

Ansible AWX is a great product. Recent change to k8s architecture had some significant complexity implications, but i was really hit hard once finding out, that no job template could run longer than 4 hours without running into a generic failure. Here I would like to describe how to workaround this problem until the issue is finally fixed.
Problem cause
The problem as usually lies between 3rd party layers, that changing to k8s stack has had to include. What is the worst with this is – no side felt responsible for dealing with it and therefore there were several issues opened for so many diverse projects, and apparently none of them (well except for one, but this is very fresh) got solved. Here some of them:
- https://github.com/ansible/awx/issues/11805 – opened 2022-02-24 – main ticket
- https://github.com/ansible/awx/issues/11594 – predecessor, opened 1 month earlier and closed without resolution…
- https://github.com/ansible/awx-operator/issues/622 – AWX Operator issue, opened even earlier, Oct 2021, closed recently as duplicate to main ticket
- https://github.com/containerd/cri/issues/1057 – issue for CRI, closed but main problem seems still present
- https://github.com/ansible/awx/issues/11338 – same cause…
- https://github.com/k3s-io/k3s/issues/1936 – this time issue for k3s
Just to summarize the problem – when AWX launches a Job Template, it fires a dedicated k8s pod to perform the job. It attaches to the pod and catches stdout output in order to be able to streeam events in quasi realtime, so that you (or anyone else) can track the progress on AWX console web page. The problem is when this pod runs longer than exactly 4 hours. As i have been able to find out the 4h limit got indeed hardcoded in kubelet. It affects the maximum runtime of a HTTP session attaching to a k8s pod. After this timeout, the connection that fetched job output will be just torn down no matter what.
And the problem with AWX was – there seemed to be no mechanism implemented to re-connect to the running pod. Instead, there was added a reaper task, that just terminated pods that got out of control and the Job Template after getting disconnected from the automation pod running ansible-playbook got set to Failed state. Implementing this mechanism is not a trivial thing, considering the way pods are pooled, dispatched and managed by AWX itself. The 4h limit enforcement by kubelet seems appropriate due to security concerns (so that no one can stay attached to the console of a running pod forever). The fix is therefore needed on AWX side. Before we get to the permanent fix, I would like to present a workaround that might be used to overcome the limitation.
Workaround with Workflow Job Templates
As a single Job Template has not to exceed 4 hours of runtime, one might think of cutting a long running AWX Job into smaller ones, and execute them in sequence one after another by using Workflow Job Template. Cool thing is, that Workflow Job Templates are not affected by the limit, as they do not launch dedicated k8s pods. Only Job Templates do.
Cutting single Job Template into fragments
You do not need to write multiple playbook files and define multiple Job Templates to achieve this. By using tags you can run a Job Template in a selective way, executing just some of its tasks. This is exactly what we will do here. Let us consider this sample playbook, that will hit the 4h problem:
--- - hosts: localhost name: Test 4h failure tasks: - name: task executing 2 hours ansible.builtin.pause: minutes: 120 - name: task executing 2 hours ansible.builtin.pause: minutes: 120 - name: task executing 2 hours ansible.builtin.pause: minutes: 120
---
- hosts: localhost
name: Test 4h failure
tasks:
- name: task executing 2 hours
tags: stage1
ansible.builtin.pause:
minutes: 120
- name: task executing 2 hours
tags: stage2
ansible.builtin.pause:
minutes: 120
- name: task executing 2 hours
tags: stage3
ansible.builtin.pause:
minutes: 120
Then configure the Job Template, so that tags will be prompted on Launch:
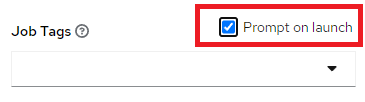 Then, define a workflow template that executes the same Job Template 3 times, but for each run use different tag – first with stage1, then stage2 and last one – stage3.
Then, define a workflow template that executes the same Job Template 3 times, but for each run use different tag – first with stage1, then stage2 and last one – stage3.
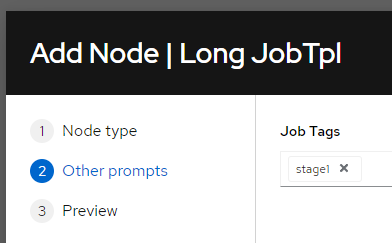

Running this Workflow template will effectively execute all those tasks, with total runtime exceeding 4 hours without any problem!
Single long running Task
The solution given above Solves some of the problems, but will not allow a single Ansible task to run over 4 hours. But there is a solution for that as well, by using Ansynchronous tasks and the ansible.builtin.async_status Ansible module.
Define the tasks like that:
- name: Start task running longer than 4h
ansible.builtin.shell:
cmd: sleep 5h
async: 86400 # 24h hard timeout value, not needed but recommended
poll: 0 # do not poll by the task, we will poll status with following task
register: long_task
tags: stage1
- name: Wait for task up to 3h
ansible.builtin.async_status:
jid: "{{ long_task.ansible_job_id }}"
register: long_task_result
until: long_task_result.finished
delay: 600 # re-check every 10 minutes
retries: 18 # total 3h waiting time (18 * 10 minutes)
failed_when: false # do not fail if not finished in 3h
tags: stage1
- name: Store long_task Artifacts for later step
ansible.builtin.set_stats:
data:
long_task: "{{ long_task }}"
long_task_result: "{{ long_task_result }}"
aggregate: false
tags: stage1
- name: Wait for task ANOTHER 3h in next Job Template
ansible.builtin.async_status:
jid: "{{ long_task.ansible_job_id }}"
register: long_task_result2
# should the task finish in first wait round skip this one:
when: not long_task_result.finished
until: long_task_result2.finished
delay: 600 # re-check every 10 minutes
retries: 18 # total 3h waiting time (18 * 10 minutes)
tags: stage2
This may seem a bit complex, but most important thing is pool: 0 and async: true which starts the Task kind of in background without waiting for it to finish. It is also important to capture the result od this task, as it has a job-id that allows async_status module to query the job progress. Ansible immediately proceeds to the next task. Next task uses the already mentioned async_status task which needs a job-id to check. Once the job finishes, its full output will be reported as a result od this check-task. So if the sleep command would produce any stdout, it would be in long_task_result, not long_task. long_task will not be updated once fired.
Now as the task itself is running longer than 3 hours, first round of of wait commands will typically not be sufficient. Next wait attempts for this job to finish need to be done in separate Job Template (separate step of Workflow Job Template). In order to be able to use async_status module you however need to get the job-id.
Now this is really important – each step is to be considered as an individual playbook run, cut to the tasks that are having proper tag set. So therefore it konws nothing about variables like long_task!!! You will have to use the set_stats module to produce Artefacts, that will be passed to next Workflow Job as input external variables. This is exactly the purpose of passing those 2 variables. First one gives the job-id for async_status to check on.
Now the small problem here is, that once async_status finds out the job ended, it REMOVES all job progress data from system. Another execution of async_status with the same jid will therefore fail. In order to overcome this, we also pass the last value of long_task_result to next step and use when condition not to execute the module at all once it has really finished. This will override long_task_result so if you care about the original job output, then you should consider using other variable for capturing the output, as we did here with long_task_result2.
Now the job will for sure finish here within next 3h, and the overall Workflow will be finished successfully
Skip known wait duration
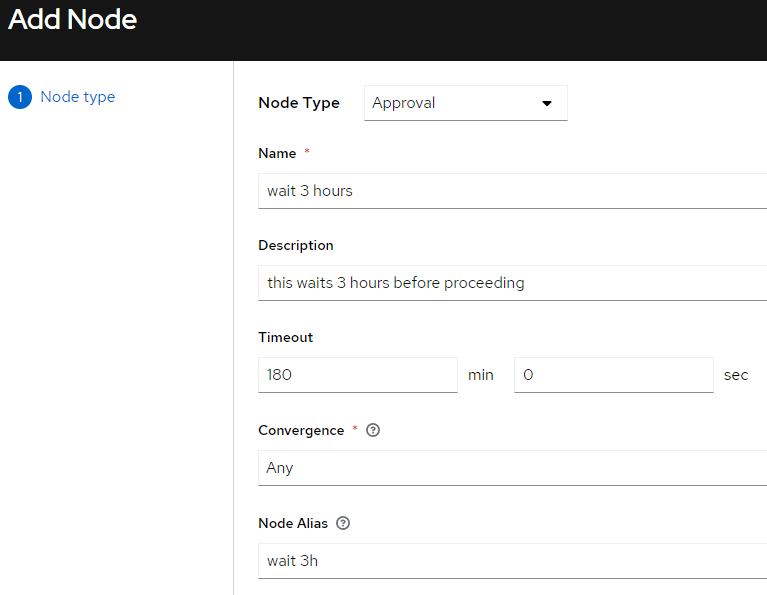
Final solution
It seems that just recently there are some developments and maybe the really long present issue will finally come to an end. See the linked main Issue for progress reports. If you hovewer for any reason possible cannot update to current version that might have the issue permanently fixed, I hope this article will help you to overcome this problem in another way. You may also consider this way of passing variables between steps interesting. Thanks if you got till this point, as this got a pretty long one…



1 Kommentar
Fixed in https://github.com/ansible/receptor/pull/683
for more information please refer to the PR description