

In dieser Blog-Serie möchte ich euch das Full Stack Framework Remix als eine vielversprechende Alternative vorstellen, insbesondere für die Entwicklung von Geschäftsanwendungen.
Darum geht’s in dieser ersten Folge:
- Wie hat sich die Entwicklung von Business Applications in den letzten Jahren verändert?
- Welche technischen Herausforderungen haben dazu geführt, dass wir heute dort stehen, wo wir stehen?
- Welche weiteren Technologien gibt es, und was ist das Besondere an Remix?
Viel Spaß beim Lesen!
Rückblick auf die Vergangenheit
Vor 10 bis 15 Jahren war es noch üblich, Geschäftsanwendungen mittels serverseitigem Rendering zu entwickeln. Frameworks wie PHP, Ruby on Rails, ASP.NET oder Java Server Faces dominierten diese Ära. Die Anwendungen wurden auf dem Server gerendert und als HTML an den Browser ausgeliefert.
JavaScript war damals nicht sehr populär, da Browser noch nicht so standardisiert und performant waren wie heute.
Allerdings hatten diese serverseitig gerenderten Anwendungen einen entscheidenden Nachteil gegenüber klassischen Desktop-Anwendungen, die sie ablösen sollten: Sie waren nicht so responsiv und interaktiv. Deshalb führte der ständige Austausch mit dem Server zu einer langsamen Benutzererfahrung.
Die Ära der Single Page Applications (SPA)
Mit der Einführung von AJAX und später Single Page Applications (SPA) änderte sich dies. Anwendungen wurden interaktiver und responsiver. SPAs kommunizieren über HTTP APIs, die Daten im JSON-Format austauschen, wodurch das Frontend im Browser gerendert und die Daten über APIs geladen werden. Dies führte zur Verbreitung des REST-Paradigmas.
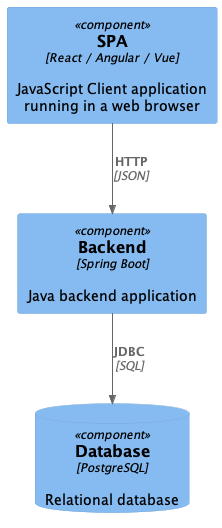
Herausforderungen und Komplexität von SPAs
Die Umstellung auf SPAs brachte jedoch einige Herausforderungen mit sich:
- Komplexität der Netzwerkkommunikation: Daten mussten häufig mehrfach gemappt werden, was fehleranfällig und zeitaufwendig war.
- Overfetching und Underfetching: REST-APIs lieferten oft entweder zu viele oder zu wenige Daten, was zu ineffizientem Datenmanagement führte.
- Fragmentierung der Daten: Durch die Einführung von Microservices wurden Daten auf verschiedene Services verteilt, was die Datenabfrage komplexer machte.
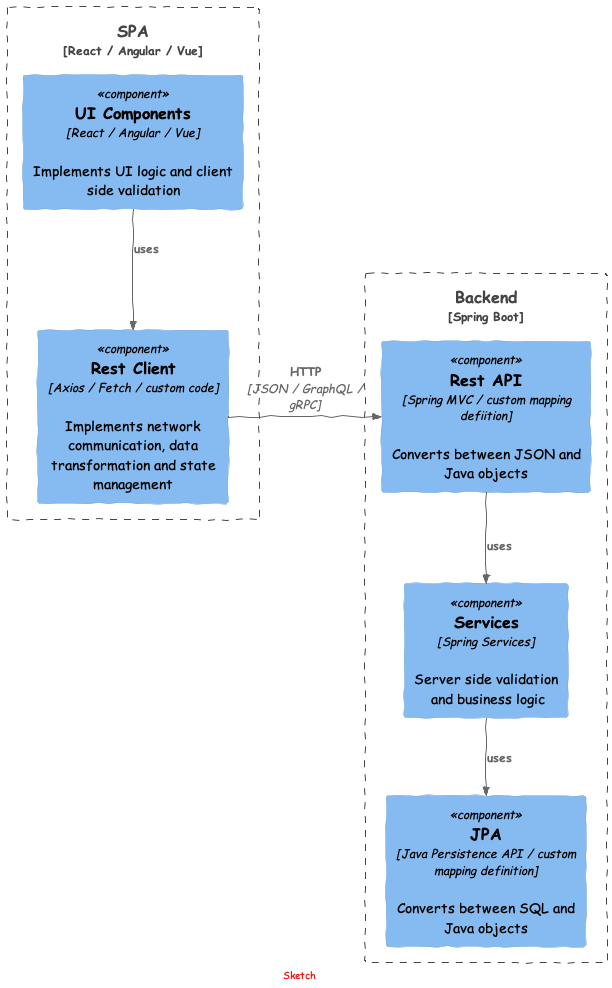 Abbildung 2. Whitebox SPA
Abbildung 2. Whitebox SPADie Komplexität lag auch darin begründet, dass viel „Boilerplate Code“ geschrieben wurde, um Daten zwischen Datenbank und UI auszutauschen. Die Architektur der Whitebox SPA ermöglichte z. B. diese beiden Funktionen:
- Definition von JPA Entites und Mapping zwischen SQL und Java Objekten
- Mapping zwischen Java Objekten und JSON
Wir haben hier ein Objektmodell, ein JSON Modell und Mappings drin, die gepflegt werden müssen. Dies ist nicht nur fehleranfällig, sondern auch zeitaufwändig.
Für bestimmte Use Cases konnten Ansätze wie Spring Data REST weiterhelfen. Diese automatisieren zum Teil das Mapping, zumindest Richtung REST. Daraus ergibt sich dann wieder ein Code-First-Ansatz für REST-Schnittstellen. Was in Ordnung sein kann, wenn es sich um private Schnittstellen handelt. Leider ist die Trennung zwischen „privaten“ und „öffentlichen“ Business-API-Schnittstellen nicht immer so klar:
Private Schnittstellen sind z. B. von einem Backend for Frontend (BFF) für ein bestimmtes UI optimiert mit speziellen Schnittstellen. Dies kann dazu führen, dass wir, obwohl wir eine „Business API“ ansteuern wollen, bei einer spezifischen BFF-Schnittstelle landen, die eigentlich privat sein sollte.
Ferner war hier zu beobachten, dass wir Validierungslogik häufig doppelt implementieren. Hier können generierende Ansätze helfen, die aus Java-Klassen (Annotationen) entsprechende Zod-Schemata generieren. Hierzu empfehle ich den Post: Validieren mit Zod: zwischen Frontend und Backend.
Lösungsansätze: BFF und GraphQL
So langsam wurden auch bei der Benutzung von REST Probleme sichtbar. Ein zentrales Problem war es, Daten bei einem REST-Architekturstil so zu laden, wie das Frontend sie für einen bestimmten Use Case benötigt. Dahinter verbarg sich das Phänomen des Overfetching und Underfetching, von dem oben schon einmal die Rede war. Es werden also zu viele oder zu wenige Daten vom Backend geladen. Mit diesen Folgen:
- Overfetching hat zur Folge, dass die Latenzzeit und die Datenmenge, die übertragen werden muss – gerade auch im mobilen Bereich – steigen.
- Underfetching hat zur Folge, dass mehrere Requests gemacht werden müssen, um die Daten zu laden, die für einen Use Case benötigt werden. Dies erhöht die Latenzzeit und die Komplexität der Anwendung. Gleichzeitig muss das Frontend wissen, welche Endpunkte es ansprechen muss, um die Daten zu laden. Mit der Einführung von Microservices, ist dies häufig nicht mehr so einfach, da die Daten auf verschiedene Services verteilt sind.
Um das Problem zu lösen, gibt es verschiedene Lösungen:
Zum einen wurde je Frontend ein spezielles Backend entwickelt, das die Daten so liefert, wie das Frontend sie benötigt. Diese Lösung ist als „Backend for Frontend“ bekannt. Eine andere Lösung ist die Einführung von GraphQL oder Falcor.
Diese Technologien erlauben dem Frontend, die Daten zu laden, die es benötigt. Hier hat sich klar GraphQL durchgesetzt. Der GraphQL Server fungiert dabei häufig als Gateway zu den Microservices. Das Frontend braucht nur noch den GraphQL Server ansprechen und bekommt die Daten, die es benötigt.
Wer ein Frontend auf mehrere Backend Microservices aufsetzen muss, ist immer noch mit dieser Technologie oder anderen Technologien, die das gleiche Problem lösen, gut beraten, wie etwa tRPC.
Allerdings wird diese Komplexität für viele Geschäftsanwendungen mit einer überschaubaren Nutzerbasis gar nicht benötigt. Man würde gerne die Vorteile von Single Page Applications nutzen, aber nicht die Komplexität, die damit einhergeht. Die Entwicklung solcher Anwendungen scheint damit zu teuer und zu komplex zu werden.
Lösungsansatz: Low Code
Vielleicht verstärkt u. a. diese Situation auch den Trend zu No-Code- und Low-Code- Plattformen. Denn diese versprechen die Entwicklung solcher Anwendungen drastisch zu vereinfachen und zu beschleunigen. Aus meiner Sicht allerdings leider auf Kosten von Flexibilität und Kontrolle über die Anwendungen. Denn hier kommt es zu einem starken Vendor Lock-in. Irgendwie erinnert mich das an die 90er Jahre und das Aufkommen von 4GL Sprachen. Der Wechsel zu einer anderen Technologie kann schwierig und kostspielig werden. Low-Code-Plattformen sind sehr „opinionated“ in der Art und Weise, wie Software entwickelt wird. Sie bieten vorgefertigte Bausteine und Prozesse. Die können die Entwicklung beschleunigen, bei spezifischen Anforderungen aber an Grenzen stoßen. Häufig bedeuten sie aus meiner Sicht eher einen Rückschritt in der Softwareentwicklung.
- Wenige unterstützen sauberes Unit Testing und die Integration in CI/CD Pipelines.
- Ebenfalls stellen wir immer wieder fest, dass die Entwicklungskosten gesenkt werden, aber die Gesamtkosten aufgrund von Lizenzkosten und Abo-Gebühren steigen. Gerade, wenn dann die Nutzeranzahl steigt, kann es schnell teuer werden.
- Aufgrund der hohen Abhängigkeit von den Plattformen, kann es auch schwierig werden, die Anwendung zu skalieren oder zu migrieren.
- Gleichzeitig benötigt man für die Entwicklung dieser Anwendungen auch noch Entwickler, die sich mit der Plattform auskennen. Die Plattformen sind also nicht so einfach zu bedienen, wie es auf den ersten Blick scheint.
Was aber tun, wenn wir Entwicklungsgeschwindigkeit und Entwicklungskosten senken wollen, aber gleichzeitig keine Kompromisse bei Standard-Technologien und einem relativ un-opinionated Ansatz eingehen wollen? Was gibt es für Alternativen?
Lösungsansatz: Fullstack Frameworks
Hier kommt Remix ins Spiel. Remix ist ein sogenanntes Fullstack Framework, das auf React und React Router aufsetzt. Next.js ist der Platzhirsch im React-Umfeld, aber auch für andere SPA Frameworks gibt es Fullstack Frameworks, wie Nuxt.js für Vue.js oder SvelteKit für Svelte. Nur für Angular ist das Angebot dünn. Es gibt mit Analog ein Fullstack Framework, das auf Angular aufsetzt, aber es ist noch nicht so ausgereift wie die anderen Frameworks.
Viele Fullstack Frameworks motivieren sich über den Aspekt der Search-Engine-Optimierung (SEO). Da HTML-Seiten auf dem Server gerendert werden, sind diese Anwendungen für Suchmaschinen unter Umständen besser geeignet. Dies ist sicherlich wichtig für Anwendungen, die öffentlich zugänglich sind und von Suchmaschinen indexiert werden sollen. Für interne Anwendungen ist der SEO-Aspekt weniger interessant.
Der generelle Aufbau sieht wie folgt aus
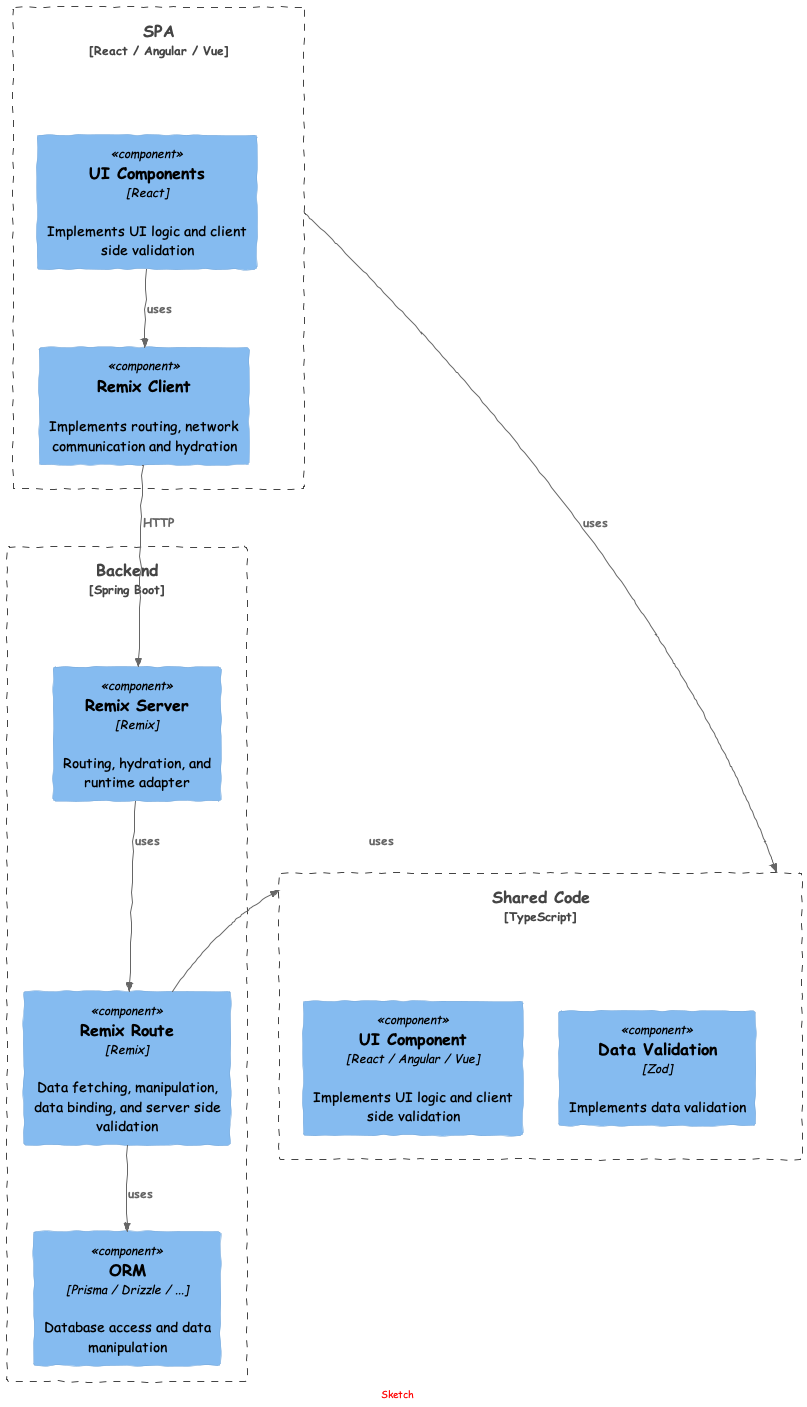
Abbildung 3. Whitebox Remix
Im Gegensatz zum ersten Ansatz mit dem Ökosystem-Bruch (JavaScript/Java), haben wir hier einen durchgängigen Ansatz. Wir brauchen keine unnötigen Mappings zu definieren, da wir direkt JSON aus der Datenbank bekommen. Außerdem definieren wir nur einmal die Validierungslogik für die Daten und können diese dann sowohl im Frontend als auch im Backend nutzen. Remix sorgt als Aufsatz auf „React Router“ dafür, dass folgende vier Dinge bereitgestellt werden:
- ein Compiler
- ein HTTP Handler (Runtime Server Adapter)
- ein Server Framework
- ein Browser Framework
Eine detaillerte Beschreibung findet sich in der Remix-Dokumentation. Einer der wesentlichen Unterschiede zu der Entwicklung mit einer REST API wie Spring MVC ist, dass Remix UI zentrisch ist. Während man bei der Implementierung einer REST API einen Controller implementiert, der mehrere URLs für ein einzelnes Modell bereitstellt, ist bei Remix immer eine Datei für das Laden, die Manipulation und das Layout zuständig. Dabei kann eine Route auf ein Segment einer URL mappen. Remix aggregiert Daten und Komponenten, um dann die komplette UI auszuliefern.
Mit diesem Ansatz erfüllt Remix einige der Anforderungen, die wir an eine Geschäftsanwendung haben:
- Serverseitiger Zugriff auf Datenbanken
- Authentifizierung und Autorisierung
- Testbarkeit
- Integration von Frontend und Backend, ohne dass wir uns um die Details kümmern müssen
Einiges davon wird schon durch das Node.js-Ökosystem abgedeckt. Aber gerade der letzte Punkt, also die Integration von Fronend und Backend, ist die Domäne der Fullstack Frameworks. Dies wird als Hydration und Dehydration bezeichnet.
React-Ökosystem für Geschäftsanwendungen
Für Geschäftsanwendungen ebenfalls häufig wichtig sind aus meiner Sicht zwei Dinge:
- Mächtige Tabellen
- Formulare und Validierung
Beides wird von Remix nicht bereitgestellt.
Für Tabellen setzen wir auf Mantine React Tables bzw. Material React Tables. Diese Komponenten setzen wiederum auf der (Headless) Tanstack Table auf. Neben der kommerziellen AG-Grid-Komponente ist das sicherlich eine der mächtigsten Tabellenkomponenten im React-Umfeld.
Für Formulare und Validierung setzen wir auf remix-hook-form, eine kleine Erweiterung von react-hook-form.
Stellt sich aber immer noch die Frage, warum wir Remix statt Next.js einsetzen. Denn war Next.js nicht der Platzhirsch im React Umfeld? Antworten findet ihr z. B. auf Prisimic.io. Dort gibt es einen Blogpost, der die beiden Frameworks vergleicht. Oer ihr lest einfach hier weiter:
Remix versus Next.js
Vor allem diese vier Argumente sprechen für die Wahl von Remix als Technologie statt Next.js:
- Remix setzt auf React Router auf (d. h. wir können Wissen wiederverwenden, etwa auch für klassische React-Projekte)
- Remix kann als Web Standard genutzt werden (Flexiblität für unterschiedliche Einsatzszenarien)
- Remix hat keine („unnötigen“) Extra-Features
- Bei Remix findet automatische State Synchronisation zwischen Server und UI statt, wenn wir Actions für die Manipulation von Daten verwenden
Insgesamt bietet Remix also genau das, was wir brauchen, um eine Fullstack-React-Anwendung zu bauen, und das ohne weiteren Overhead. Das hat den Vorteil, dass die Lernkurve relativ flach bleibt und man schnell produktiv werden kann.
Wobei der Punkt „unnötigte“ Extra Features natürlich immer eine Frage des Standpunkts ist, schon klar!
Aber einiges, was Next.JS anbietet, wie Static Site Generate oder Incremental Static Regeneration, ist für Geschäftsanwendungen tatsächlich weniger wichtig. Denn hier ist es eher fragwürdig, Daten zu cachen, die ein Nutzer ändern kann. HTTP Caching ist eher etwas für öffentliche Daten, die durch Back-Office Prozesse aktualisiert werden. Da bin ich ganz beim Standpunkt von Ryan Florence, einem der Köpfe hinter Remix. Von Florence kann ich auch diese Quelle empfehlen: CDN Caching, SSG, and SSR. Was er sagt, ist nicht nur relevant für CDN Caching, sondern für jede Art von Reverse Proxy vor dem eigentlichen Server. Das heißt, auch wenn wir etwa einen Caddy Server oder einen Nginx Server vor unserem Node.js Server haben.
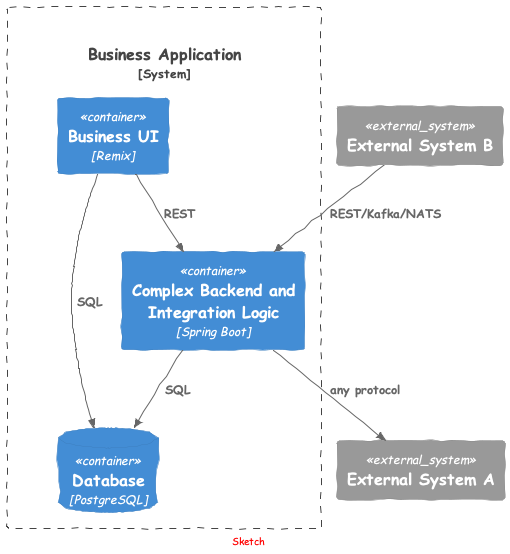
Bisher haben wir eine reine React-Fullstack-Anwendung gesehen. Was wir aber häufig antreffen, ist eine Aufteilung: Für alle UI relevanten Aspekte wird Remix verwendet, für die Integration mit Fremdsystemen und komplexe Business-Logik ein Java Backend. Die Integration mit Umsystemen sollte ja möglichst asynchron erfolgen, gegebenenfalls werden diese gecacht. Die Beantwortung einer UI-Integration erfolgt dann möglichst innerhalb des eigenen Systems.
Daher wird Remix bei etwas komplexeren Anforderungen nicht alleine genutzt, sondern in Kombination mit einem Java Backend.
Das wäre es für diesen Post. Doch es geht weiter:
In der nächsten Folge könnt ihr erleben, wie sich das Framework im Alltag anfühlt, wenn wir damit entwickeln und einen einfachen CRUD Use Case umsetzen: Remix: Data Routes und Data Loading
Alle Teile dieser Blogserie:
Teil 1: Remix – eine Alternative für Geschäftsanwendungen
Teil 2: Remix – Routes und Data Loading
Teil 3: Remix – Formulare, Validierung und Datenänderungen


