

Viele Unternehmen modernisieren ihre IT-Landschaften schrittweise, indem einzelne Funktionen aus bestehenden Monolithen herausgelöst und als Cloud-Anwendungen neu entwickelt werden. Während dieser Transformation müssen Alt- und Neusystem häufig über längere Zeit parallel betrieben werden. Die Synchronisation von Daten und Geschäftsprozessen stellt dabei eine besondere Herausforderung dar. In einem Kundenprojekt stehen wir genau vor dieser Aufgabe: Eine Komponente eines monolithischen ERP-Systems soll in der Cloud neu implementiert werden, während das bestehende System weiterhin produktiv und führend bleibt.
Änderungen am Monolithen sind prinzipiell möglich, benötigen aufgrund der Release-Prozesse allerdings lange und sind mit Risiko behaftet. Für die Kommunikation mit dem Cloud-Modul implementieren wir im Umfeld des Monolithen eine Service-Fassade mit Zugriff auf die Datenbank und Anwendungsschnittstellen des Monolithen. Die Kommunikation zwischen Alt- und Neusystem erfolgt bevorzugt eventbasiert über Kafka.
Um den Parallelbetrieb von Alt- und Neusystem sicherzustellen, soll eine Synchronisation beider Systeme über Events hergestellt werden.
Vorgehen zur Synchronisation
Zur Synchronisation vom Altsystem in das Neusystem wird das Altsystem erweitert, sodass jede fachliche Änderung als Event veröffentlicht werden kann. Die Events geben Auskunft darüber, welche fachliche Operation ausgeführt wurde und welches Domänen-Objekt wie geändert wurde. Wir bezeichnen diese Events daher als Domain-Events.
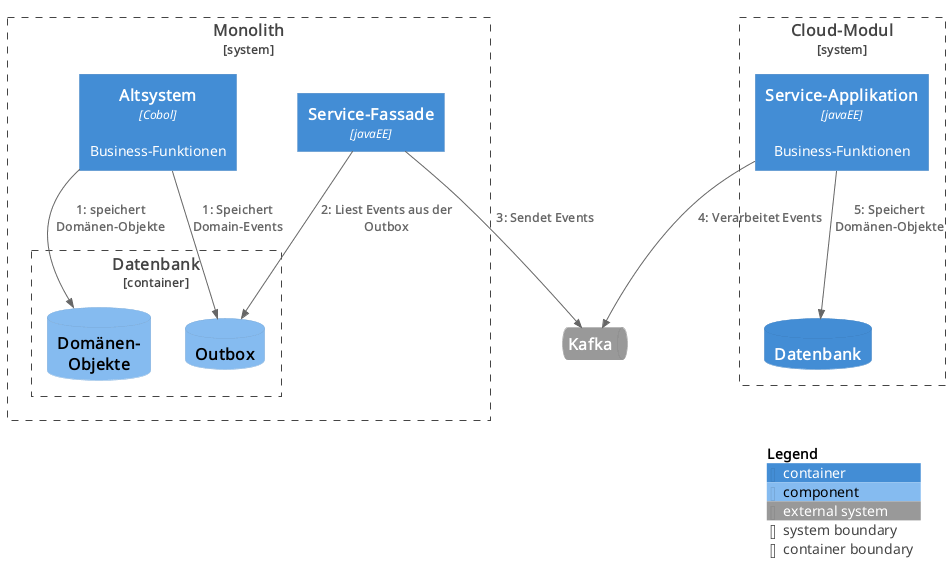
Das Altsystem schreibt die Domain-Events zunächst in eine Outbox-Tabelle in der Datenbank. In der Service-Fassade läuft ein Prozess, der periodisch die Outbox auf neue Events prüft und diese an Kafka sendet. Das Cloud-Modul verarbeitet diese Events und führt die entsprechenden Operationen in seinen Backend-Services durch.
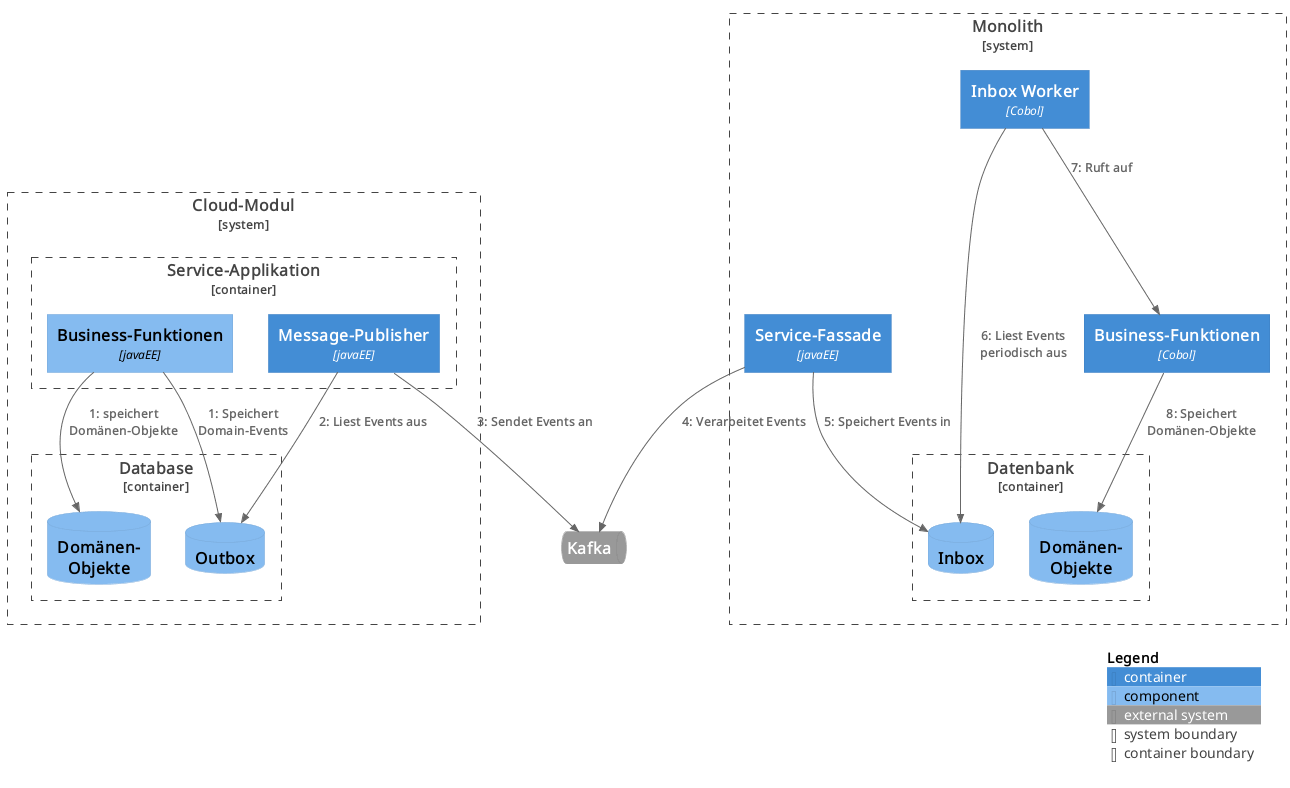
Zur Synchronisation vom Neusystem in das Altsystem werden ebenfalls die fachlichen Änderungen als Domain-Events veröffentlicht. Auch diese werden zunächst in eine Outbox-Tabelle geschrieben, ehe sie an Kafka gesendet werden. Aufseiten des Altsystems werden die Events zunächst durch einen Prozess der Service-Fassade konsumiert und in eine Inbox-Tabelle geschrieben. Von dort werden sie durch einen Hintergrund-Prozess des Monolithen gelesen. Dieser Prozess führt die Events mithilfe der bestehenden Business-Funktionen des Monolithen aus.
Konflikte vermeiden: Pessimistic Locking
Bei dieser Form der Synchronisation können Konflikte entstehen, wenn dieselben Business-Objekte parallel in beiden Systemen geändert werden. Der erste Ansatz zur Konfliktvermeidung, den wir betrachteten, beruht auf Pessimistic Locking. Im Prinzip bedeutet das, dass das Altsystem als führendes System Business-Objekte zur Änderung sperrt. Das Neusystem fordert vor jeder Änderung eine Sperre beim Altsystem an. Die Sperre wird gewährt, sofern das Altsystem das Business-Objekt nicht selbst gesperrt hat. Die Sperr-Anforderung kann mittels API- oder Command- & Response-Kommunikation über Kafka erfolgen.
Einen beispielhaften Ablauf zeigt die Grafik:
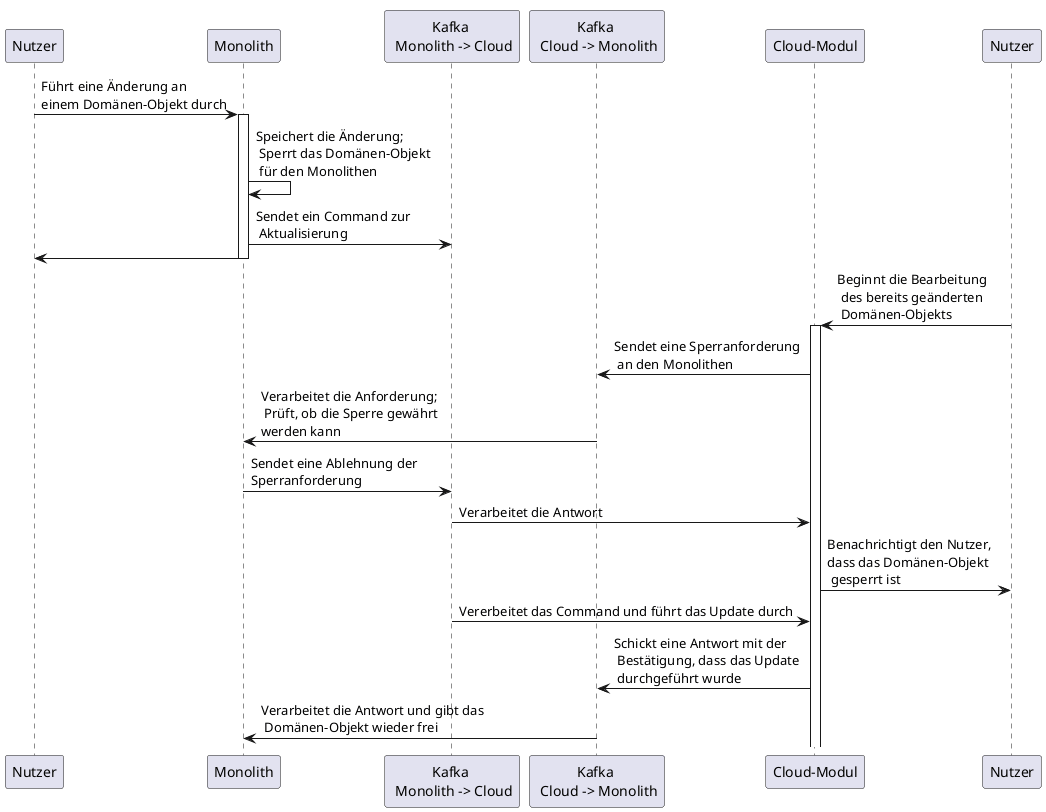
Im Altsystem wird eine Änderung vorgenommen. Das Altsystem sperrt das geänderte Business-Objekt und sendet an das Neusystem die Aufforderung, die Änderung ebenfalls durchzuführen.
Parallel wird im Neusystem versucht, eine Sperre für das bereits geänderte Business-Objekt zu erlangen. Die Sperranfrage wird vom Altsystem abgelehnt, der Anwender wird informiert, dass das Business-Objekt gesperrt ist und nicht bearbeitet werden kann.
Nachdem das Kommando zum Wiederholen der Änderung im Neusystem verarbeitet wurde, wird eine Bestätigung der Änderung an das Altsystem gesendet, worauf das Business-Objekt durch das Altsystem wieder freigegeben wird.
Das Vorgehen bietet den Vorteil, dass Konflikte weitgehend vermieden werden können. Allerdings erfordert die Einführung einer Sperrverwaltung im Altsystem einen aufwändigen Eingriff in das bestehende System. Darüber hinaus bewirkt die Notwendigkeit der Sperranforderung eine noch engere Kopplung des Cloud-Moduls an das Altsystem, die – besonders im Falle einer asynchronen Umsetzung – zu Latenzen führen kann.
Konflikte vermeiden: Optimistic Locking
Aufgrund der Nachteile einer Umsetzung mithilfe von Pessimistic Locking wurde als Alternative ein Ansatz auf Grundlage von Optimistic Locking betrachtet.
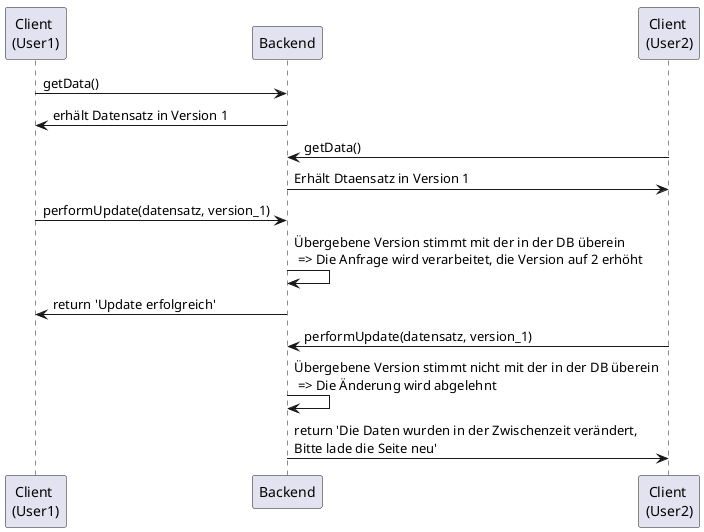
Während beim Pessimistic Locking versucht wird, Konflikte durch das Sperren von Datensätzen gar nicht erst entstehen zu lassen, beruht das Optimistic Locking darauf, Konflikte zu erkennen, wenn sie auftreten und durch den Anwender auflösen zu lassen. Typischerweise wird dazu jedes Business-Objekt mit einer Version oder dem Zeitstempel der letzten Änderung versehen, die beim Speichern hochgezählt bzw. aktualisiert werden. Zeitstempel oder Version werden vor der Bearbeitung des Datensatzes gelesen. Beim Speichern wird geprüft, ob der persistente Wert mit dem gelesenen Wert übereinstimmt. Ist dies nicht der Fall, wurde der Datensatz in der Zwischenzeit geändert. Typischerweise müssen die Daten nun neu geladen und die Änderung erneut durchgeführt werden.
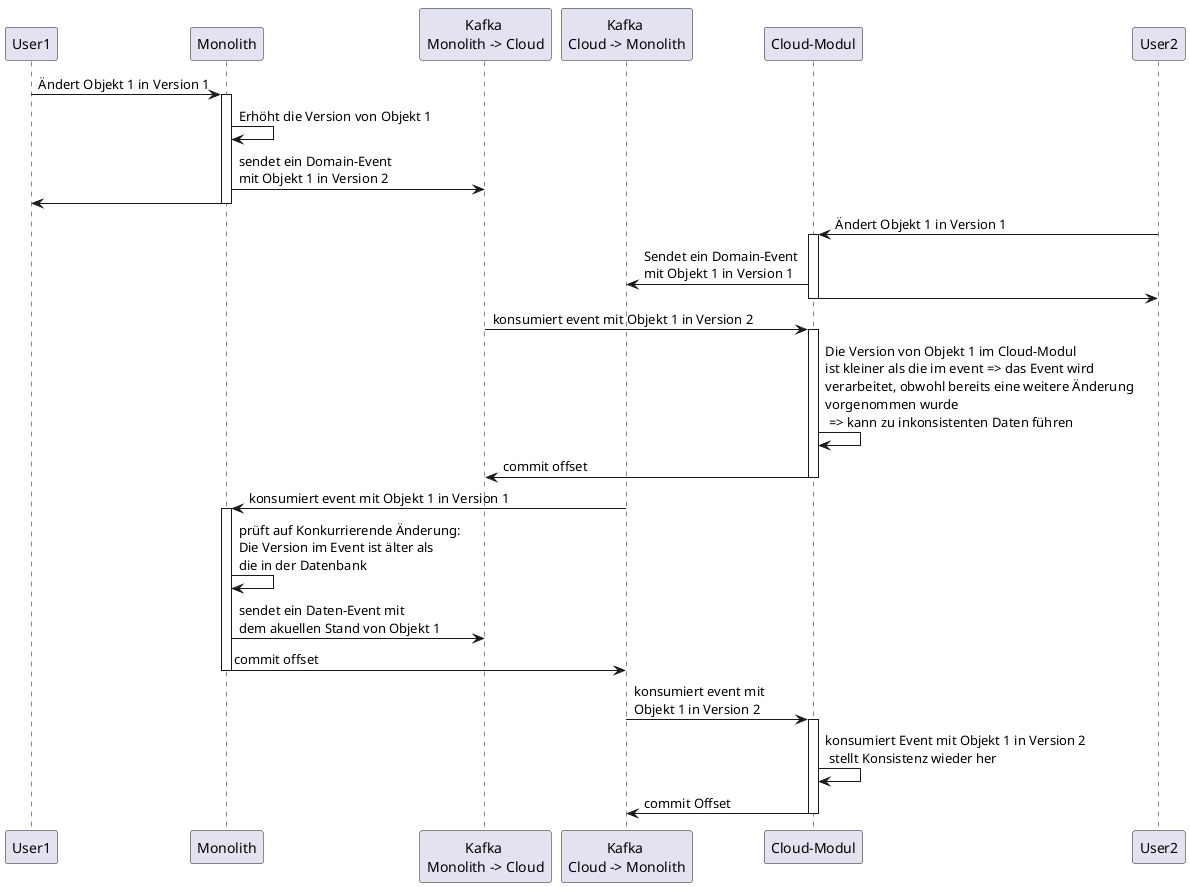
Bezogen auf unseren Anwendungsfall bedeutet das, dass alle Business-Objekte versioniert werden und das Altsystem als führendes System für das Hochzählen der Version in Folge von Änderungen verantwortlich ist. Jedes vom Altsystem ausgehende Domain-Event beinhaltet auch die aktuelle Version des jeweiligen Business-Objekts. Diese Version wird im Neusystem gespeichert und im Falle eigener Änderungen in den resultierenden Domain-Events mitgeschickt, jedoch ohne hochgezählt zu werden.
In unserem Beispiel ist das Business-Objekt bereits in beiden Systemen in derselben Version vorhanden. Nun wird das Objekt in beiden Systemen geändert. Das Altsystem erhöht die Version und informiert mit einem Domain-Event über die Änderung und die neue Version. Noch bevor das Event im Neusystem verarbeitet wurde, schickt dieses ebenfalls ein Event mit den Daten der Änderung sowie der zu diesem Zeitpunkt vorhandenen Version. Anschließend verarbeitet das Neusystem das Event aus dem Altsystem. Dabei können Änderungen überschrieben werden, die im Neusystem zwischenzeitlich vorgenommen wurden, aber noch nicht mit dem Altsystem synchronisiert waren.
Das Altsystem verarbeitet das Domain-Event aus dem Neusystem und stellt eine parallele Änderung fest, da die Version aus dem Event älter ist als die in der Datenbank. Als Reaktion darauf wird die Verarbeitung des Domain-Events abgelehnt und ein Sync-Event mit dem vollständigen Aggregat an das Neusystem geschickt. Mit den Daten dieses Events wird der komplette Datensatz im Neusystem überschrieben, wodurch die Konsistenz wiederhergestellt ist.
Dieses Vorgehen lässt Inkonsistenzen zu und behebt sie durch Überschreiben der Daten im Cloud-Modul. Von Nachteil ist, dass Änderungen im Cloud-Modul ohne Vorwarnung überschrieben werden und der Anwender ohne es zu bemerken auf veralteten oder sogar inkonsistenten Daten arbeiten kann. Dieses Problem kann abgemildert werden, indem das Nachführen der Änderung am Cloud-Modul im Altsystem als Kommando umgesetzt wird. Damit böte sich die Möglichkeit, den Anwender direkt über die Ablehnung der Anforderung zu informieren. Darüber hinaus könnte das Business-Objekt für weitere Änderungen gesperrt werden, bis die Konsistenz wiederhergestellt ist.
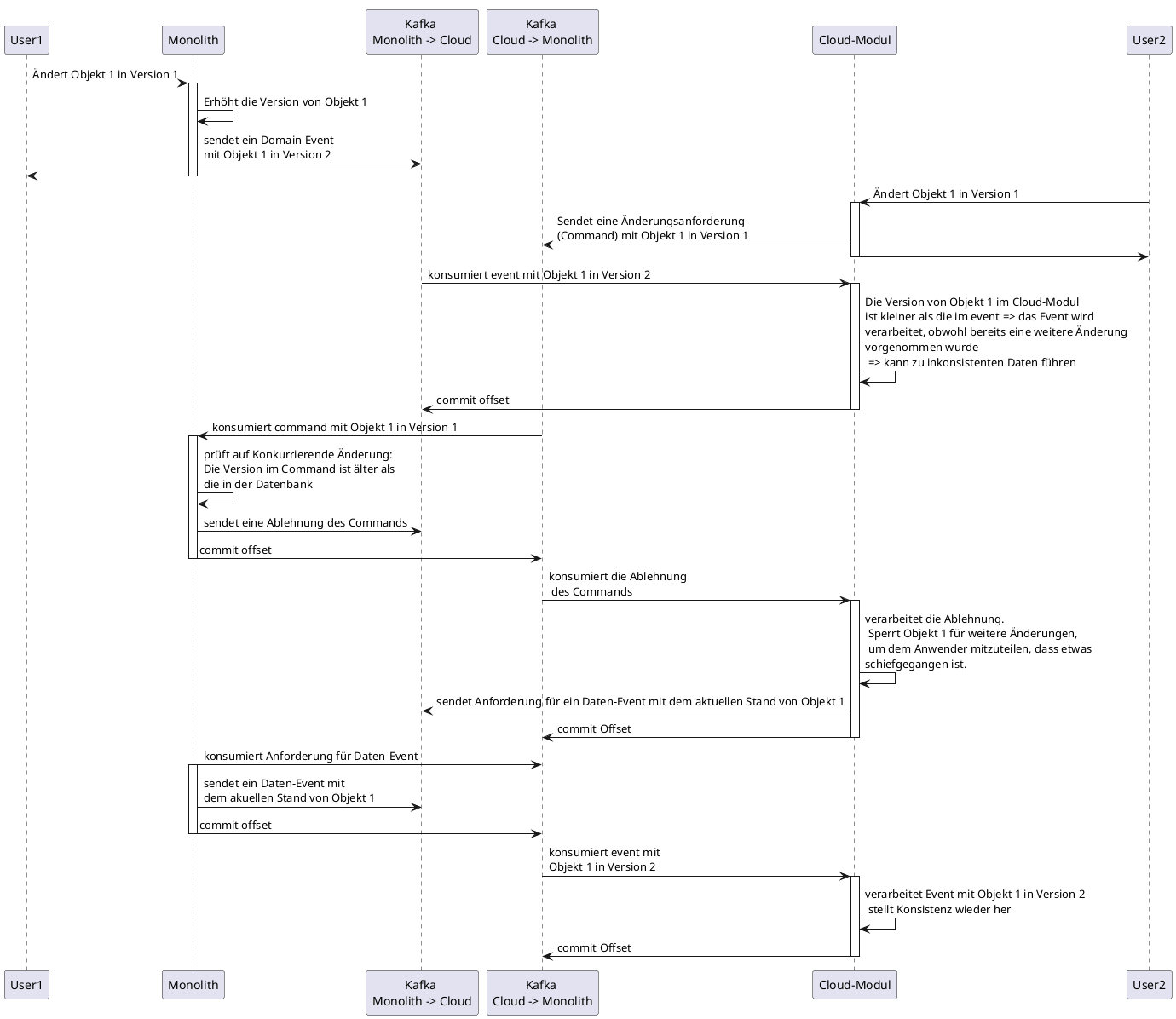
In Abwandlung zum vorherigen Beispiel wird nach der Änderung im Neusystem nun ein Command statt eines Events an das Altsystem gesendet. Das System kann dem Anwender kenntlich machen, dass die aktuelle Änderung erst nach der Bestätigung durch das Altsystem gültig ist. Das Altsystem lehnt die Änderungsanforderung ab, da eine parallele Änderung erkannt wurde. Das Neusystem verarbeitet die Ablehnung und sperrt das Business-Objekt für weitere Änderungen. Das Neusystem sendet nun ein weiteres Kommando, um einen vollständigen Stand des inkonsistenten Business-Objekts anzufordern. Das Altsystem antwortet mit einem entsprechenden Data-Event, welches im Neusystem verarbeitet wird, wodurch das Business-Objekt überschrieben und wieder für Änderungen freigegeben wird.
Zwar werden bei dieser Variante Änderungen auf veralteten Daten weitestgehend vermieden, jedoch hat dies den Preis, dass Business-Objekte gegebenenfalls für die Bearbeitung gesperrt werden. Darüber hinaus führt das Anfordern von Sperren zu einer engeren Kopplung beider Systeme, die sich auch durch Wartezeiten für den Anwender bemerkbar machen kann. Beides zusammen kann sich negativ auf die Akzeptanz des Neusystems auswirken.
Zyklische Updates
Ein weiteres Problem, das es zu lösen galt, ist das von zyklischen Updates: Wenn jede Änderung an einem Business-Objekt zu einem Domain-Event führt, welches vom jeweils anderen System verarbeitet wird, wodurch dort ein Business-Objekt geändert wird sodass wieder ein Domain-Event entsteht, können wir leicht in einer Endlosschleife landen.
Ein einfacher Weg, dies zu vermeiden, ist eine global eindeutige Transaktions-Id, die zum Beginn einer jeden Nutzer-Interaktion mit einem System erzeugt wird und mit jedem ausgehenden Event mitgeschickt wird.
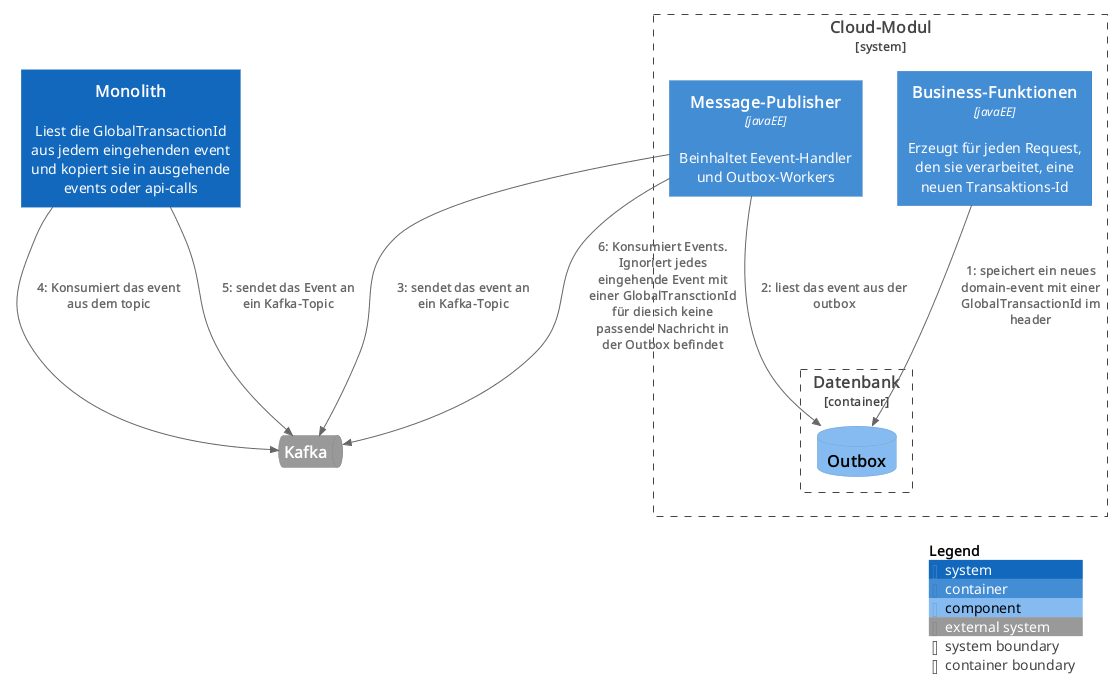
Im konkreten Beispiel erzeugt das Cloud-Modul zu Beginn einer Nutzer-Anforderung eine neue Transaktions-Id. Wird aufgrund dieser Interaktion ein Business-Objekt geändert, wird ein Domain-Event zunächst in der Outbox-Tabelle gespeichert und anschließend an Kafka gesendet. Das Event trägt die Transaktions-Id im Header.
Das Alt-System verarbeitet nun das Event und kopiert die Transaktions-Id in seinen Ausführungskontext, anstatt selbst eine Transaktions-Id anzulegen. Ist die vom Event getriggerte Aktion durchgeführt, wird wieder ein Domain-Event erzeugt, wieder mit der Transaktions-Id im Header.
Wird nun das Event im Neusystem verarbeitet, wird zunächst die Transaktions-Id aus dem Header gegen die eigene Outbox-Tabelle geprüft. Dabei wird festgestellt, dass die Transaktions-Id bereits in diesem System bekannt ist, es sich also um einen Zyklus handeln muss. Das Event wird verworfen.
Von Nachteil ist, dass sowohl das Alt- als auch das Neusystem in der Lage sein müssen, Transaktions-Ids zu erzeugen und entsprechend zu behandeln. In unserem Falle hätte es einen massiven Eingriff in das Altsystem bedeutet, das zu ermöglichen, weshalb der Ansatz etwas abgewandelt wurde. Statt einer global gültigen Transaktions-Id wurde auf einen Operations-Key zurückgegriffen, der jede Business-Operation eindeutig identifiziert und im Altsystem bereits zu Audit- und Loggingzwecken eingesetzt wurde:
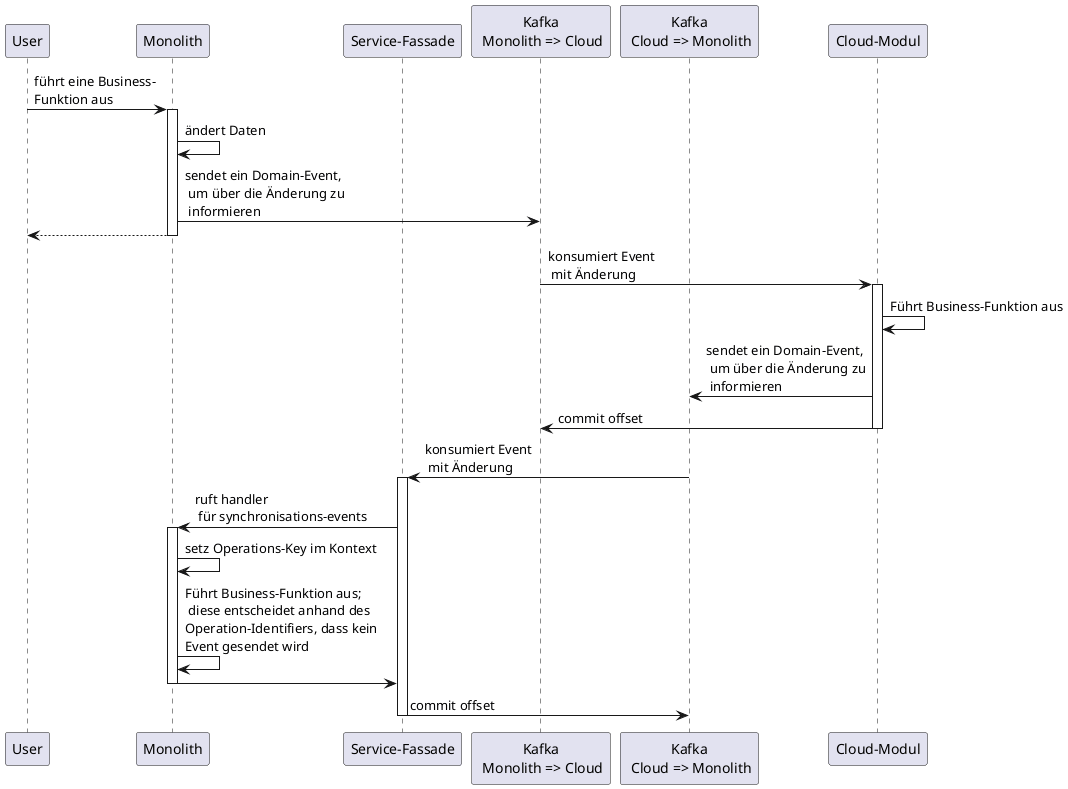
Die Verantwortung für das Vermeiden von Zyklen liegt hier allein beim Altsystem: Es wird sichergestellt, dass bei Aktionen, die als Reaktion auf ein Domain-Event ausgeführt werden, ein anderer Operations-Key gesetzt ist als bei Operationen, die durch eine Nutzerinteraktion angestoßen werden. Bevor ein Event in die Outbox-Tabelle geschrieben wird, wird nun immer anhand des Operations-Keys geprüft, ob es sich um eine neue Interaktion oder eine Reaktion auf ein Event handelt. Für Reaktionen auf ein Event wird kein neues Event in die Outbox geschrieben.
Fazit
Die Arbeit an dem Projekt hat noch einmal vor Augen geführt, dass die Synchronisation zweier Systeme, die dieselben Daten ändern, herausfordernd sein kann. Zur Vermeidung von Konflikten durch paralleles Arbeiten müssen Kompromisse eingegangen werden. Ansätze mit Pessimistic Locking bieten einen guten Schutz vor Konflikten, können aber die Akzeptanz der Anwender schmälern. Ansätze mit Optimistic Locking verringern die Auswirkung gesperrter Objekte, stellen die Konsistenz allerdings nur verzögert sicher. Diesen Nachteilen wurde im Projekt begegnet, indem das neue System schrittweise für einzelne Standorte ausgerollt wurde. Aufgrund der getrennten Zuständigkeiten der einzelnen Standorte war die Notwendigkeit für gleichzeitige Änderungen an denselben Datenobjekten in beiden Systemen gering.
Das Projekt zeigt, dass es bei der Synchronisation von Alt- und Neusystemen selten eine universell richtige Lösung gibt. Vielmehr hängt die Wahl des geeigneten Ansatzes von den fachlichen Anforderungen, den technischen Randbedingungen und dem gewünschten Nutzererlebnis ab.


