

Dies ist der erste Beitrag einer zweiteiligen Reihe, die die Möglichkeiten von Amazon SageMaker evaluiert. Nachdem wir uns bereits mit dem Thema Reinforcement Learning anhand des AWS DeepRacers beschäftigten, haben wir nun den Amazon SageMaker untersucht. Dabei lag der Hauptfokus auf den folgenden Fragestellungen:
- Welche Funktionen bietet Amazon SageMaker
- Liefert automatisiertes maschinelles Lernen (AutoML) einen echten Mehrwert
- Welche Performance erreicht das AutoML des Amazon SageMakers, im Vergleich zu manuell entwickelten Machine Learning (ML) Modellen
Um diese Fragestellungen zu beantworten wurden zwei verschiedene Datensätze ausgewählt und jeweils ein manuelles ML Modell und ein automatisiertes ML Modell erstellt und verglichen.
Amazon SageMaker und Amazon SageMaker Autopilot
Amazon SageMaker ist ein Service von AWS, um den Prozess der Entwicklung eines ML Modells zu vereinfachen und so die Time to Market zu verkürzen. Der Autopilot ist der zugehörige AutoML Service im SageMaker. AutoML vereinfacht den Prozess der Anwendung von maschinellem Lernen auf Probleme der realen Welt. Dabei wird die gesamte Pipeline vom Rohdatensatz bis zum einsatzfähigen Modell automatisiert. Damit werden Teile des Preprocessing und das komplette Modellieren übernommen.
Der Amazon Autopilot bietet dabei zwei unterschiedlichen Modi an. Ein Modus erstellt lediglich die Python Scripte und Modellvorschläge, welche anschließend angepasst und manuell ausgeführt werden können. Der zweite Modus hingegen bietet eine graphische Oberfläche und führt das komplette Modellieren inkl. Training automatisch aus.
Verwendete Datensätze
Um SageMaker in seiner vollen Bandbreite zu evaluieren, entschieden wir uns dazu, mit zwei unterschiedlichen Datensätzen und Problemen die Technologie zu verproben.
- Beim ersten Datensatz handelt es sich um ein mehrdimensonales Klassifizierungs Problem (https://www.kaggle.com/datasnaek/mbti-type)
Dieser Datensatz enthält bis zu 50 Social Media Posts von einer Person und dem dazugehörigen MBTI Typ der Person - Beim zweiten Datensatz handelt es sich um ein Regressions Problem (https://www.kaggle.com/vikrishnan/boston-house-prices)
Dieser Datensatz enthält Informationen über die Preisentwicklung des Wohnungsmarktes in Boston, sowie Informationen über die jeweilige Immobilie
Im Folgenden beschreiben wir unsere Erfahrungen mit dem ersten Datensatz, die Erfahrungen mit dem zweiten Datensatz und ein Fazit folgen in einem zweiten Blogpost.
Test Case — MBTI Klassifizierung
Der Meyer-Briggs Type Indicator (MBTI) ist eine Klassifizierung der Persönlichkeit anhand von 16 Klassen. Dieser Test Case wurde dafür verwendet, um die Performance von SageMaker im Bereich der Multidimensionalen Klassifizierung zu bewerten. Dabei haben die ML Modelle englischsprachige Social Media Posts auf einen von 16 Persönlichkeitstypen zugeordnet.
Datensatz
Um ein Machine Learning Modell zu entwickeln werden sehr viele gelabelte Daten benötigt. Der Datensatz (https://www.kaggle.com/datasnaek/mbti-type) von Kaggel bietet hierfür die richtige Anzahl and gelabelten Daten. Dieser enthält von eine Vielzahl von Social Media Posts. Pro Person werden bis zu 50 Posts aufgeführt sowie deren MBTI Type.
Der MBTI Test ist ein Instrument, mit dem der Persönlichkeitstype erfasst werden kann. Er unterscheidet Typen entlang vier Dimensionen:
- I-E (Introversion – Extraversion)
- N-S (Intuition – Sensing)
- F-T (Feeling – Thinking)
- J-P (Judging – Perceiving)
Jede Person kann in jeder der vier Dimensionen je eine von zwei Ausprägungen haben. Der Persönlichkeitstyp ist dann die Zusammensetzung der verschiedenen Ausprägungen Daraus entstehen dann 24 = 16 verschiedene Persönlichkeitstypen. (INFJ, ISFJ, …)
Preprocessing
Um Text mit Hilfe von ML zu verarbeiten, muss dieser vorverarbeitet und codiert werden. Dadurch lässt sich eine deutlich bessere Performance bzw. Genauigkeit des späteren Modells erzielen. Für diesen Datensatz wurden zwei spezifische Anpassungen vorgenommen. Zum einen das Trennen des Datensatzes und zum anderen das verarbeiten/auflösen der Links.
Aufsplitten der Datensätze
Nach einer genaueren Untersuchung des Datensatzes stellte sich heraus, dass die Persönlichkeitsdimensionen jeweils für eine Person direkt kombiniert wurden. Dies lässt den intuitiven Ansatz zu, für jede der vier Dimensionen eine eigene binäre Klassifikation zu erstellen.
Verarbeiten von Links
Da es sich bei den Datensätzen um Social Media Posts handelt, enthalten diese vermehrt Links. Diese Links beinhalten zum Teil wichtige Informationen über den Post der jeweiligen Person. Deshalb wird der Inhalte der Links extrahiert und der Link mit diesen neu gewöhnen Daten ersetzt. Links die keinen Inhalt, wie bspw. YouTube-Links, besitzen werden durch den Namen des Dienstes ersetzt. Im Beispiel von YouTube bedeutet das, dass der YouTube Link durch das Wort YouTube ersetzt wurde. Links welche wichtigen Informationen, wie bspw. Bildnamen enthielten, wurden beibehalten. Eine Linkauflösung dieses Linkes http://wallpaperpassion.com/upload/23700/friendship-boy-and-girl-wallpaper.jpg“ würde friendship-boy-and-girl-wallpaper.jpg ergeben.
Vectorizer
Im nächsten Schritt muss der Datensatz analysiert und codiert werden. Hierfür wird, wie bei der Textverarbeitung üblich, ein Vectorizer verwendet. Mit dessen Hilfe wird eine Feature Extraction eines Textes, in unseren Fall der Posts, durchgeführt. Hierbei entstehen Kennzahlen/Features wie: Häufigkeit eines Wortes, Satzlänge und TF-IDF-Wert.
Das TF-IDF-Maß wird zur Beurteilung der Relevanz von Termen in Dokumenten eingesetzt. Diese Maßeinheit besteht aus der Kennzahl TF (term frequency) und IDF (inverse term frequency). Hierbei gibt TF die Häufigkeit einzelner Terme (Wörter) an und beschreibt wie häufig ein Term im Dokument bzw. Post vorkommt. Mit Hilfe dieser Kennzahl kann nun unser Modell trainiert werden. (https://de.wikipedia.org/wiki/Tf-idf-Ma%C3%9F)
Modelling
Um das Modell von AutoML zu evaluieren, entwickelten wir zwei weiter Modelle selber. Diese beiden Modelle werden im Folgendem kurz beschrieben.
Passive Aggressive Classifier (PAC)
Dieser Klassifizierungs-Algorithmus zeichnet sich durch die, wie schon im Titel angedeutet, Passive und Aggressive Klassifikation aus. Dies bedeutet, dass bei einer korrekten Klassifikation eines Training Samples das Modell unverändert bleibt, bei einer inkorrekten Klassifikation hingegen wird das Model so abgeändert, dass das Training Sample in der korrekten Klassifikation liegt.
Der PAC ist simpler Standard Algorithmus, welcher für viele Klassifizierungsprobleme eingesetzt wird und dafür für die ersten Evaluierungen gut geeignet ist.
Linear Support Vector Machine
Dieser Algorithmus ist ebenfalls ein Klassifizierungs-Algorithmus, welcher die zusätzliche Eigenschaft besitzt, dass die beste Hyperebene gefunden wird. Dies bedeutet intuitiv: die Daten werden derart klassifiziert, dass sie einen möglichst großen Abstand zu benachbarten Clustern besitzen.
Dieser Algorithmus ist einer der am häufigsten eingesetzten und meistens, am besten geeignet für Textklassifizierung. Also genau das Richtige für dieses Projekt.
Ergebnis AutoML
AutoML hat in den Testdurchläufen jeweils 250 verschiedene Modelle trainiert. Diese setzen sich aus einer von verschiedenen Datenvorverarbeitungsmethoden sowie dem parametrisierbaren Training zusammen. Wir haben den Code von dem besten Modell etwas genauer unter die Lupe genommen. AWS verwendet für das Preprocessing, ebenso, den TF-IDF-Vectorizer von SciKit-Learn „“ Nur mit anweichenden Parametern zu unseren Vectorizer. Für das Training und ML-Modell greift AWS auf den Boosted-Tree Algorithmus von XGBoost zurück. Hierbei werden mehrere schwächere Modelle zu einem kombiniert, welcher bessere Ergebnisse liefert. Dabei greift AWS auf die SciKit-Learn Library zurück.
Ergebnis „Hand-Coded“
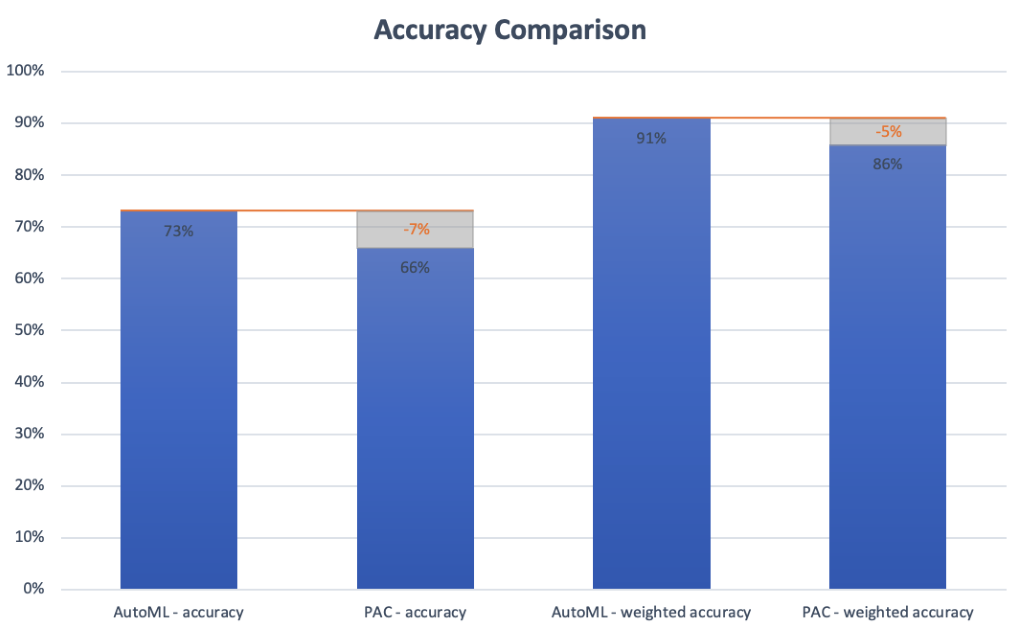
Als Output generierten wir drei trainierte Modelle. Die Accuracy des Passive Aggressive Classifier Modells und des Linear Support Vector Machine Modells lagen dicht zusammen bei ca. 66%. Das Modell der Linear Support Vector Machine erzielte lediglich eine Verbesserung von ca. 2%, welche mit etwas Finetunning und Preprocessing noch weiter gesteigert werden hätte können.
Fazit / Zusammenfassung
Zur genaueren Analyse der Modelle, berechneten wir eine gewichtete Genauigkeit. Diese betrachtet die Vorhersage für jede Dimension des Persönlichkeitstypen einzeln. Somit entsteht eine genauere Abstufung über die Güte der Vorhersage. Beispielsweise wird dadurch mit in Betracht gezogen, dass drei Dimensionen richtig vorhergesagt wurden und nur eine falsch. Dies ergibt somit eine Genauigkeit von 75%. Diese Berechnung ist valide da die einzelnen Persönlichkeitstypen nahezu unabhängig sind.
Das beste Modell des Autopiloten hatte eine Genauigkeit von 73% und einer gewichteten Genauigkeit von 91% und ist damit deutlich besser als unsere eigenen Modelle.
Ausblick
In unseren nächsten Blogartikel beschäftigen wir uns mit Regression, um eine Vorhersage der Entwicklung des Immobilienmarktes in Boston zu treffen.



{kind=link}
1 Kommentar
Bin schon gespannt auf den zweiten Artikel aus der Reihe ;).