

In diesem Artikel geht es um die Erstellung eines hochverfügbaren Internet Proxy in der Cloud, der die Zugriffe von Applikationsservern auf das Internet beschränken soll. Insbesondere wird auf die Hochverfügbarkeitsproblematik eingegangen, die sich aus der Anforderung „Client Based Filtering“ ergibt. Auf die konventionelle Squid Installation und Konfiguration wird an der Stelle nicht eingegangen, da diese nach Standard erfolgten. Ebenso nicht auf die Erstellung sämlicher Standard OCI-Komponenten.
Motivation
Um Hochverfügbarkeit von Applikationen zu erreichen, stellt Oracle in der OCI einen Loadbalancer (LB) zur Verfügung, welcher über konfigurierbare „Listener“ verfügt und mit verschiedenen Shapes auch Leistungsparameter variieren kann. Dennoch sind diese Loadbalancer nicht für alle Einsatzfälle gleichermaßen gut geeignet. Auch in unserem Anwendungsfall stellte sich dies als schwierig dar, wie im Bild dargestellt.
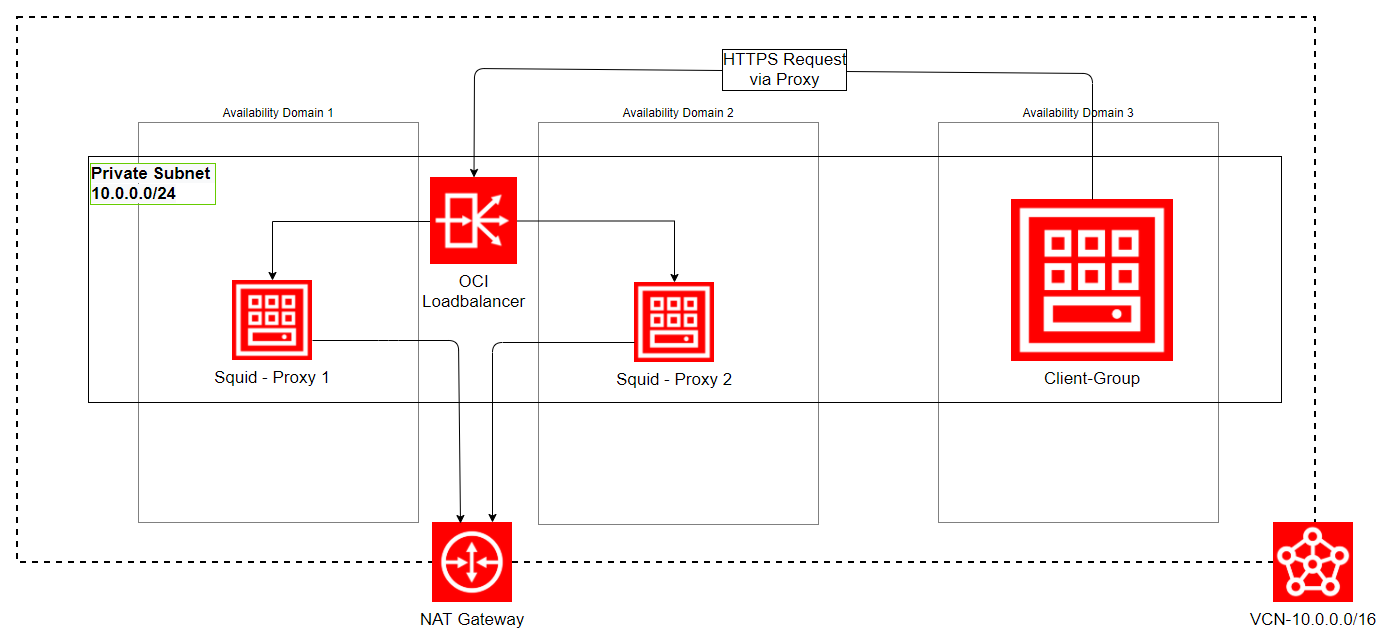
In unserem Projekt stellte sich heraus, dass die Anforderung, Quell-Hosts basierende Security Rules im HA-Squid zu implementieren, mit dem OCI-Loadbalancer ( Stand: 11/2020 ) nicht umsetzbar war. Der Grund war, dass dieser zwar eingehend HTTP- und TCP-basierende Verbindungen zulässt, nicht aber HTTPs. Der Versuch mit TCP/443 zu arbeiten scheiterte daran, dass der LB im TCP-Modus zwei Connections aufbaut, eingangsseitig mit dem Client und ausgangsseitig mit dem Backend (Squid) . Dabei geht die ursprüngliche Quell-Host-Information (also die IP-Adresse des Client Hosts) verloren und der Squid-Proxy bekommt die IP des Loadbalancers als Quelle übermittelt. Somit war eine hochverfügbare „Client Based Filtering“-Lösung mit Squid Proxy und dem OCI Loadbalancer nicht möglich. Eine andere Lösung musste gefunden werden.
Alternativ wären ein F5 Loadbalancer oder ähnliche kommerzielle Produkte einsetzbar gewesen, welche jedoch zum einen meist mit höheren Lizenzkosten verbunden sind, und zum anderen unter Umständen einfach zu mächtig sind und die Komplexität im Gesamt Projekt unnötig erhöhen, wenn es darum geht einfache Anwendungen hochverfügbar zu machen.
Unser Ansatz war eine „Self-Made“-Cluster-Lösung mit zwei Nodes in einer „Active/Passive“-Variante.
Nachfolgend stelle ich ein Szenario vor, bei dem wir einen HA-Internet-Proxy in Rahmen eines größeren Migrationsprojekts verwendet haben und die folgenden Ziele verfolgten:
- die Limitierung des OCI Loadbalancer ausgleichen
- die Standard-Konfiguration des „Squid“ auf einer simplen HA-Storage-Lösung
- kein Loadbalancing, aber Hochverfügbarkeit durch Implementierung eines Active/Passive-Verhaltens
- Verwendung des Oracle Linux Software Stack, unter Einbeziehung der in OCI verfügbaren OS Base Images
- IaC-Anwendung auf der Plattform einer Oracle Cloud Infrastructure
Mit welchen Konzept und welchen Komponenten haben wir diese Ziele erreicht? Da gibt es sicher nicht den Golden Weg. Wir sahen die besten Chancen in der Verwendung populärer und von RedHat und Oracle unterstützter Komponenten. Dabei kam folgendes Konzept heraus:
Konzept Squid HA mit Pacemaker/Corosync in OCI
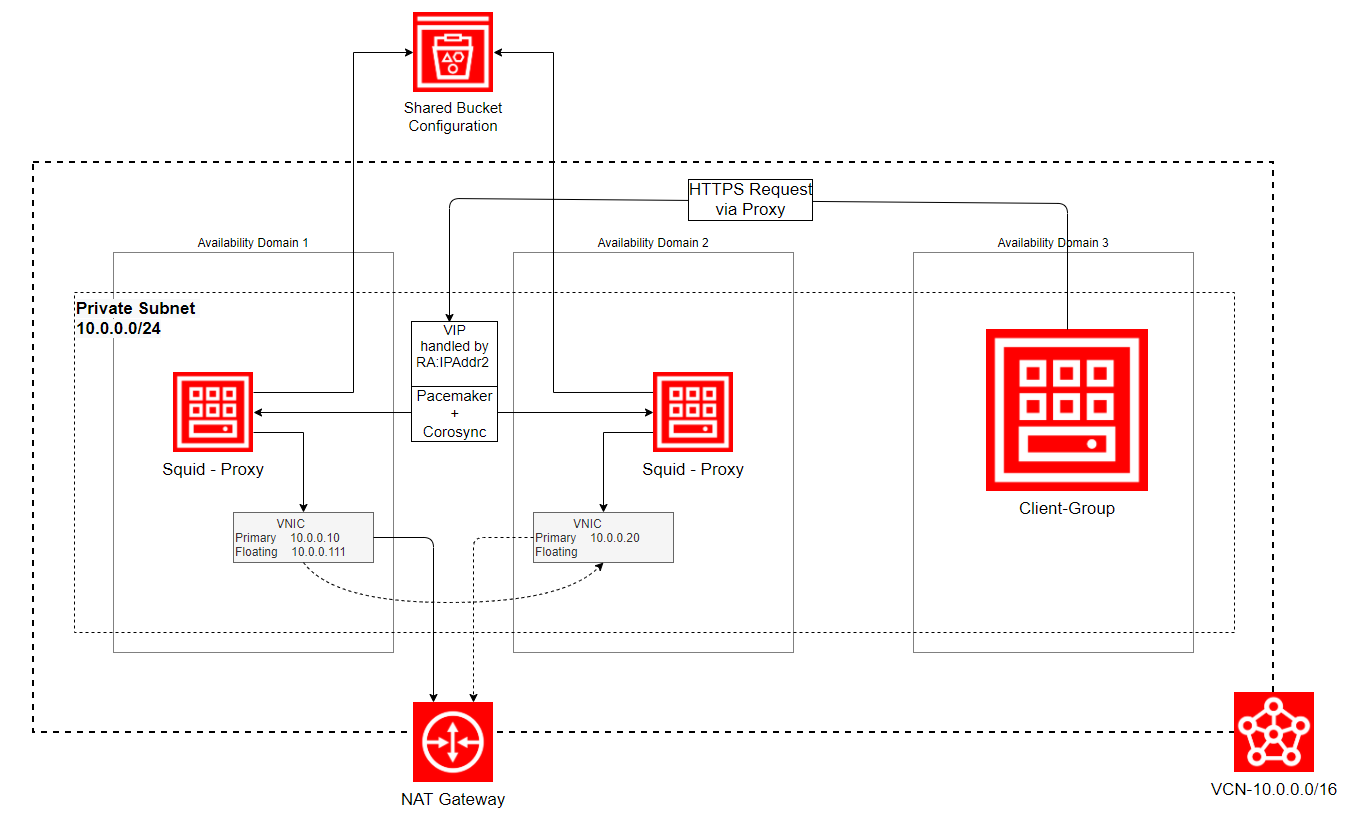
Auf beiden Nodes läuft Pacemaker als Resource Manager im Duo mit Corosync. Zwei Resource-Agenten sorgen dafür, dass die Virtuelle IP (RA:Heartbeat:IPAddr2) nd Squid (Heartbeat:Squid) stets auf einem Node aktive sind (Active/Passive-Verhalten). Die Squid-Konfiguration liegt auf einem via „s3fs-fuse gemounteten“ Shared Bucket (Object Storage), sodass beide Instanzen exakt die gleiche Konfiguration verwenden. Hier wäre auch DRBD mit einfachen Blockvolume Devices denkbar, aber das würde einen höheren Verwaltungsaufwand mit sich bringen, wie z. B. ein „Splitt-Brain“-Handling.
Pacemaker/Heartbeat /Corosync
Diese Software-Komponenten sind für Resource Management (Pacemaker) und Membership Management (corosync) zuständig. Ab RHEL 7 ist Pacemaker der Standard Cluster Resource Manager bei Red Hat und zusammen mit Corosync aktuell der „De-Facto“-Standard für das Management von Resource und Membership Layer, insbesondere in RHEL-basierten Systemen.
Squid
Squid ist eine sehr ausgreifte und stabile Proxy Server Software, die normalerweise mittels Systemd Service implementiert ist, hier aber durch einen Resource Agent auf beiden Squid-Nodes gesteuert wird. Die Konfigurationdateien für den Squid sollten nur einmal vorhanden sein und auf einem S3 Bucket (Object Storage) vom jeweils aktiven Node eingelesen werden (Aktiv/Passive-Konzept). Erhöhte Sicherheit des Proxy wird durch ein „WhiteListing“ ausgehender Aufrufe und zusätzlicher Quell-Host-Restriktion erreicht. Für letztere wird die „x-forwarded-for“-Eigenschaft von Squid verwendet. So wird der Traffic zu den white-gelisteten Targets zusätzlich stringiert. Das war Ausgangspunkt für dieses Teilprojekt und eines der Hauptziele.
S3FS-Fuse
S3FS-Fuse ist das Mittel der Wahl, um S3-kompatible Storages in Filesysteme einzubinden. Die OCI Object Storages sind S3-kompatibel und hochverfügbar ausgelegt. Sie sind für einfachere Aufgaben, wie in diesem Fall als Shared Storage für die Squid Konfiguration Files (Squid im Active/Passive Mode) gut geeignet und parallel an beiden Nodes „gemountet“.
Umsetzung
Die beiden Compute Nodes und die gesamte OCI-spezifische Infrastruktur wird mit Terragrunt/Terraform als Teil eines größeren Projekts erstellt. Zu beachten ist dabei, dass einer der Nodes eine zusätzliche Private IP bekommt, welche dann als VIP, also als Floating IP, fungiert. Auf die Besonderheit, die sich daraus für den Failover Fall in der OCI ergibt, wird später noch im Detail eingegangen. Das Provisionieren erfolgt über OCI-Metadaten, welche neben dem „cloud-init“-Skript zum Provisionieren auch weitere encrypted Informationen enthalten (Secrets).
Spezielle OCI-Komponenten
Für das Funktionieren der später beschriebenen VIP-Failover-Funktion, werden „Dynamic Groups“ mit entsprechenden Policys benötigt, um das OCI feature „Instance Principal“ verwenden zu können. Im Prinzip ermöglicht dies, dass sich die Compute Instances selbst modifizieren. Durch gezielte Policys wird diese Fähigkeit auf die Relokation der VIP und durch eine „Matching Rule“ der „Dynamic-Group“ auf ganz bestimmte Compute-Instanzen beschränkt. Eine Dynamic Group und zugehörige Policy könnte in Terragrunt/Terraform wie folgt aussehen:
dynamic_groups = [
{name = "Cluster", description = "Dynamic groups to give OCI access to relocate network interfaces between cluster members", matching_rule = " tag.value='SQUID'"}
]
policy_ha = {name = "SQUID-HA", description = "Policy for Clusters managing floating-ips", statements = [
"Allow dynamic-group Cluster to manage private-ips in compartment XYZ",
"Allow dynamic-group Cluster to use vnic in compartment XYZ",
"Allow dynamic-group Cluster to read compute-management-family in compartment XYZ"
]},
Erforderliche Linux Pakete für alle Software-Komponenten
Neben den Paketen für Pacemaker gibt es von RedHat ein CLI namens „pcs“ , welches den Zugriff auf die Pacemaker-Konfiguration über einen „pcsd daemon“ (Systemd Service) ermöglicht. Für „Fencing“ werden entsprechende „fence-agents“ installiert, sofern auf Fencing zurückgegriffen werden muss. Formal sollte darauf geachtet werden, dass auch „net-tools“ und „jq“ installiert sind, die das Framework implizit benötigt bzw. welche für die Cloud Metadaten-Auswertung gebraucht werden .
$yum -y installpython-oci-sdk python-oci-clinet-tools jq s3fs-fuse corosync pcs pacemaker fence-agents-all squidLoaded plugins: langpacks, ulninfoPackage net-tools-2.0-0.25.20131004git.el7.x86_64 already installed and latest versionPackage jq-1.5-1.0.1.el7.x86_64 already installed and latest versionPackage s3fs-fuse-1.86-2.el7.x86_64 already installed and latest versionPackage corosync-2.4.5-7.el7.x86_64 already installed and latest versionPackage pcs-0.9.169-3.0.1.el7.x86_64 already installed and latest versionPackage pacemaker-1.1.23-1.0.1.el7.x86_64 already installed and latest versionPackage fence-agents-all-4.2.1-41.el7_9.2.x86_64 already installed and latest versionPackage 7:squid-3.5.20-17.el7_9.5.x86_64 already installed and latest versionNothing to do
OCI-Object-Storage-(Bucket)-Konfiguration
Das Paket für „s3fs-fuse“ ist bereits installiert und kann nun das zuvor mittels Terragrunt/Terragrunt erzeugte Bucket über einen „/etc/fstab“-Eintrag auf beiden Nodes wie folgt an den Mount Point „/data“ mounten:
(Fett gedruckte x stehen für Zeilennummern und setzen die Kenntnis
der Struktur der übertragenen Daten voraus.)
# Extract secrets from OCI Metadata (s3fs password)$ sudo /bin/curl -s http://169.254.169.254/opc/v1/instance/ | jq -j .metadata.secret_key| base64 -d | sed -n xp > /usr/local/etc/.passwd-s3fs$ sudo sed -i "\$a Proxy /data fuse.s3fs use_xattr,_netdev,allow_other,passwd_file=/usr/local/etc/.passwd-s3fs,url=https://.compat.objectstorage.eu-frankfurt-1.oraclecloud.com/,nomultipart,use_path_request_style,context="system_u:object_r:squid_conf_t:s0" 0 0" /etc/fstab
$ sudo mount -aDabei werden die Credentials des Cloud Users im Password File übergeben und auch der Squid SELinux Context, der für den Mount Point benötigt wird. Die URL verweist auf den Object Storage und muss natürlich durch den konkreten Identifier ersetzt werden. Ist das Bucket auf beiden Nodes gemountet, kann die komplette Squid-Konfiguration, nachdem sie auf dem ersten Node vorverarbeitet wurde (Erzeugen der Whitelists etc.), auf das Bucket kopiert werden. Der entsprechende Verweis in der „squid sysconfig“ wird ebenfalls auf das Bucket „umgebogen“.
$cp -pr /etc/squid/ /data/squid_config/$sed -i "s/\/etc\/squid\//\/data\/squid_config\//g" /etc/sysconfig/squid
Pacemaker und Resource-Agents-Konfiguration
Die Cluster Installation/Konfiguration erfolgte „straight forward“ und kann u. a. auch bei clusterlabs.org oder bei Oracle im Detail nachgelesen werden. Dieser Teil ist eigentlich nicht sonderlich spannend. Interessant wird er, wenn man sich die Aufgabe stellt, die Installation und Konfiguration völlig „unattended“ zu gestalten, also ohne manuelle Eingriffe.
Hier der grundsätzliche Vorgang als Pseudo Script:
(Fett gedruckte x stehen für Zeilennummern und setzen die Kenntnis
der Struktur der übertragenen Daten voraus.)
# Zunächst den pcs service auf beiden Hosts starten
$ sudo systemctl enable pcsd
$ sudo systemctl start pcsd
# und dann das password für den Default Cluster user "hacluster" setzen
# Extract secrets from OCI Metadata (hacluster password
Bis hierher erfolgten alle Aktionen auf beiden Cluster Nodes.
Das Paket für den Pacemaker wurde ja bereits installiert und damit auch die benötigten Resource Agents für den Cluster. Somit können wir jetzt den Cluster und die Agents nacheinander konfigurieren.
$ sudo /sbin/pcs cluster auth NODE1 NODE2 -u hacluster -p $HAPASSWD sudo /sbin/pcs cluster setup --start --name proxy_cluster squid1 squid2 # cluster start right now and after reboot $ sudo /sbin/pcs cluster start --all $ sudo /sbin/pcs cluster enable --all # properties: without STONITH, No quorum policy in 2 node cluster, and resource stickyness (no automatic failback) $ sudo /sbin/pcs property set stonith-enabled=false $ sudo /sbin/pcs property set no-quorum-policy=ignore $ sudo /sbin/pcs resource defaults resource-stickiness=100 #Virtual "floating-ip" service$ sudo pcs resource create floating-ip IPaddr2 ip=10.0.0.111 cidr_netmask=24 op monitor interval=15 meta target-role="Started"#Adding virtual "ha-squid" service using ocf-resource and bind it together with the floating-ip service to a resource group$sudo /sbin/pcs resource create ha-squid ocf:heartbeat:Squid squid_exe="/usr/sbin/squid"squid_conf="/data/squid_config/squid.conf"squid_pidfile="/var/run/squid.pid"squid_port="3128"squid_stop_timeout="30"op start interval="0"timeout="60s"op stop interval="0"timeout="120s"op monitor interval="15s"timeout="30s"meta target-role="Started"$ sudo /sbin/pcs resource group add SquidAndIP floating-ip ha-squid$ sudo /sbin/pcs resource meta SquidAndIP target-role="Started"
Damit wäre die grundlegende Cluster-Funktionalität gegeben. Auch ein Failover scheint „out-of-the-box“ zu funktionieren, zumindest suggeriert uns Linux auf beiden Hosts, dass die virtuelle IP 10.0.0.111 zwischen den Knoten und deren Primary Interfaces wechselt. Leider reicht das in der OCI Cloud nicht aus, weil die IP dort nicht erreichbar ist. Für die Erreichbarkeit der Instanz über die VIP muss das private_ip object, welches dem Primary Network Interface der Compute Instance zugewiesen wurde, ebenfalls auf die jeweils andere zugewiesen werden.
Konfiguration der VIP-Failover-Funktion in OCI
Um der Cloud-Architektur Rechnung zu tragen, waren einige Besonderheiten zu beachten. In diesem Teil beschreibe ich, was zu tun ist, um die Private IP wirklich „floaten“ zu lassen. im Abschnitt „Spezielle OCI-Komponenten“ erwähnte ich bereits, dass einer der Knoten („sagen wir squid1“) initial mit einem „Private IP Object“ ausgestattet werden muss. Diese Private IP ist mit 10.0.0.111 assoziert und an das Primary Interface gebunden. Beim Failover macht Linux wie bereits erwähnt schon alles richtig, dafür sorgt der IPAddr2 Agent von Heartbeat. Aber das Cloud Object bekommt davon nichts mit. Um dies zu ändern, ist eine spezielle Aktion mittels OCI Command Line Interface erforderlich, das dafür auf beiden Cluster Nodes eingerichtet sein muss. Weitere Pre-Requisites sind „dynamic_groups“ und „policies“, wie bereits beschrieben.
Die Kerngedanken dabei sind folgende:
- Der RA IPAddr2 wird so manipuliert, dass er zusätzlich auch die OCI IP umschaltet. Dafür implementiert man ihm ein „Floating Script“ in die „add_interface function“.
- Das „Floating Script“ nutzt via gesetzter Enviroment-Variable dann „Instance Principal“
- und kann via oci command die VIP an Ihren eigenen VNIC binden
Die dazu gehörenden Code-Snippets sehen wie folgt aus:
/bin/sed -i "/add_interface ()/a /bin/float_ip" /usr/lib/ocf/resource.d/heartbeat/IPaddr2
export LC_ALL=C.UTF-8 export LANG=C.UTF-8 export OCI_CLI_AUTH=instance_principal
vnicid=`/bin/curl -s http://169.254.169.254/opc/v1/vnics/ | /bin/jq -j .[].vnicId` /bin/oci network vnic assign-private-ip --unassign-if-already-assigned --vnic-id $vnicid --ip-address 10.0.0.111
Fazit
Das Ziel, eine relativ einfache Lösung als Alternative zum OCI Loadbalancer bzgl. dessen Limitierung der Quell Host Information zu erstellen, ist uns gelungen. Bewusst in Kauf genommen haben wir dabei, dass es mit der neuen Lösung kein Loadbalancing gibt, das war aber bereits in der Ausganglösung nachrangig gegenüber der Verfügbarkeit.
Trotz der Einfachheit der vorgestellten HA-Lösung eines Internet Proxy mit Pacemaker und Squid , waren dennoch eine Menge kleinerer Hürden zu bewältigen. Diese waren unter anderem
- der Umgebung (Oracle Cloud Infrastructure mit Object-Storage )
- den favorisierten Software-Komponenten (Squid + Pacemaker + s3fs)
- und „last but not least“ den Sicherheitsansprüchen (Authentifizierung) im Zusammenhang mit „Instance Principals“ und „s3fs“
geschuldet.
Aber genau diese sind es auch, die diesen Teil des Cloud-Migrationsprojekts interessant für weitere Anwendungen in der Cloud machen.
Die Lösung kann selbstverständlich auch als Basis für komplexere HA-Anforderungen dienen. Denkbar scheint auch die Anwendung in Bereichen, in denen Standard Loadbalancer nicht über die gewünschten Protokolle wie sftp verfügen. Desweiteren würde man ggf. auch Local Block Storage mittels DRBD Master/Slave Set in den Pacemaker einbinden und somit eine kostengünstige, aber immer noch einfache Lösung mit hochverfügbarem Storage für die Daten erhalten.


