
1 Die Aufgabenstellung
Details änden sich in Big Data Hackathon zu Community Days (28.10.2016) Kurz gesagt geht es darum, für einem eingehendem Clickstream (Benutzer mit verschiedenen bekannten Attributen, die gerade eine Webseite besuchen) Werbeanzeigen zu platzieren. Diese Anzeigen auf den Benutzer und sein Konsumverhalten angepasst sein. Schließlich kostet die Werbeanzeige auch Geld das über Rückschlüsse aus erfolgreichen Einkäufen verdient werden will. Von der „REST Event Source“ werden Daten aus dem Original-Stream verteilt. Der „Real Time Bidding Agent“ nimmt die Informationen entgegen und versucht, für möglichst wenig Geld die Werbefläche zu ergattern (wenn sich diese Ausgabe lohnt. Wir wollen wie oben erwähnt Geld verdienen. Ist für den Kunden keine lohnende Werbeempfehlung bekannt so sparen wir normalerweise dieses Geld. Um Kundenverhalten modellieren zu können kann alternativ auch ungezielt Werbung geschaltet werden.) Um die Bedürfnisse der Kunden zu erkennen, zieht der „Real Time Analytic Agent“ diese Daten ab um die „EventHistory“(eine Datenbank) dem Analytics Team zur Verfügung zu stellen. Das Analytics Team versucht mit unterschiedlichen Strategien den vom „Real Time Bidding Agent“ erwirtschafteten Ertrag zu optimieren.
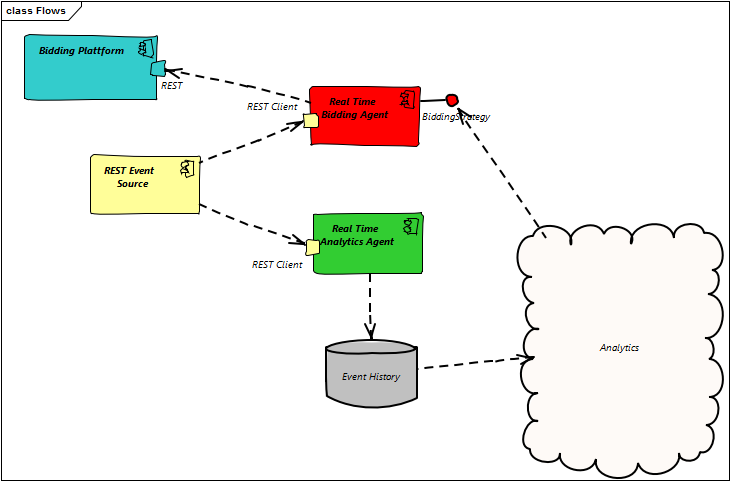
2 Es geht los
Der Raum Zugspitze ist überfüllt. Fast alle Anwesenden Kollegen versuchen am Hackaton teilzunehmen bzw. einen Platz zum zuschauen zu ergattern. Das Team um Lukas Berle hat in den ersten Momenten die Aufgabe, eine optimierte Antwortstrategie zu entwerfen. Um hier schnell und zielgerichtet antworten zu können, richten die Kollegen einen Storm-Cluster ein und richten eine Topologie ein, welche für die Click-Events Gebote verschickt. Die Datensammler (Team „Real Time Analytic Agent“) setzten eine MongoDB auf, welche alle RestEvents sammelt. Das sind einerseits die Daten aus dem Clickstream mit Benutzerinformationen, die versendeten Gebote und die Information ob mit der angebotenen Werbung Geld verdient wurde. Das Analytics Team welches sich mit Machine Learning, Visualisierung und „HokusPokus“ muss noch auf Analysedaten warten und diskutiert wie man die erwarteten Daten modellieren kann.
3 Die Daten fließen
Während der Storm-Cluster hochgezogen wird, sammeln Waldemar und Daniel die Daten in der MongoDB (v. 3.0.6) die auf Ralfs Rechner läuft. Ralf hofft hier direkt mit R über die RMongo Bibliothek mit Analysen starten zu können. Dimitri erklärt interessierten Anwesenden,wie man hier mit Baummodellen und Visualisierung das Kundenverhalten auswerten kann. Für die Auswertung in Weka benötigen wir tabellarische Daten. Eine Möglichkeit, diese Daten zu exportieren,ist mittels Kommandozeile und
mongoexport --type=csv --db {hackathon} --collection {..} --fields {..}
auszuführen. Da wir die einkommenden Daten (Clicks und die zeitversetzte Information über Kauferfolg) aktuell in zwei Tabellen sammeln, ist diese Methode suboptimal. Ein JOIN muss her. Hier stellen wir fest daß die „uralte“ 3.0.6 er MongoDb noch nicht den $lookup Aggregator kennt. Dumm gelaufen! Sollen wir jetzt einen MapReduce Job schreiben oder lieber doch auf eine aktuelle MongoDb 3.2.10 migrieren. Können wir die Daten in die neue Version retten? Die MapReduce Jobs liefern nicht in kurzer Zeit das gewünschte Ergebnis und Debuggen kostet zu viel Zeit. Also doch ein Live Upgrade. Wir installieren parallel eine neue MongoDb 3.2.10 auf Ralfs Rechner. Alle 15-20 Minuten exportieren wir die Daten als CSV in einen Ablageordner im Netzwerk. Jetzt wird es spannend. Data Folders kopieren und Neustarten… Und schon läuft MongoDb auf 3.2.10 mit keinem nennenswerten Datenverlust. Daniel stellt die Verbindung, um und wir können endlich die ersehnte Datenmatrix für das „Analytics Team“ bereitstellen. Es ist inzwischen schon nach 13.00. Die Exports der aggregieren CSV können mit 3T MongoChef erstellt werden. Jetzt könnte man die Daten eigentlich schön sichten. Schade,daß RMongo die 14 Spalten nur als JSON versteht. Ist es ein Problem mit der verwendeten Version der R-Bibliothek ? Auf jeden Fall wird hier nur wertvolle Zeit vernichtet (eine aggregierte Abfrage braucht über eine Minute, um einen Dataframe mit ca. 20T Zeilen und einer Spalte zurückzuliefern). Damit hängt das ganze „Analytics Team“ von den Kopien der CSV Exports ab.
4 Liefern Sie mal eine neue Strategie!
In der Zwischenzeit ist das Team mit dem RealTimeBiddingAgent schon lange so weit, dass es die noch nicht vorhandenen Modelle und Analysen vom „Analytic Team“ in Strategien gießen möchte. Außer allgemeinen Kategorien (die Apple User kaufen nur bei Unterhaltungselektronik und Medien) findet sich leider wenig Gewinnbringendes. 100 Prozent Permiumuser geben richtig viel Geld aus – aber bei nur 14 erkannter User in 8 Stunden bräuchten wir hier schon eine Luxusartikel im Millionenwert, um endlich reich zu werden.
5 Wie ist es gelaufen und was haben wir dabei gelernt ?
Auch ohne Kanban oder Scrum organisieren sich die Teams – scheinbar haben einige irgendwo heimlich geübt. Vermutlich hätten wir nach Sprintplanung und Schätzmarathon auch erst mittag mit den Umsetzung starten können. Die Gruppen finden sich und werden produktiv. Natürlich klappt mit der vielen neuen Technik nicht alles:
- Einige Impressions gehen bei der Datenbank Live Migration verloren.
- Die Strategien haben oft „interessante“ Seitenwirkungen. In der knappen Zeit hatten wir nicht mit vielen Anpassungen an der Strategie durch verbesserte Modelle gerechnet.
Der RoundTrip hat allerdings geklappt. Bis die interessanten Erkenntnisse entdeckt wurden,war die Zeit dann allerdings zu knapp, um hieraus Strategien abzuleiten. Immerhin können wir inzwischen in MongoDB zwei Tabellen (clicks, impressions) joinen:
db.clicks.aggregate([
{
$lookup:
{
from: 'impressions',
localField: 'id',
foreignField: 'clickId',
as: 'joined'
}
},
{$unwind: '$joined'},
{$project:
{
'age': '$age'
, 'gender': '$gender'
, 'location': '$location'
, 'website': '$website'
, 'timestamp': '$joined.timestamp'
, 'profit': '$joined.profit'
, 'job': '$job'
, 'deviceOs': '$device.os'
, 'deviceBrowser': '$device.browser'
, 'deviceType': '$device.type'
, 'productLine': '$joined.winningBid.productLine'
, 'premium': '$joined.winningBid.premium'
, 'team': '$joined.winningBid.team'
, 'bid': '$joined.winningBid.bid'
}}
]
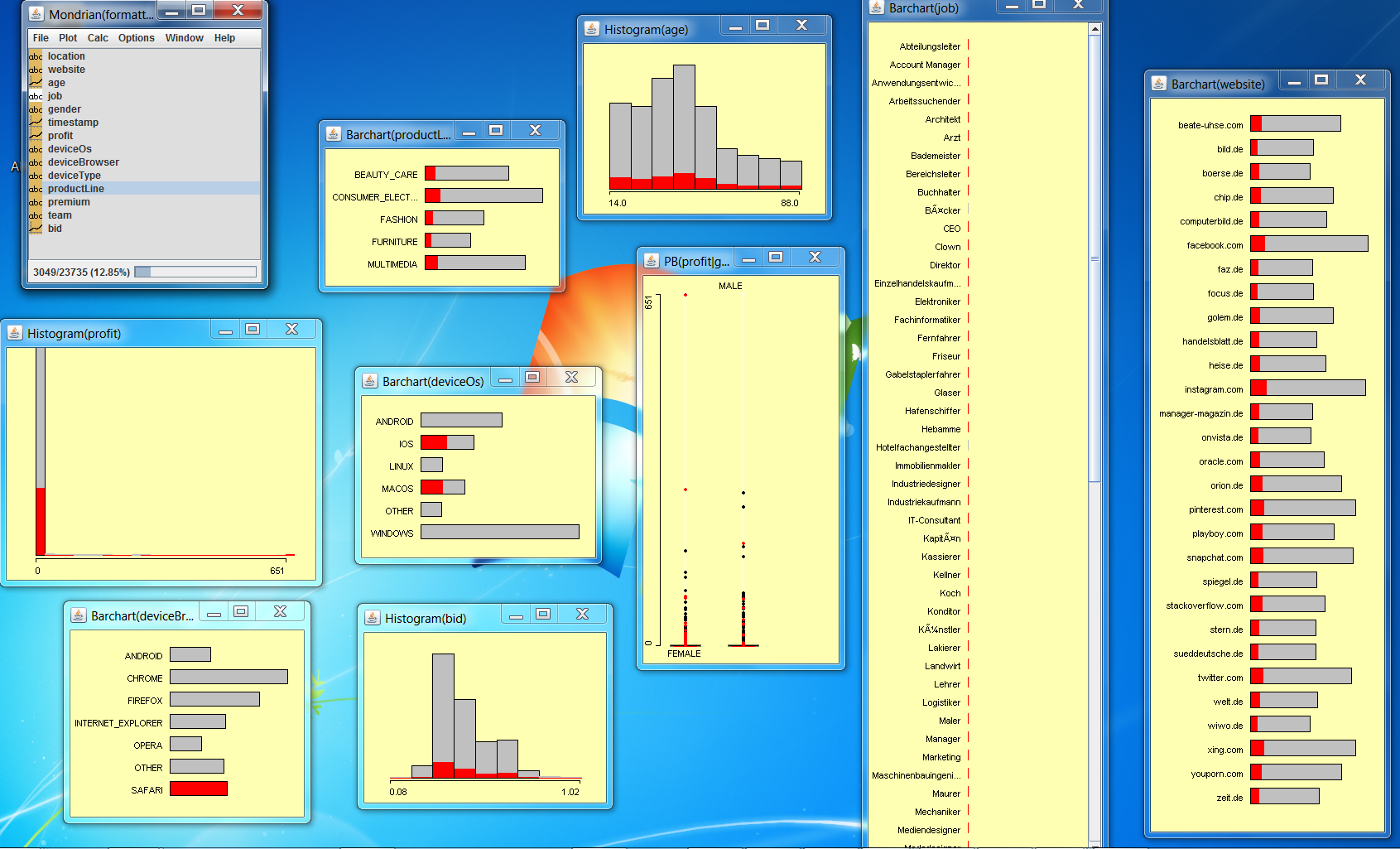
6 Bilder aus dem Analytics Sector
7 Annektoten
Noch bevor unsere DataScientists ihre Daten in analysefertiger Form vorliegen hatte, wurden bereits erfahrungsgestützte Modelle vorgeschlagen
- Frauen von 30-40 kaufen am meisten Beautyprodukte (diese These wurde vom weiblichen Teilnehmerkreis nicht einstimmig befürwortet und nicht implementiert)
- Eine Datenbank die nicht joinen kann ist doof – Da hat Bernhard natürlich recht
Deswegen haben wir im Live-Betrieb die MongoDB von 3.0.6 auf 3.2 upgedated. Eine Herkulesaufgabe: Datafiles kopieren. Starten – fertig 🙂
8 Und am Ende
Bleibt das Gefühl dass hier richtig Energie in den Hackathon geflossen ist und alle Beteiligten Spaß hatten. Vielen Dank an alle! Besonders herzlichen Dank an Christopher, der die Plattform bereitgestellt hat, um mit den Clicks und Impressions spielen zu können.
9 Ein wenig Data Science
Leider nicht während des Hackathons fertig geworden
Um eine Vorhersage machen zu können, welche Empfehlung wir nach den gewonnenen Erfahrungen aussprechen können trainieren wir ein „MultinomialLogisticRegression“ Modell. Da wir nur Gewinn machen unter der Annahme, dass wir nicht 0 Profit machen können wir die Datenbasis einschränken.
> sData<-subset(data,profit>0) > attach(sData) > library(MASS) > mn<-multinom(productLine ~ age + location + gender + job + deviceType + deviceOs + deviceBrowser, family=binomial()) > mn.best<-stepAIC(mn) > summary(mn.best) Call: multinom(formula = productLine ~ age + gender, family = binomial()) Coefficients: (Intercept) age genderMALE CONSUMER_ELECTRONICS -3.126288 0.01288730 3.7243051 FASHION -2.399828 0.02175771 0.7535859 FURNITURE -5.444786 0.07223687 2.0731203 MULTIMEDIA -1.928532 0.01505034 2.1050230 Std. Errors: (Intercept) age genderMALE CONSUMER_ELECTRONICS 0.6032644 0.01527161 0.4461687 FASHION 0.5880367 0.01635363 0.5022316 FURNITURE 0.9091175 0.02057506 0.5599580 MULTIMEDIA 0.4749802 0.01329519 0.3576919 Residual Deviance: 762.211 AIC: 786.211 > predict(mn.best,data.frame(age=40,gender="MALE")) [1] CONSUMER_ELECTRONICS Levels: BEAUTY_CARE CONSUMER_ELECTRONICS FASHION FURNITURE MULTIMEDIA > predict(mn.best,data.frame(age=40,gender="FEMALE")) [1] BEAUTY_CARE Levels: BEAUTY_CARE CONSUMER_ELECTRONICS FASHION FURNITURE MULTIMEDIA
Als relevante Faktoren (die wir zum Clickzeitpunkt haben) werden hier nur Alter und Geschlecht als AIC-bestes Modell gefunden. Damit können wir statistisch belegen dass die Frau ab 40 lieber zu Beauty-Care greift währen sich ein Mann mit Consumer-Elektronik begnügt. 🙂


