

Im alltäglichen Leben nutzen wir Sprachassistenzsysteme wie Siri oder Alexa, Onlineshops geben uns personalisierte Empfehlungen, Smartphones erkennen unser Gesicht, können es sogar verändern. Und mittlerweile schreibt ChatGPT für uns professionelle Bewerbungen oder erklärt uns die chinesische Kulturrevolution im Rapstil von Eminem. Alles auf der Basis intelligenter Systeme. Was in den 1950er Jahren als Idee auf dem Papier begann und lange Zeit für unmöglich gehalten wurde, hat längst Einzug in unseren Alltag gehalten. Künstliche Intelligenz und der Weg zu dieser: Machine Learning. Beide sind aus heutigen IT-Systemen nicht mehr wegzudenken.
Der Praxis Gap
Bei neuen Technologien, die Machine Learning einsetzen, werden zumeist Durchbrüche in Algorithmen und ML-Modellen gepriesen. Der große Erfolg und die schier endlos scheinenden Anwendungsmöglichkeiten machen den Einsatz von KI und Machine Learning für viele Firmen interessant. Beim Versuch für das eigene Problem eine KI-Lösung zum Einsatz zu bringen, kommt es aber oft zu ernüchternden Ergebnissen: Eine Studie von Dimensional Research aus dem Jahr 2021 ergab, dass fast die Hälfte (47 %) der befragten Unternehmen Schwierigkeiten bei der Umsetzung von ML-Projekten hatten.
Woran liegt das? Bei den Erfolgsgeschichten von KI wird meist ein gewaltiger Faktor außer Acht gelassen, nämlich die Praktiken, die dazu führen, dass die Daten verfügbar, frei von Bias und repräsentativ sind. Dazu gehört beispielsweise auch, dass das Modell mit möglichst wenig Aufwand und Redundanzen trainiert wurde und die Integration in die Betriebssoftware alle Besonderheiten des Anwendungsgebietes berücksichtigt oder ein Monitoring, das die Qualität der Lösung dauerhaft gewährleistet. Hier könnten wir immer noch Hilfe gebrauchen, oder eine Anleitung.
Diese kommt in Form des Frameworks Machine Learning Operations, kurz: MLOps.
Dieser Artikel soll eine kleine Blogreihe zum Thema MLOps einleiten. Was führt ML-Projekte zum Erfolg? Wir wollen uns ansehen, wie es andere machen und was erfolgreiche ML-Projekte auszeichnet.
In diesem ersten Teil sehen wir uns zwei Beispiele an, die zeigen, wie man es eher nicht machen sollte. Denn tatsächlich gibt es viele Fallen, in die wir tappen können, wenn wir ein ML-Modell trainieren. Diese Negativ-Beispiele zeigen, wo genau MLOps ansetzt und sollen dir helfen, das Konzept hinter MLOps besser zu verstehen.
Was ist eigentlich MLOps?
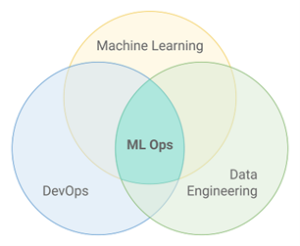
Stark vereinfacht könnten wir sagen: Machine Learning Operations, kurz: MLOps bedient sich des DevOps-Ansatzes, der aus der Softwareentwicklung bekannt ist, und überträgt ihn auf Machine Learning. Mit MLOps sollen sich also Machine-Learning-Modelle effizienter entwickeln, deployen, verwalten und monitoren lassen. Data-Science-Prozesse werden dabei in enger Zusammenarbeit mit Fachleuten aus dem Data Engineering, dem Development und dem IT-Betrieb auf die Strecke gebracht. Mit dem Ziel, Künstliche Intelligenz schneller und geschäftlich erfolgreicher nutzen zu können.
Denn Machine Learning ist in der Praxis mehr als die Entwicklung eines Modells mit geringer Fehlerquote. Es hat sich herausgestellt, dass der größte Teil der Arbeit im „Umland“ liegt. Also bei den Daten, der Softwareintegration, der IT-Infrastruktur und beim konstanten Monitoring.
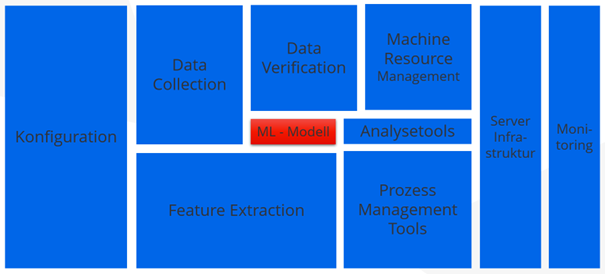
Machine-Learning-Modelle sind für sich allein genommen höchst akademisch und längst nicht so praxisbezogen wie die Softwareentwicklung. Um ein gut funktionierendes Modell zu trainieren, mag es reichen, ein paar Machine-Learning-Fachkräfte einzustellen. Wollen wir das Modell aber in einer Produktivumgebung langfristig und zukunftssicher einsetzen, gibt es einiges mehr zu beachten und viele Fallen zu vermeiden.
Ähnlich wie sich in der klassischen Softwareentwicklung DevOps als Sammlung produktiver Praktiken entwickelt hat, trägt MLOps dazu bei,
- den Umfang und die Anforderungen eines Problems an ein Machine-Lerning-Modell zu erfassen und die Ressourcen frühzeitig angemessen zu skalieren,
- die Daten, sowie deren Vorverarbeitung so anzupassen, dass das Modell effizient und zielgerichtet auf das Problem lernen kann,
- den Aufwand und Redundanzen bei der Entwicklung, Bereitstellung und Wartung von Machine-Learning-Modellen gering zu halten,
- wiederzuverwenden was wiederverwendet werden kann,
- zielführende, robuste Designentscheidungen zu treffen
- und auf möglichst alle Eventualitäten und Sicherheitsrisiken vorbereitet zu sein.
Aber wie sieht das in der Praxis aus? Wo und wie kann MLOps helfen, die erwähnten Fallen zu vermeiden? An zwei Negativbeispielen möchte ich das zeigen.
Beispiel A: Die zu optimistische Diagnose: Daten können trügerisch sein
2017 wurde das Modell CheXNet auf ca. 112.000 Röntgenaufnahmen des Brustkorbs von mehr als 30.000 Patienten trainiert, um verschiedene Krankheiten oder Befunde zu diagnostizieren. Das resultierende Modell arbeitete zuverlässig mit einer Trefferquote von 99 % auf den Testdaten.
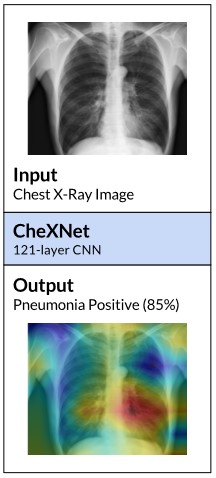
Da die Ergebnisse zufriedenstellend waren, wurde das System testweise auf echten Daten angewendet. Hierbei kam heraus, dass es einen bestimmten Befund gab, den das System nur schlecht bis gar nicht erkannte: Im Falle einer Hernie war die Trefferquote deutlich geringer als bei allen anderen Befunden. Wäre es nicht um einen Test gegangen, hätte dies schlimme Folgen haben können. Was war geschehen?
Der Trugschluss
Bei genauerem Hinsehen stellte sich heraus, dass der betroffen Befund sehr selten war und dass es in den Trainings- und Testdaten nur ca. 100 Beispiele für eine Hernie gab. Im Vergleich dazu gab es für die meisten anderen Befunde rund 10.000 Beispiele. Der Befund spielte in den Testdaten also eine derart geringe Rolle, dass die geforderte Trefferquote selbst dann eingehalten werden konnte, wenn das System sie einfach überging. Das Modell hätte eine Hernie also in 100 % der Fälle ignorieren und trotzdem in den Tests zuverlässig erscheinen können.
Die Trainings- und Testdaten bildeten somit zwar die Tatsachen realistisch ab, da eine Hernie eine seltene Erkrankung ist, waren aber ungenügend aufbereitet, um ein Modell auf alle Krankheiten gleichermaßen zu trainieren. Die Folgen für betroffene Patienten hätten schwerwiegend sein können. Wir dürfen nie vergessen, dass Modelle nicht wie wir denken. Ihr einziges Ziel ist eine hohe Zuverlässigkeit auf den Trainings- und Testdaten zu erreichen. Denn die Güte dieser Daten entscheidet über die Entscheidungsqualität des Modells.
Dies ist nur ein Beispiel für viele andere mögliche Fallstricke, die in unseren Daten lauern können, noch bevor wir überhaupt Optimierungen am Modell vornehmen. So ist zum Beispiel häufig ist einfach unklar, welche Daten für die vorliegende Fragestellung benötigt werden und in welcher Gestalt sie gebraucht werden. Viele Daten enthalten zudem irrelevante Werte , die ein Training sehr verlangsamen können. Oder die Daten sind nicht angemessen vorverarbeitet. Oder sie sagen nicht das aus, was sie aussagen sollen und so weiter.
Was ist bei CheXNet schiefgelaufen?
Falle 1: Wenn das Vorgehen fehlerhaft ist …
Zunächst brauchen wir ein umfassendes Domänenwissen. Wir müssen wissen, auf welcher Grundlage wir arbeiten, um ein Modell effektiv zu trainieren.
Wäre beim Training von CheXNet nach MLOps-Prinzipien vorgegangen worden, dann hätte das Team die Daten auf die Repräsentation aller gesuchten Klassen überprüft. Dabei wäre den Verantwortlichen aufgefallen, dass eine Krankheit besonders unterrepräsentiert ist. Durch „Supersampling“ oder mithilfe von „künstlichen“ Daten hätten sie hier beispielsweise gegensteuern können. Ein solches Vorgehen wird auch „Data Augmentation“ genannt. MLOps beschäftigt sich aber auch mit Techniken wie „Data Validation“ oder „Feature Selection“. Das heißt, es wird geprüft, ob die vorliegenden Daten für unser Anliegen gültig sind und ob die Auswahl der Datensätzen für die unsere Problemstellung relevant ist.
Falle 2: Wenn es subjektiv wird …
Auch psychologische Aspekte können sich in Daten widerspiegeln: Daten, die von Menschen erzeugt werden, können immer Vorbehalte oder persönliche Einstellungen enthalten, die wir später mit bloßem Auge nicht mehr nachvollziehen können. Dies kann dramatische Auswirkungen auf die Entscheidungen haben, die ein KI-Systems für uns trifft. Beispielsweise wenn die Kreditwürdigkeit einer Person an ihrer Herkunft scheitert, weil die Trainingsdaten eine entsprechende Ungleichverteilung enthalten.
Falle 3: Wenn Infrastrukturen die Analyse schwer machen …
Ferner können Dateninfrastrukturen die Qualität unserer Daten beeinflussen. Immer wieder erleben wir, dass sich eine Person, die ein ML-Projekt bei uns in Auftrag gibt, sicher ist, alle nötigen Daten zu besitzen. „Es müsse nur noch ein Modell gebaut werden!“ Dann erleben wir, dass die Daten auf diversen Plattformen verteilt, durch unterschiedliche Formate schwer verknüpfbar, voller Redundanzen oder voll von Datensätzen mit wenig Aussagekraft sind. Aus diesem Chaos dann eine verwertbare Quelle zu machen – etwa mittels einer ETL-Strecke, einer Data Pipeline und eines Data Warehouses – kann ein komplett eigenes Team beschäftigen. Ist dies nicht eingeplant, scheitert das Projekt eventuell bereits an diesem Punkt.
Falle 4: Wenn Aufwand geschätzt werden muss …
Sehr häufig werden bei ML-Projekten Arbeitspakete nicht eingeplant oder deren Aufwand nicht richtig eingeschätzt, meist unterschätzt. Auch hier setzt MLOps an. MLOps bietet Tools und Vorgehensweisen an, die uns einen Überblick verschaffen über alles, was da ist und alles, was getan werden muss. Erst wenn wir diesen Überblick haben, sind wir in der Lage, Modelle und das Rahmenwerk sinnvoll zu skalieren und den Aufwand richtig einzuschätzen.
Außerdem gibt es heute zahlreiche Tools, die dabei helfen Aufwand beim Machine Learning zu sparen: So lassen sich Modelle wiederverwenden oder mit wenig Aufwand auf andere Zwecke „umtrainieren“. Auch Datenvorverarbeitungsstrecken, Trainingskonfigurationen und daraus resultierende Artefakte können versioniert und wiederverwendet werden.
Mit all diesen Mitteln hilft MLOps dabei, Modelle effektiv, schnell und mit dem geringstmöglichen Aufwand zu trainieren und auszuliefern.
Fazit
An diesem Beispiel erkennen wir, dass der Weg zu einem erfolgreichen ML-Projekt nicht nur über spezielle Fachkräfte und ein gut trainiertes Modell führt, sondern deutlich mehr Überlegungen und Designentscheidungen im Vornherein, sowie eine umfassende Sichtung und ggf. Anpassung der Daten und der Betriebsumgebung erfordert.
Beispiel B: À la mode – Auch KI hat ein Verfallsdatum
In diesem Beispiel verwendete eine Online-Modefirma ein Machine-Learning-Modell, um vorherzusagen, welche Kleidungsstücke eine bestimmte Person am wahrscheinlichsten kaufen wird. Dazu wurde das Modell auf Verkaufsdaten der letzten drei Jahre trainiert. Das Unternehmen integrierte das Modell erfolgreich in seine Website, um personalisierte Produktempfehlungen an seine Kundschaft zu liefern.
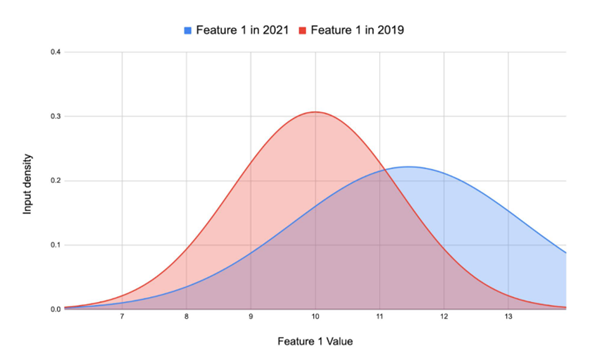
Ein Jahr später änderte das Unternehmen seine Modekollektion und brachte eine neue Linie von Kleidungsstücken auf den Markt. Diese neuen Produkte wurden von einer jüngeren Zielgruppe bevorzugt und wichen stark von den Produkten ab, auf denen das ursprüngliche Modell trainiert wurde. Da das Modell ausschließlich auf historische Verkaufsdaten basierte, in denen die neuen Produkte keine Rolle spielten, entstand eine Abweichung. Ein Data Drift, der verhinderte, dass das Modell die neuen Muster und Trends in den Daten erfassen konnte. In der Folge lieferte es schlechte Vorhersagen.
Fallen in den Daten
Falle 1: Data Drift
Der Data Drift, den wir in diesem Beispiel erlebt haben, bezieht sich auf Veränderungen in den Daten, die ein Machine-Learning-Modell verarbeiten soll. Veränderungen, die im Laufe der Zeit entstehen können. Diese Veränderungen können dazu führen, dass das Modell auf einmal nicht mehr in der in der Lage ist, genaue Vorhersagen zu treffen. Denn es kann die neuen Muster und Trends nicht in den Daten erfassen, die es kennt. In unserem Beispiel führte die Änderung der Mode zu einer Verschiebung in den Daten. Wenn wir ein Modell also als Funktion mit Eingabe- und Ausgabewert F(X) = Y betrachten, dann hat sich die Distribution unserer X-Werte so grundlegend geändert, dass die Y-Werte, die das Modell ausgibt für unseren Anwendungsbereich unbrauchbar sind.
Falle 2: Concept Drift
Ein anderes aber ebenso fatales Alterungsanzeichen unseres Modells wäre der sogenannte Concept Drift.
Ein Beispiel für einen Concept Drift kennen wir alle aus Spam-Filtern. Während früher E-Mails mit dem gleichen Absender, die häufig aufeinanderfolgten oder über viele Mailkonten mit dem gleichen Betreff verschickt wurden, als unerwünschte Massen-E-Mail galten, haben wir es heutzutage mit diversen automatischen Kaufbestätigungen und automatisierten Benachrichtigungen zu tun. Ein Spamfilter, der auf dem alten Konzept von Spam-E-Mails liefe, würde heutzutage also legitime E-Mails aussortieren.
Fazit
Das Beispiel zeigt deutlich, dass das Erstellen und Bereitstellen eines ML-basierten Systems kein abgeschlossener Prozess ist. Es reicht also nicht, wenn wir ein Team einmal dafür bezahlen, ein möglichst akkurates Modell zu liefern und zu deployen. Jedenfalls nicht, wenn wir ein nachhaltig funktionierendes Artefakt in der Hand halten möchten. Vielmehr sollten wir uns bewusst sein, dass sich die Welt um uns herum und damit auch die inneren Faktoren des Machine-Learning-Prozesses ständig verändern.
Summary
Möchten wir also ein ML-basiertes System betreiben, sollten wir uns bewusst sein, dass die laufenden Kosten nach der Entwicklung nicht bloß mit der IT-Infrastruktur zusammenhängen. Man kauft kein fertiges Haus, man kauft sich Expertise auf Dauer ein. Nur so sind die Zuverlässigkeit und Weiterentwicklung des Systems gewährleistet.
MLOps unterstützt diesen Prozess mit diversen Tools für das Scoping und Deployment sowie die Wartung und das Monitoring von ML-Projekten. In einigen Fällen ist es vonnöten, das Modell erneut zu trainieren. Bedient man sich Techniken wie dem „Transfer-Learning“ muss eventuell nicht von vorne begonnen werden, sondern es reicht die Ausprägungen durch Nachtrainings anzupassen.
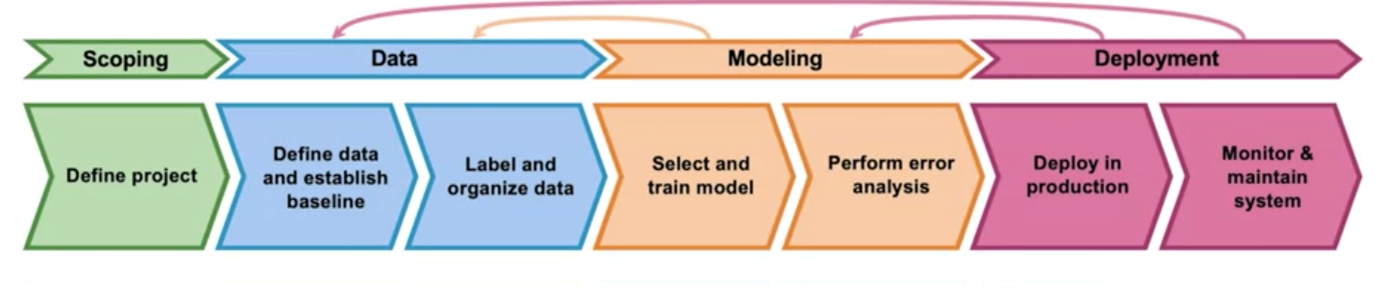
Zusammenfassend würde ich sagen, dass MLOps sich vor allem mit dem „Davor“, dem „Währenddessen“ und dem „Danach“ im Lebenszyklus eines ML-Modells beschäftigt. Es geht also um
- das richtige Einschätzen der Anforderungen und Ausgangssituation eines Projekts und den dazugehörigen Daten,
- die richtige Skalierung der Datenstrecken, des Modells, dessen Trainings und den Softwarestrukturen, in die es eingebettet werden soll
- ein Vorgehen, mit dem sich die Gültigkeit und Performance eines Modells prüfen und überwachen lassen,
- das Einhalten von Compliance-Anforderungen
- und die Wahrung von Sicherheit und Integrität des Systems.
Das Ziel von MLOps ist dabei, so wenig Ressourcen wie möglich für den größtmöglichen Effekt aufzuwenden.
Ausblick
Damit endet der erste Beitrag dieser Serie. Wie geht es weiter?
In den nächsten Teilen dieser Blogreihe, stechen wir mit dem sprichwörtlichen ML-Schiff in See und werden die grundlegenden Etappen der ML-Reise durchlaufen:
-> Modelltraining: Was gehört dazu, ein Modell auf den eigenen Daten zu trainieren? Wie wählt man das geeignete Modell und wie können uns Automatisierung und Pipelines bei beiden Schritten die Arbeit erleichtern?
-> Deployment: Wie integrieren wir das Modell in ein zukünftiges oder bestehendes System bzw. eine Infrastruktur? Und welche Strategien ermöglichen einen reibungslosen Umstieg?
-> Monitoring und Maintanance: Wie überwachen wir ab hier unser bestehendes ML-System? Welche Entwicklungen können Anpassungen erfordern und wie bereiten wir uns auf diese vor?
Ich hoffe, ich konnte mit dieser Einführung dein Interesse für MLOps wecken und wir sehen uns im nächsten Blogbeitrag wieder.


