

Darf ich vorstellen: Neo4j, NoSQL-Datenbank, in Java implementiert, Open-Source-Produkt und Heldin dieses Blogbeitrags. Was aber viel spannender ist: Neo4j ist eine der wenigen nativen Graphdatenbanken, die es gibt, also eine Datenbank, die auf vernetzte Daten spezialisiert ist.
Heldin? Ist das nicht ein bisschen übertrieben? Und was kann sie wirklich, diese Neo4j? Oder anders gefragt: Was macht ein Netzwerk, oder genauer, die Strukturen eines Netzwerks, für Datenanalysen so interessant? Und was in aller Welt hat eine eigene Datenbank dafür anzubieten?
Was Netzwerke über Menschen und Eigenschaften verraten
Ein Netzwerk besteht aus unzähligen Verbindungen und Knotenpunkten. Soziale Netzwerke sind dafür ein schönes Beispiel. Wie bei allen Netzwerken kommt es bei Facebook, Instagram und Co. vor allem darauf an, wer wen kennt, was zwei Personen verbindet oder über wie viele Ecken zwei Menschen verbunden sind. Die Beziehungen stehen also im Vordergrund und spielen insgesamt eine größere Rolle als die Eigenschaften einer einzelnen Person. Die Beziehungen können sehr unterschiedlich ausgeprägt sein. So können Personen befreundet sein, verheiratet und verwandt sein, einander blockieren, Mitglieder von Gruppen und Ausbildungsstätten sein, Unternehmen angehören und so weiter.
Dazu kommt, dass die Beziehungen zwischen den „Entitäten“ eines sozialen Netzwerks versteckte Informationen enthalten, die aus den reinen Eigenschaften einer Person nicht herauszulesen wären. Von einer völlig fremden Person erfahren wir zum Beispiel, dass sie Mitglied eines Tennisclubs ist. Daraus können wir schlussfolgern, dass diese Person Tennis mag, sportlich ist und im Großraum des Tennisclubs wohnt. Diese Informationen werden kommerziell genutzt, um personalisierte Werbung zu generieren … und schon erhält der oder diejenige Angebote für Vitaminpräparate und Nahrungsergänzungsmittel im nächsten Supermarkt.
Graphen: Große Netze mit Knoten und Kanten
Eine native Graphdatenbank macht es möglich, vernetzten Daten effizient abzulegen und sogar zu verarbeiten. Sie hilft uns, mithilfe von mathematischen Graphen unter anderem komplexe Muster im Detail zu erfassen, darstellen und zu speichern. Graphen sehen aus wie ein großes Fischernetz, eine Struktur aus Knoten und Kanten. Mit mächtige Algorithmen können wir sie lesen, Gruppierungen erkennen, einflussreiche Elemente und kürzeste Wege finden oder Ähnlichkeiten von Objekten analysieren. Eine Graphdatenbank hilft uns dabei und ist in der Lage, über Entitäten und Beziehungen neue Informationen zu generieren. Oder verdeckte Informationen zu finden und beispielsweise Betrugsversuche aufzudecken.
Wo relationale Datenbanken straucheln
Relationale Datenbanken sind weiterhin ein wertvolles Werkzeug, um Daten zu speichern und sollten nicht als Gegenstück einer Graphdatenbank angesehen werden, bieten aber in manchen Anwendungsfällen nicht die Mächtigkeit, die eine Graphdatenbank mitbringt.
Stellen wir uns vor, wir befinden uns in einer der besagten Social Network Domains. Würden wir hier die Beziehungen zwischen Personen für eine relationale Datenbank modellieren, würden wir im ersten Schritt vermutlich zwei Tabellen Person und Relation anlegen. Hierbei bildet Person die Tabelle, die die Daten, wie beispielsweise den Namen einer Person enthält – Relation bildet die Verbindung der Personen, mit Fremdschlüsseln auf die aktive Person (fromPersonId) und die passive Person (toPersonId).

Ein Netzwerks mit einer enormen Menge an Entitäten belastet eine relationale Datenbank. Das liegt daran, dass die Anfragen an eine relationale Datenbanken auf der Datenmenge skalieren, oder einfach ausgedrückt: Je mehr Daten berücksichtigt werden, desto langsamer ist die Anfrage. Zwar sind die meisten relationalen Datenbanken für große Anfragevolumen optimiert, aber das Problem bleibt grundsätzlich bestehen und führt gerade im (very) Big-Data-Umfeld schnell zu Performance-Problemen.
Besonders die Beantwortung der Frage „Über wie viele Ecken kennen sich zwei gegebene Personen?“ ist im relationalen Modell schwer zu beantworten. Dafür müssten genauso viele Joins erfolgen, wie es Relationen zwischen den Personen gibt – also eine in der Regel unbekannte Größe. Und Joins sind teuer. Bei Personen, die einander nicht kennen oder deren Distanz größer ist, als wir per Joins in vertretbarer Zeit bestimmen können, müssen wir irgendwann aufgeben.
Relationen von der anderen Seite betrachten – die Kernkompetenz der Graphdatenbank
Modellieren wir die gleiche Situation in einer Graphdatenbank, erhalten wir zwei Knoten: einen für jede Person; sowie zwei Relationen: eine für jede (gerichtete) Beziehung zwischen den Personen.
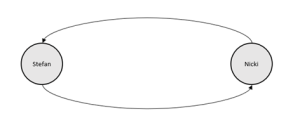
Was auf den ersten Blick recht ähnlich aussieht, hat eine Reihe von Vorteilen.
- An jedem Knoten haften technisch nur die ausgehenden Relationen an. Das bedeutet, wir übergeben dem Objekt selbst die Verantwortung für seine „Join“-Partner.
Haben wir einen konkreten Knoten an der Hand, müssen wir nur die Beziehungen betrachten, die diesen Knoten betreffen. Das gleiche gilt für Folgeknoten.
Damit skalieren die Anfragen nicht auf der Datenmenge, sondern auf der Suchtiefe.
Die Menge der Objekte fällt bei einer Graphdatenbank damit deutlich weniger ins Gewicht als bei einer relationalen Datenbank. - Die Frage, über wie viele Ecken sich zwei Personen kennen, löst die Graphdatenbank über einen fertigen Algorithmus (eine Implementierung des Shortest-Paths). Dieser wird von Neo4j direkt mitgeliefert und funktioniert out-of- the-box.
Diese Vorteile kommen zustande, weil die Graphdatenbank Relationen als persistente Objekte behandelt. Das hat aber auch seinen Preis: Je mehr persistente Objekte, umso größer der Aufwand beim Speichern. Denn was in einer relationalen Datenbank ein Fremdschlüssel ist, ist hier eine Entität. Etwas überspitzt könnte man sagen: Ein Objekt mit 100 Fremdschlüsseln bildet in einer relationalen Datenbank nur eine einzige Entität, in Neo4j dagegen 101 Entitäten. Es lohnt sich also, im Vorfeld zu prüfen, wie viele Objekte wie oft gespeichert werden müssen und welches System wir hier aufsetzen wollen. Ein Event-System, das sehr viele Elemente in sehr kurzer Zeit speichert, wäre beispielsweise kein guter Anwendungsfall für Neo4j.
Wie erwähnt handelt es sich bei Neo4j um eine native Graphdatenbank. Was ist das Besondere daran? Wie unterscheidet sich eine native Graphdatenbank von anderen Graphdatenbanken wie Amazon Neptune oder Azure Cosmos DB mit Gremlin, denen wir am Markt recht häufig begegnen?
Neo4j ist eine der wenigen Graphdatenbanken, bei denen die Daten tatsächlich als echter Graph gespeichert werden, ergo: nativ. Bei nicht-native Graphdatenbanken handelt es sich dagegen in der Regel um relationale Datenbanken, die mit einem zusätzlichen Layer ausgestattet wurden, der die Daten als Graph anbietet. Zwar sind diese Datenbanken durchaus für Graphstrukturen optimiert, doch die Nachteile relationaler Datenbanken werden sie, wenn es um vernetzte Strukturen geht, dadurch leider nicht los.
Wie viele Label hat ein Knoten?
Was SQL für eine relationale Datenbank, ist Cypher für Neo4j. Bei Cypher handelt es sich also um eine deklarative Abfragesprache für die Interaktion mit Neo4j. Im Gegensatz zu SQL baut Cypher hauptsächlich auf Pattern-Matching auf. Das heißt, Anwendende beschreiben den Sub-Graph mit denen sie interagieren möchten und die gewünschten Aktionen.
Was steckt dahinter?
Neo4j arbeitet mit einem sogenannten Label-Property Graph. Das bedeutet, alle Entitäten bekommen ein Label, also ein Etikett, das die Art der Entität beschreibt. Ein Knoten im sozialen Netzwerk könnte beispielsweise das Label „Person“ haben. Während Knoten mit beliebig vielen Labels bezeichnet werden können, haben Relationen genau ein Label: den Type. Alle Entitäten, oder besser: Knoten und Kanten eines Label-Property-Graphen, können außerdem Properties besitzen. In Neo4j werden die Properties als Json Objekt abgelegt. Darin können alle Eigenschaften eines Knotens oder einer Kante schemalos enthalten sein.
Durch die Tatsache, dass es Knoten, Kanten und Properties gibt, sieht Cypher auf den ersten Blick etwas kryptisch aus:
- Knoten werden als runde Klammern geschrieben, die ihre Labels enthalten können,
- Relationen als Pfeile mit eckigen Klammern, die den Type enthalten
- Properties als Json Objekt in geschweiften Klammern
Ein Beispiel: Nehmen wir Stefan, er ist 38 und spielt seit 2020 Gitarre. Daraus ergäbe sich folgender Sub-Graph und darunter die Beschreibung in Cypher:


In Neo4j würde Stefan als ein Knoten geführt mit dem Label Person, zwei Properties name (ein String) und age (ein Integer) und mit einer Relation vom Type PLAYS , der eine Property since besitzt. Die Gitarre würde dargestellt als Knoten mit zwei Labels Instrument und Guitar und die Relation geht von Stefan zur Gitarre.
Cypher kommt nun mit einer Reihe von Befehlen daher, die beschreiben, wie mit Sub-Graphen interagiert werden soll, wie z. B. Match, was so viel bedeutet wie „Finde das Muster“. So würde beispielsweise die Query MATCH (p:Person {age:35})-[:PLAYS]->(:Guitar) RETURN p.name die Namen aller Nutzer zurückgeben, die 35 sind und Gitarre spielen.
Dies nur als allererster Eindruck. Cypher ist mächtig und damit groß. Wer mehr über Cypher erfahren möchte, der sollte hier fündig werden: https://neo4j.com/docs/cypher-refcard/current/
Algorithmen ausführen
Eine Besonderheit von Neo4j ist, – wir hatten es schon erwähnt – dass Graph-Algorithmen direkt auf der Datenbank ausgeführt werden können. Dabei kommen Plugins zum Einsatz. Diese Plugins erhalten wir in Form von JAR-Files, die im Plugin-Ordner der Neo4j-Installation abgelegt werden können. Da Neo4j selbst in Java entwickelt ist, werden diese Plugins in der kommerziellen Version direkt, in der Community-Version beim Neustart, in den Kontext der Datenbank aufgenommen. Von hier aus liefern sie Hintergrundprozesse oder aus Cypher heraus aufgerufene Funktionen.
Unter den Akronymen APOC und GDS publiziert Neo4j selbst zwei offizielle Plugin-Libraries: Graph-Data-Science und Awesome Procedures on Cypher.
GDS enthält alle relevanten Graph-Algorithmen wie
- Community Detection,
- Path-Finding,
- u. s. w.
APOC enthält alles, was sich darüber hinaus als interessant erwiesen hat, wie
- Lucene-Indexing,
- OpenStreetMaps-Anbindung,
- Anbindungen an eine sekundäre Couch-DB
- u. s. w.
Produktiv lohnt es sich fast immer, APOC zu installieren. GDS ist empfehlenswert, wenn Graph-Algorithmen konkret benötigt werden.
Was kann Neo4j, und was nicht?
Fassen wir einmal zusammen: Neo4j glänzt beim Lesen langer Pfade, hat jedoch Probleme, wenn es um das schnelle Schreiben von Entitäten geht. Ein Vorteil ist wiederum, dass an jedem Knoten technisch nur seine ausgehende Relation anhaftet. Die Performance bei Suchanfragen wird bei ihr demnach nur beeinträchtigt, wenn die betrachteten Pfade sehr tief ausfallen. Genau genommen versucht Neo4j bei jeder Cypher-Query durch Indexing das konkreteste Element zu finden und sich von dort aus über die Relationen weiterzuhangeln.
Eine Anfrage wie MATCH (n)<-[:R]-(p:Person) WHERE id(p)=11 return n lädt beispielsweise alle Knoten, die von der Person mit der ID 11 durch eine ausgehende Relation vom Typ R erreichbar sind. Es werden also nicht alle Relationen vom Typ R betrachtet, sondern mittels Indexing wird die Person mit ID 11 ermittelt und nur deren Relationen betrachtet. Sind solche Relationen vorhanden, ist dieses Vorgehen natürlich toll. Dafür müssen diese jedoch erstmal gespeichert worden sein, was in der Regel ausfällt, wenn die Relationen für uns nicht im Fokus stehen. Daher lässt sich als Faustregel sagen, dass eine Neo4j gut geeignet ist, wenn die Verbindungen zwischen den Entitäten genauso wichtig, oder wichtiger sind als diese selbst.
Besitzt unsere Domain hingegen wenige oder keine Relationen, müsste Neo4j ständig auf den Index zugreifen. Dabei würde mit der Datenmenge skaliert, sodass Neo4j bestenfalls nicht performanter wäre als eine relationale Datenbank. Daher eignet sich Neo4j wie erwähnt auch nicht für den Einsatz bei einem Event-Speicher.
Weiterhin legt die Neo4j jedes Attribut eines Knotens als Datei ab, daher sollten hier keine Blobs, also große Dateien in binärer Form, abgelegt werden. Sie eignet sich also nicht für einen reinen Bild-Speicher.
In welchen Gebieten kann Neo4j eingesetzt werden?
Oben wurde bereits erwähnt, dass sich die Neo4j für den Einsatz in sozialen Netzwerken eignet. Also dort, wo die Domain lange und wichtige Verbindungen zwischen den Daten aufweist. Auch die Versorgungswege oder Netzwerk-Infrastrukturen sind für den Einsatz interessant.
Empfehlungen aussprechen
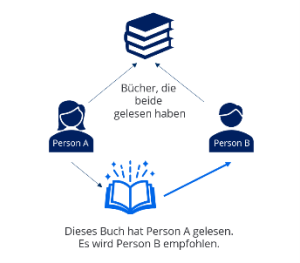
Ein Musterbeispiel für den Einsatz der Neo4j sind Recommendation-Engines, die Vorlieben der Nutzer erkennen und Empfehlungen aussprechen. Da Cypher Daten anhand von Pattern-Matching laden kann, fällt es leicht, Muster zu beschreiben wie „Dinge, die von einer Person gemocht werden, die das gleiche Ding mag wie ich“.
Verwandte Inhalte finden
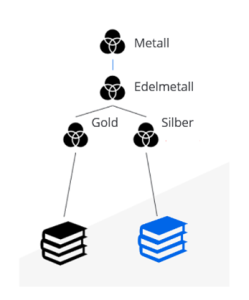
Nicht ganz so leicht, aber immer noch relativ einfach lassen sich „Best Match“-Suchen umsetzen. Stellen wir uns vor, wir suchen in einer Datenbank, die Dokumente über Metallverarbeitung verwaltet nach einer Anleitung zur Goldverarbeitung.
Selbst wenn ein solches Dokument nicht existiert, wird uns weitergeholfen. Denn die Relationen, die dem Edelmetall Gold anhaften, liefern verwandte Ergebnisse, vielleicht ein Dokument, das beschreibt wie ein anderes Edelmetall (z. B. Silber) verarbeitet werden kann.
Die Neoj4 hilft hierbei, indem sie uns eine Möglichkeit liefert, diese Ähnlichkeit zu berechnen. Dafür wird die Distanz im Graphen zum perfekten Ergebnis berechnet. Die Anleitung zur Goldverarbeitung hätte demnach einen Distanzwert von 0 zum „perfekten Ergebnis“, weil es das perfekte Ergebnis ist.
Das Dokument, in dem beschrieben wird, wie Silber verarbeitet wird, ist hingegen eine Pfadlänge von zwei Kanten vom perfekten Ergebnis entfernt, könnte damit aber durchaus interessante Informationen für die suchende Person besitzen. Eine baumartige Konkretisierung nennt sich Ontologie.
Neo4j und Ontologie
Wir können behaupten, dass Neo4j in fast allen Domainen, in denen Ontologie genutzt wird, einen Mehrwert liefert. Wie bei der Dokumentsuche eignet sich die Datenbank beispielsweise auch, wenn es darum geht, chemische oder biologische Testverfahren zu verwalten, eine passende Fachkraft für ein bestimmtes Projekt zu finden oder Herbizide und deren EU-Gesetzesnormen zu verbinden.
Künstliche Intelligenz und Machine Learning
Nach eigenen Aussagen ist die Neo4j auch bestens für KI und Machine Learning geeignet und funktioniert gut im Einklang mit Googles Vertex AI.
und Machine Learning geeignet und funktioniert gut im Einklang mit Googles Vertex AI.
Tatsächlich liefert die bereits erwähnte Plugin-Library GDS Algorithmen für viele Machine-Learning-Anwendungsfälle oder vorbereitende Maßnahmen, wieMissing-Link-Prediction, Fraud Detection, Entity Resolution und viele andere.
Beim Thema Machine Learning mit der Neo4j tun sich also riesige Möglichkeiten auf. Da lohnt es sich, einen Blick reinzuwerfen, zumal die Neo4j mit der Graph-Academy viele Ressourcen und kostenlose Zertifikate fürs Selbstlernen liefert
Los geht’s: Installieren und starten
1. Download und Infrastruktur
Wie viele Datenbanken lässt sich Neo4j leicht auf diversen Wegen installieren:
- Die Binary lässt sich von https://neo4j.com/download-center beziehen, das Docker-Image heißt schlicht „neo4j“. Mit den bekanntesten Cloud-Anbietern pflegt Neo4j eine Partnerschaft.
- Die Neo4j Desktop-Applikation kann unter https://neo4j.com/download-center/#desktop heruntergeladen werden. Allerdings nur als Spielwiese, nicht für den produktiven Einsatz.
Als weitere Umgebung bietet Neo4j eine eigene Cloud an: die Neo4j Aura, für die zwar eine Kreditkarte verlangt wird, die aber zumindest eine Free-Instanz erlaubt. Achtung: Neo4j Aura wird aktuell nicht durch Terraform unterstützt. Dafür fehlt der dafür nötige API-Endpoint. Das Feature wird aber derzeit (Stand November 2022) entwickelt.
2. Die ersten Schritte
Für die ersten Schritte kommt man mit Docker vermutlich am schnellsten an die Startlinie:
- docker run -p 7474:7474 -p 7687:7687 neo4j startet die Datenbank, deren eigene GUI direkt unter localhost:7474 erreichbar ist. Mit dem default Nutzer (und Passwort) neo4j darf man die Anwendung initial betreten, muss danach aber ein neues Passwort vergeben.
- Zuletzt führt die Ausführung von :play in der GUI dazu, dass ein eigenes Tutorial auf der Datenbank gestartet wird mit dem man direkt herumspielen kann, um Cypher und die Fähigkeiten von Neo4j kennenzulernen.
Fig. 6 Neo4j Oberfläche
Viel Spaß beim Ausprobieren!
—
Das könnte auch interessant sein:



