

Einleitung
Einer der vielen Use-Cases von Machine Learning (ML), der eine hohe Nachfrage in der heutigen Wirtschaft aufweist, ist die Fähigkeit Geschäftszahlen vorherzusagen. Hierzu werden Regressionsalgorithmen verwendet, um unter anderem Produktpreise, Konsumverhalten oder Immobilienpreise vorherzusagen.
Um einen konkreten Use-Case darzustellen, haben wir ein eigenes Regressions-Modell in AWS SageMaker trainiert und evaluiert. Hierfür haben wir den Datensatz „Boston Housing Prices“ zum Trainieren unseres Modells verwendet. Der Datensatz wird dafür benutzt, um die Immobilienpreise im präsenten Markt anhand von 13 verschiedenen Faktoren vorherzusagen.
Unser Vorgehen und mehr Details über den Datensatz, erfahren Sie in den nächsten Abschnitten dieses Blogposts. Falls Sie allgemein mehr über SageMaker erfahren möchten, können Sie gerne den ersten Blogpost zu dieser Reihe konsultieren.
Beschreibung des Datensatzes
Die Basis für unser Modell ist der Datensatz „Boston Housing Prices“. Dieser enthält 503 eindeutige Werte. Jeder Wert hat 13 Attribute, wie z.B. die Kriminalitätsrate, Luftqualität und Anzahl der Zimmer. Der Datensatz kann über Keras heruntergeladen werden und erleichtert für Machine Learning Anfängern den Einstieg. Das hat den Vorteil, dass die Datenqualität, ohne Preprocessing, für das Training ausreichend ist und man den Fokus auf das ML setzen kann, anstatt auf das Preprocessing.
Preprocessing
Da der Datensatz bereits von Keras, mit einer hohen Qualität, zur Verfügung gestellt wird, ist wenig Preprocessing notwendig, jedoch kann man die Zahlen normalisieren, um das Trainingsprozess zu optimieren. Normalisierung ist eine Technik, die oft als Teil der Datenvorbereitung für ML angewendet wird. Das Ziel der Normalisierung besteht darin, die Werte numerischer Spalten im Datensatz so zu ändern, dass eine gemeinsame Skala verwendet wird, ohne Unterschiede in den Wertebereichen zu verzerren oder Informationen zu verlieren. Die Normalisierung ist auch für einige Algorithmen erforderlich, um die Daten korrekt zu modellieren. Wir benutzen einen `scikitlearn` Container, der von SageMaker angeboten wird, um deren `StandardScaler` zu benutzen, um die Werte zu normalisieren. Es wird ein ‚preprocessing‘ Skript geschrieben und zusammen mit den Daten an eine SageMaker Instanz geschickt. Das Script benutzt die Rechenleistung der Instanz, um das Processing durchzuführen.
In unserem Fall werden die Daten auf zwei Instanzen aufgeteilt. Aufgrund der kleinen Größe des Datensatzes wäre dies eigentlich nicht nötig, aber es demonstriert, wie man einen großen Datensatz auf mehrere Instanzen verteilen könnte, um Zeit zu sparen. Bei n Instanzen bekommt jede Instanz 1/n der Trainingsdaten.
Training
Im Training Skript wird ein Modell mit Tensorflow’s High Level API Keras gebaut. AWS SageMaker bietet einen vorgefertigten Container an, indem Tensorflow eingerichtet ist. Dieser Container ermöglicht es dem Entwickler, Skripte, die ähnlich zu denen sind, die auch außerhalb von SageMaker benutzt werden, auszuführen. Dieses Feature von AWS heißt „Script Mode“ und gibt dem Entwickler die Möglichkeit einen Workflow für ein Tensorflow Projekt zu erstellen.
Das eigentliche Training findet auf einer leistungsfähigen Instanz von SageMaker statt. Diese Instanz wird durch das Trainingsscript im „Script Mode“ hochgefahren und aufgerufen.
Um das Modell zu verbessern kann man normalerweise das „Hyperparameter tuning“ durchführen, bei dem verschiedene Werte ausprobiert werden, um die Auswirkungen auf das Modell zu sehen. Das ist aber ein zeitaufwendiges Verfahren, wenn man es manuell macht. Mit SageMaker können wir diesen Prozess automatisieren. Wir geben an, welche Parameter getuned werden sollen und welchen Wertebereich sie annehmen können. Dann kann man auf mehrere Instanzen parallel trainieren und die besten Ergebnisse leicht aussortieren.
Deployment
Das aus dem Hyperparameter tuning entstandene Modell kann einfach mit einem Befehl auf einen Endpoint in AWS bereitgestellt werden, indem man noch zusätzlich den Typ der Instanz und die maximale Anzahl an Instanzen angibt. Dann können Requests mit Test-Daten an den Endpoint geschickt werden. Diese liefern die Vorhersagen des Modells, die wir benutzen, um es zu evaluieren.
Ergebnisse
Um das Modell zu evaluieren haben wurden 102 Test-Fälle an den Endpoint geschickt. Als Ergebnis hat das Modell die Preise für die Immobilien vorhergesagt.
In der folgenden Abbildung sind 10 Beispiele für die tatsächlichen Werte (untere Zeile) und für die von unserem Modell vorhergesagten Werte (obere Zeile) zu sehen:

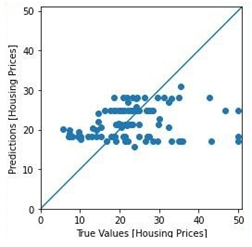
Die meisten Werte konnten relativ genau vorhergesagt werden. Die folgende Grafik stellt eine Visualisierung des Ergebnisses da. Die Y-Achse zeigt die Werte der Vorhersage des Modells an und die X-Achse zeigt die wahren Werte des Datensatzes an. Dementsprechend stellt die Winkelhalbierende alle richtigen Vorhersagen dar. Das heißt, je näher eine Vorhersage an der Winkelhalbierenden ist, desto genauer ist es.es.
Bewertung von SageMaker und AutoML
SageMaker hat den Vorteil, dass eine Vielzahlt an ML-Frameworks unterstützt werden. Die gängisten Frameworks wie TensorFlow, Scikit-Learn werden unterstützt. Insgesamt sind es neun an der Anzahl. Außerdem bietet SageMaker schon implementierte Algorithmen an um ein Modell zu trainieren. Der Service von SageMaker selbst ist dabei kostenlos. AWS berechnet nur die Kosten für die genutzten Computing Ressourcen, welche sich laut Angaben von AWS mit Spot-Instanzen, um bis zu 90% senken lassen. Ein weiterer Vorteil ist, dass SageMaker auch eine Git-Integration hat. Nun zu dem AutoML-Service von SageMake. Die Performance des SageMakers überzeute uns, in jeden TestCase lieferte das Modell eine bessere Accuracy wie die von unserem entwickelten Modell. Außerdem besitzt der AutoML-Service eine hohe Flexibilität. Es besteht die Möglichkeit mit einem graphischen Interface diesem zu Bedienen oder sich Jupyter Notebooks zu generieren lassen wodurch eine hohe Transparenz und Anpassungsmöglichkeit besteht. Es muss dazu erwähnt werden, um Anpassungen an diesem Code vorzunehmen zu können benötigt es eine große Expertise in dem Umgang mit Sagemaker. Für alle trainierten Modell in der Amazon Cloud besteht die Möglichkeit über ein einfaches graphisches Interface einen Endpoint (EC2 Instanz) zur Verfügung zu stellen. Diese Instanz kann via eines Jupyter Notebooks und der API Boto3 in AWS Sagemaker erreicht werden oder über einen http-Post von extern.



1 Kommentar
Pingback: Klassifikation mit dem Autopiloten von Amazon Sagemaker | The Cattle Crew Blog