt es keine Garantie, dass es nicht weiter unten noch einen John gibt. Versteht sich von selbst, dass dieses Vorgehen nicht besonders performant sein kann. Vor allem dann nicht, wenn wir 1.000.000 Einträge durchsuchen müssten. Wir legen nun einen Index über die Spalte NAME, was zur Folge hat, dass die Datenbank eine zweite Tabelle anlegt:
| NAME | RECORD_POINTER |
|---|---|
| Hellen | 0 … 0xffffffff |
| John | 0 … 0xffffffff |
| John | 0 … 0xffffffff |
| Zachariah | 0 … 0xffffffff |
In dieser Tabelle sind die Einträge anhand des Namens sortiert. Die zweite Spalte RECORD_POINTER ist ein Pointer auf den Eintrag in der Haupttabelle. Wenn wir jetzt wieder nach dem Namen John suchen, durchsucht die Datenbank diese Tabelle, findet den Eintrag John, fügt den Eintrag in das Result Set (über den Pointer kann der echte Eintrag in der Haupttabelle referenziert werden) und schaut in der nächsten Reihe nach. Bei einem weiteren Treffer kommt auch dieser Eintrag in das Result Set, bis es keine weiteren Treffer mehr gibt. Das passiert, wenn der nächste Eintrag Zachariah lautet. Diesmal steht aber fest, dass es keine weiteren Johns mehr in der Tabelle gibt und es muss nicht weiter gesucht werden.
Der Vollständigkeit halber sollte noch erwähnt werden, dass die Einträge in einer Tabelle standardmäßig anhand des Primary Keys sortiert werden und dieser somit automatisch einen Index hat.
Für alle weiteren Indizes wird eine neue kleine Tabelle angelegt. Man kann sich natürlich ausmalen, wie sinnvoll das Ganze für eine Volltextsuche ist, nämlich gar nicht. Wenn man in einem Feld nun nicht einfach einen Namen, sondern ein ganzes Textdokument ablegt und möchte dann herausfinden ob Schlagwort „X“ darin vorkommt, dann helfen die Indizes der Datenbank nicht weiter. Ihr bleibt dann nichts anderes übrig, als einen Full Table Scan durchzuführen.
Was macht Lucene anders?
Lucene ist eine NoSQL-Datenbank bzw. ein Dokumentenspeicher. Es nutzt keine relationalen Tabellen, aber trotzdem existiert auch in Lucene ein Index, der einer Datenbanktabelle recht nah kommt. In diesem Index werden aber nicht ganze Texte gespeichert mit dem Verweis zu welchem Dokument sie gehören, sondern sogenannte Tokens. Ein Token kann ein einzelnes Wort sein, eine E-Mail-Adresse oder eine Telefonnummer. Im Prinzip besteht ein Text aus mehreren Tokens. Damit man einen größeren Text effizient durchsuchen kann, muss er vorher in Tokens zerlegt werden. Bei Lucene heißt dieser Prozess Analyze. Folgendes Schaubild soll den Prozess verdeutlichen:

Hangeln wir uns einmal kurz durch die drei Schritte:
Tokenizer
Der Tokenizer zerlegt den Text in einzelne Wörter. In der Praxis gibt es natürlich verschiedene Implementierungen für den Tokenizer. Manche werden von Lucene mitgeliefert, man kann sie aber auch selbst implementieren. Solr und Elastic Search bieten selbst noch ein paar weitere Implementierungen an. Sollte man also nicht vorhaben das „nackte“ Lucene direkt zu verwenden, braucht man sich um diesen Schritt, in einfachen Anwendungsfällen, eigentlich keine großen Sorgen machen. Wichtig ist nur zu wissen, dass der Tokenizer den Text in kleine Einheiten zerlegt, die in der Regel ein Wort beinhalten.
Stemmer
Der Stemmer bringt Wörter in seine Grundform. Dass heißt aus Wörtern wie „ging“, „Hauses“, „Bäume“ wird „gehen“, „Haus“, „Baum“. Das ist wichtig, weil man bei einer Suche nach dem Wort „Baum“ vielleicht auch Treffer haben möchte in denen das Wort Bäume vorkommt.
Filter
Der Filter entfernt unbrauchbare Wörter wie Konjunktionen, Präpositionen, Artikel etc. Wer bei einer Suchmaschine einfach das Wort „und“ sucht, sollte sich sowieso nicht auf zutreffende Ergebnisse freuen, warum das ganze also speichern. Der Filter kann natürlich auch angepasst werden. Z.B. könnte es ja eventuell doch Sinn haben, bei einer Filmdatenbank das Wort „der“ nicht rauszufiltern, um Treffer wie „Der Fluch der Karibik“ trotzdem zu bekommen.
Wir veranschaulichen das ganze noch einmal:
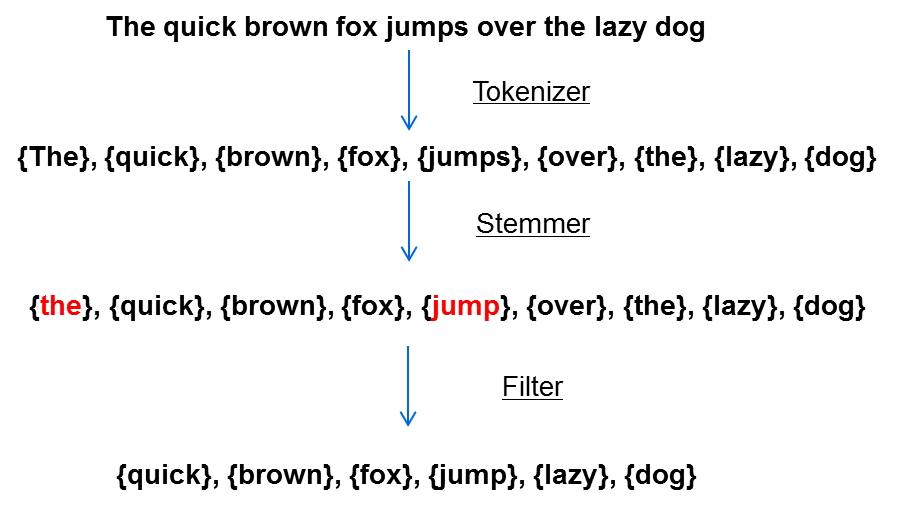
Der Text wurde nun in 6 Tokens zerlegt. Diese Tokens werden in Lucene in einem sogenannten Inverted Index gespeichert.
Inverted Index
Der Begriff Inverted Index sorgt manchmal für ein wenig Verwirrung, weil er oft ohne den Kontext dahinter verwendet wird. Grundsätzlich unterscheidet man im Kontext von Suchmaschinen einfach zwei Arten von Indizes. Einmal den Forwarded Index und zum anderen den Inverted Index. Der Forwarded Index ist eine Tabelle, in der alle Dokumente in der linken Spalte stehen und in der rechten Spalte die zugehörigen Tokens. Bei einem Inverted Index stehen in der linken Spalte die Tokens und in der rechten Spalte alle Dokumente, in denen diese Tokens vorkommen.
Eine einfache Darstellung haben wir hier:
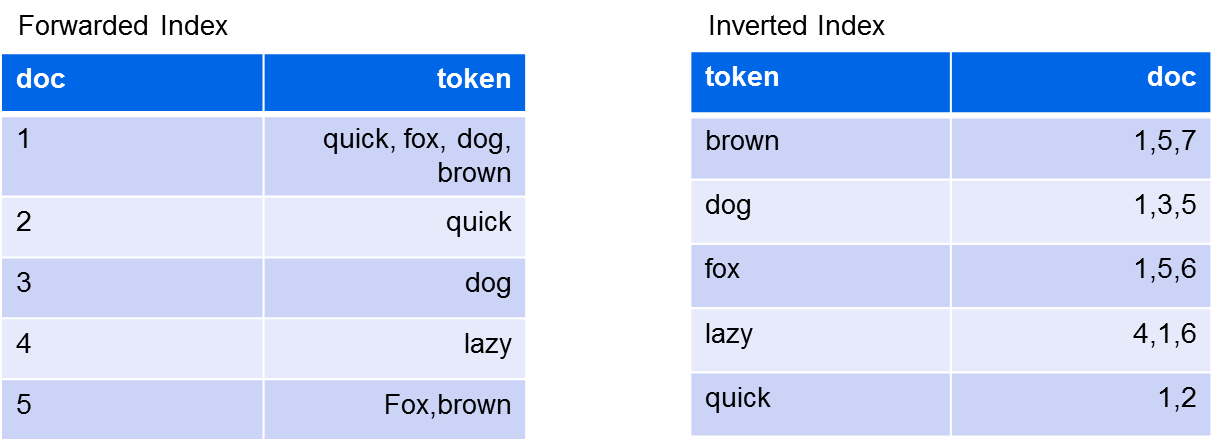
Der Vorteil entsteht dadurch, dass die Tokens eigentlich genau den Schlagworten in einer Suche entsprechen. Wenn wir jetzt nach dem Wort [brown] suchen, bekommen wir direkt alle Dokumente geliefert, die das Wort [brown] enthalten. Dadurch, dass der Index anhand der Tokens sortiert ist, muss nicht der gesamte Index durchsucht werden, was sich positiv auf die Performance auswirkt.
Halt, war Lucene nicht ein Dokumentenspeicher?
Ja, richtig. Wie am Anfang dieses Artikels erwähnt, handelt es sich bei dem Index auch um einen Dokumentenspeicher. Insgesamt besteht der Index aus mehreren Dateien, die direkt auf der Platte oder gar in einem Hadoop HDFS abgelegt werden. In diesen Dateien finden sich vielerlei Informationen, neben dem Inverted Index liegen hier aber auch die Dokumente. Ein Dokument in Lucene besteht aus mehreren Feldern, die wiederum aus Keys und Values bestehen. Zur Veranschaulichung hier ein Dokument im JSON Format:
{
„title“:“buying a house“,
„author“:“james gumberfield“,
„price“:“15$“
„text“:“some content“
…
}
Die Values in diesem Dokument werden beim Indexieren durch den Analyze-Prozess in Tokens zerlegt. Lucene merkt sich aber natürlich, zu welchem Feld diese Tokens gehören. Über den Inverted Index können diese dann nach potenziellen Treffern durchsucht werden und die Dokumente, die diese Tokens enthalten, werden als Ergebnis zurückgeliefert.
Suchen auf dem Lucene Index
Lucene bietet eine eigene Query-Struktur an, mit der man Suchanfragen ausführen kann. Die Suche erfolgt immer in den Werten der Felder, also z. B. im Feld Title wird nach dem Wort Buying gesucht. Die Query dazu würde so aussehen:
title:buying
Also Feldname gefolgt von einem : und anschließend der Suchterm buying. Gibt man keinen Feldname an, wird im Default-Feld gesucht. Das Default-Feld ist implementierungsabhängig.
Gehen wir in unserem Beispiel davon aus, dass wir die Felder title und text haben. Eine Suche mit einem einzelnen Wort haben wir bereits gesehen, doch wie sieht es mit einer Wortphrase aus?
Dabei muss man lediglich daran denken, die Phrase in Anführungszeichen zu setzen:
title:"buying a house"
Würde man folgende Suche ausführen …
title:buying a house
… würde Lucene nach dem Wort buying im Feld title suchen und anschließend nach den Wörtern a und house im Default-Feld. Die Suchen können mithilfe von Booleschen Operatoren verknüpft werden:
OR
Der OR Operator ist der Default-Wert. Das heißt, wenn kein Operator zwischen zwei Termen steht, dann wird automatisch OR genutzt:
Finde alle Dokumente mit "buying" im Feld title oder "house" im Default-Feld. title:buying OR house
AND
Finde alle Dokumente mit den Wörtern "buying" und "house" im Feld title. title:buying AND title:house
NOT
Finde alle Dokumente mit den Wörtern "new house" und nicht "new home" im Feld title. title:"new house" NOT title:"new home" Beim NOT Operator müssen mindestens zwei Suchterme eingegeben werden, sonst bleibt das Ergebnis leer.
+
Der „+“ Operator setzt den darauffolgenden Term auf required.
+house
Findet Dokumente die das Wort „house“ enthalten.
Der + Operator kann auch als Ü„quivalent zu AND verwendet werden, wenn man Folgendes schreibt:
+house +home
–
„-“ ist der Gegenpart von „+“ (welch eine Überraschung ;-)) und verbietet den folgenden Term in der Ergebnismenge:
+house -home
Das Ergebnis ist identisch mit dem NOT Operator, allerdings kann „-“ auch mit nur einem Suchterm verwendet werden.
Wildcards
Wildcards werden ebenfalls unterstützt mit den Operatoren „?“ und „*“. Der Unterschied ist, das „?“ für einzelne Zeichen und „*“ für mehrere gilt.
te?t
Findet z.B. test und text.
Wohn*
Findet wohnen, wohnung, wohnheim etc.
Fuzzy search
Lucene unterstützt auch eine unscharfe Suche mit dem „~“ Operator.
house~
… findet ähnliche Wörter wie „house“. Optional kann man über eine Zahl zwischen 0 und 1 einen Faktor bestimmen, der den Grad der Ü„hnlichkeit der Wörter angibt.
house~0.8
Standardmäßig wird der Faktor 0.5 verwendet.
Boosting
man kann einzelnen Suchtermen unterschiedliche Prioritäten einräumen. Der Operator „^“, gefolgt von einer positiven Zahl, beeinflusst die Reihenfolge der Ergebnisliste. Die Zahl kann auch kleiner als 1 sein (0.8 z.B.).
house^4 home
… findet alle Dokumente, die die Wörter „house“ und „home“ beinhalten. Die Treffer mit „house“ erhalten eine höhere Priorität und werden am Anfang der Ergebnismenge zurückgegeben.
Grouping
Mit Klammern kann man einzelne Suchkommandos zusammenfassen
(house OR home) AND new
Range search
Eine Bereichssuche kann mit den Operatoren „[ ]“ und „{ }“ erfolgen, wobei die Suche mit „[]“ die Randwerte mit einschließt, „{ }“ schließt diese hingegen aus.
date:[01012017 TO 01052017]
… findet alle Einträge zwischen und inklusive dem 01.01.2017 und dem 01.05.2017.
title:{A TO Z}
… findet alle Einträge zwischen A – Z wobei A und Z nicht in der Ergebnismenge enthalten sind.
Dies waren die wichtigsten Operatoren im Überblick. Die gesamte Doku dazu, befindet sich hier.
Fazit
Lucene ist ausgereift und robust. Man kann es ohne schlechtes Gewissen in der Produktion einsetzen. In der Praxis werden aber meist Elastic Search und Solr genutzt. Beide Technologien haben Lucene auf den nächsten Level gehoben. Viele Standardprobleme sind damit bereits gelöst und man muss sich nicht so viel mit der Implementierungen herumschlagen, sondern bekommt gleich das All-Around-Paket. In der Praxis kommt es natürlich oft vor, dass viel Feintuning erforderlich ist. Der Grund ist, dass die Suche immer anhand sehr spezifischer Anforderungen implementiert wird, trotzdem spart man sich viel Initialaufwand.
Wer mehr über wissen will, sollte sich einmal die jeweilige Homepage anschauen:
http://lucene.apache.org/solr/
Wer trotzdem mit Lucene starten möchte kann sich hier die Doku dazu anschauen. Derzeit ist die Version 6.5.0 aktuell.




{kind=link}