
Abstract
The WLS JMS Unit-of-Order feature (UOO) is well documented in various papers and blogs; it mainly enables numerous message producer to group messages into a single unit that is processed sequentially in the order the messages were created. Until message processing for a message is complete, the remaining unprocessed messages for that Unit-of-Order are blocked. This behavior makes the usage of UOO essential in cases that a specific processing order must be adhered to.
But what happens in a High Availability Environment using distributed queues, when a node breaks down? How can the processing order be guaranteed under these circumstances? This article is a practice report answering these questions.
Preparing the test
For our tests we are using an OSB cluster with two nodes and an Admin server in the Version 11.1.1.7; the WLS is in the version 10.3.6.
Configuring the JMS Server
Use the Admin Console (Admin Server) to perform the following steps:
- Define a data source (e.g. jdbc/jmsDS)
- Define a persistence store on each OSB Cluster-Node using the data source from Step1
e.g.:
– JDBCStore4JMS1 targets osb_server1 (migratable)
– JDBCStore4JMS2 targets osb_server2 (migratable)
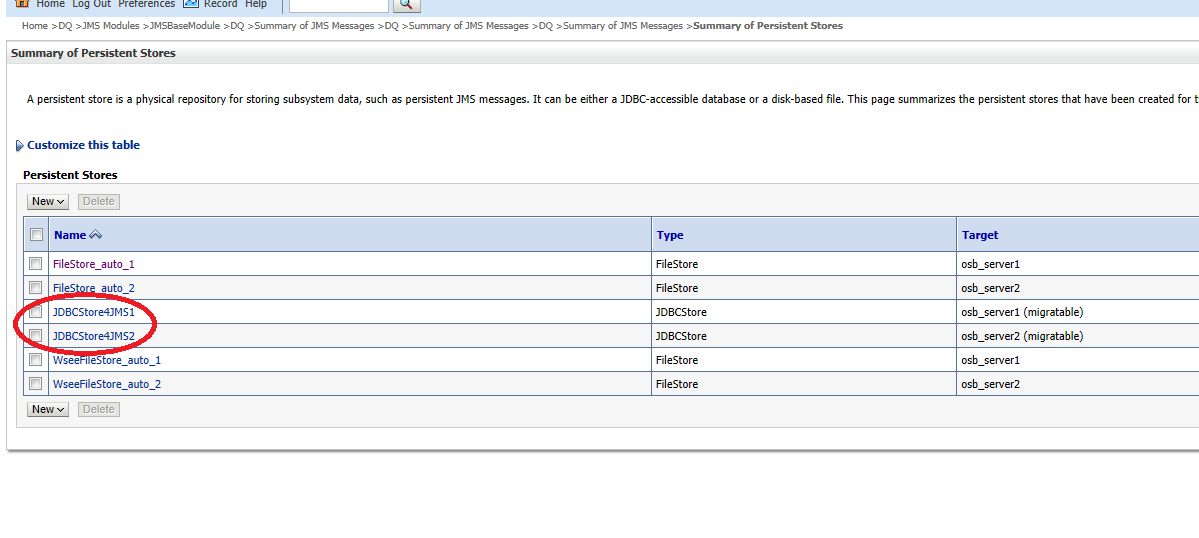
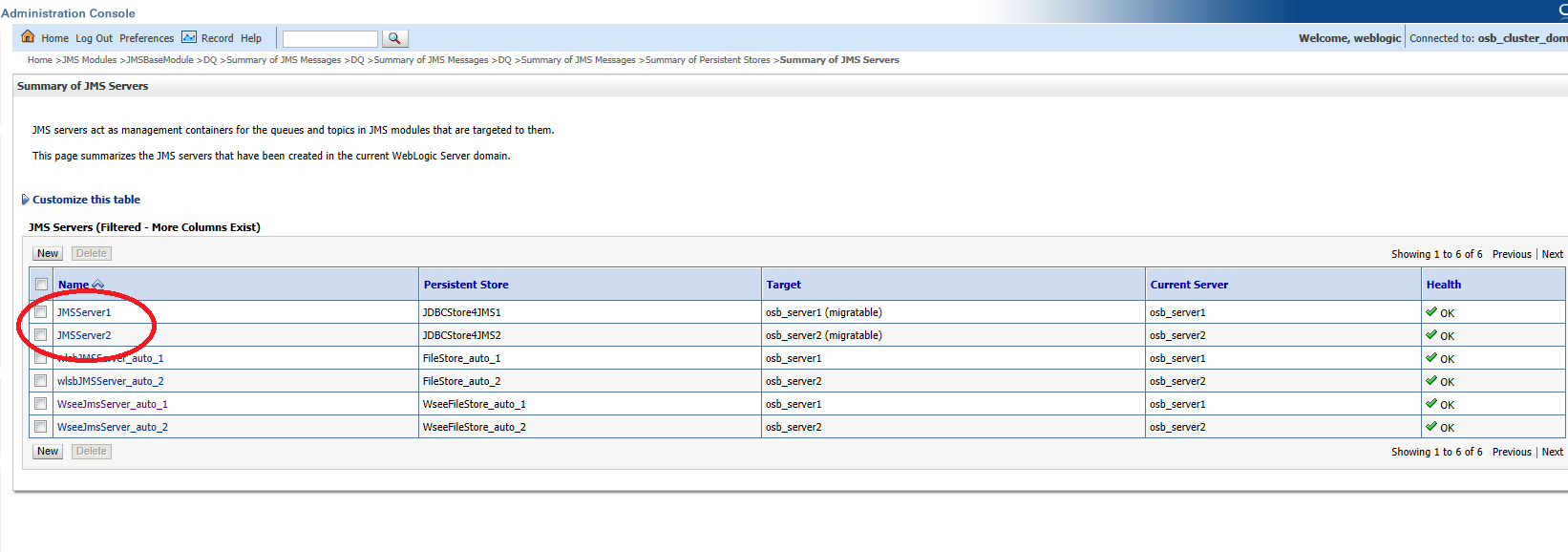
- Define a JMS Server on each OSB Cluster Node targeting a migratable target. Note: When a JMS server is targeted to a migratable target, you have to use a custom persistence store which must be configured and targeted to the same migratable target.
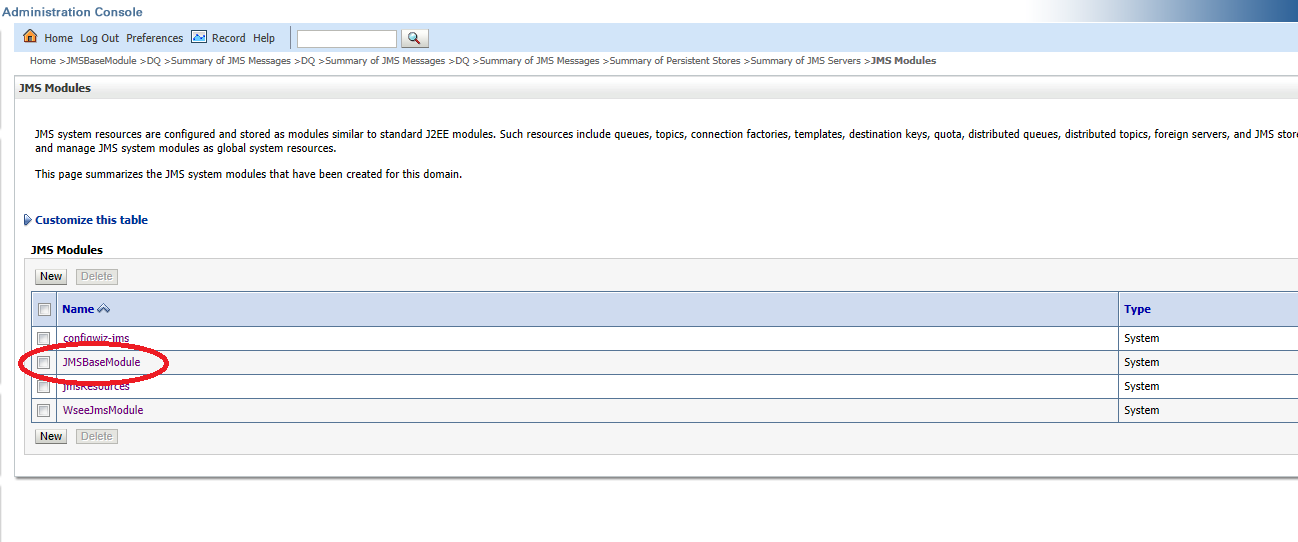
- Define a JMS Module targeting both JMS Servers; define an appropriate connection factory and a distributed queue.
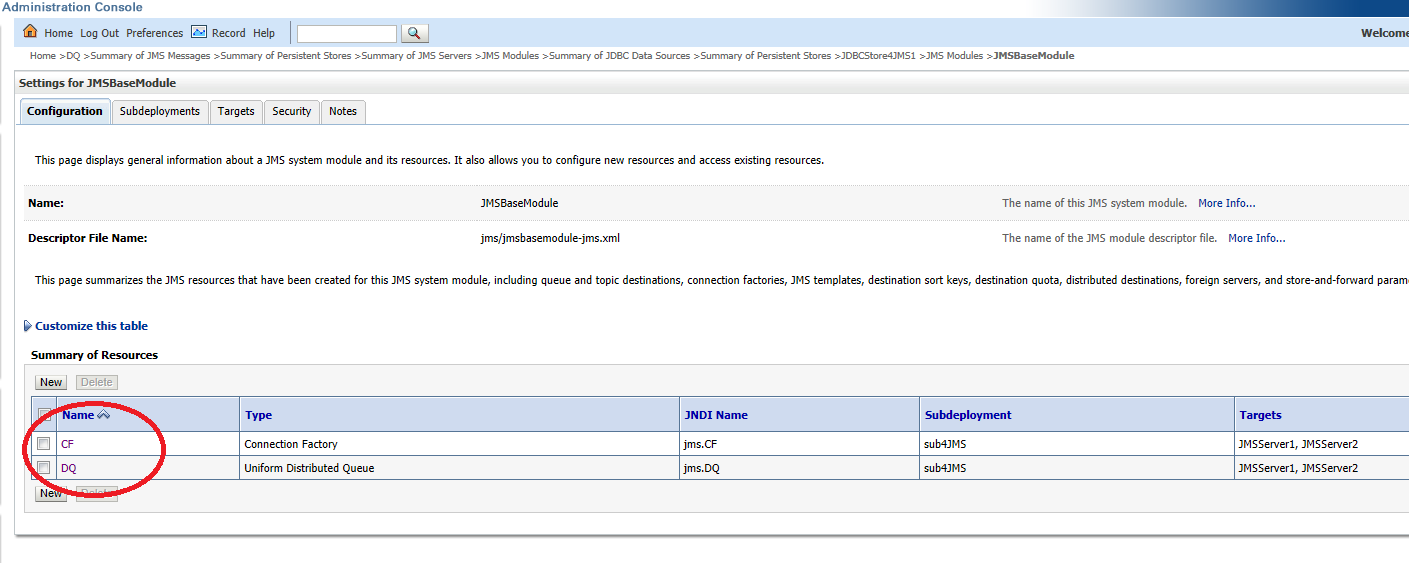
- Pointing at the distributed queue, you can now see both queues and the messages holding by them

Performing the test
A message producer sends 14 messages using UOO KEY1, KEY2, and KEY3 in the following way:
- 3 messages with UOO: KEY1
- 2 messages with UOO: KEY2
- 9 messages with UOO: KEY3
The following was observed:
- The messages were received by the queue and distributed to the configured persistence stores
- Messages with the same UOO were stored in the same persistence store
- After a cluster node was shut down, all new messages containing the same UOO as those processed by the JMS Server (and the persistence store) pinned to the disconnected node, have been rejected; all other messages continued to be enqueued (and dequeued)
- After the migration of the JMS Server (and its persistence store) which was pinned to the shutdown node, to another working node – which took approximately 10 sec.- all rejected messages were processed and the distributed queue regained fully functionality.
Conclusion
The processing order of messages can be guaranteed in a clustered Environment when using JMS Unit-Of-Order.
If a cluster node crashes the distributed queue is not able to receive messages of a certain UOO for approximately 10 sec. which might be for the most cases a sufficient small amount of time.


